KNN(K-Nearest Neighbor) 실습
1. KNN?
- 지도 학습 알고리즘
- 현재 데이터를 특정값으로 분류하기 위해, 기존의 데이터 안에서 현재 데이터로부터 가까운 k개의 데이터를 찾아 k개의 레이블 중 가장 많이 분류된 값으로 현재의 데이터를 분류하는 알고리즘
- k: 몇 개의 이웃을 살펴볼 것인지 나타내는 변수
- NN: 현재 알고자하는 데이터로부터 근접한 데이터
2. 실습
- 이용 데이터: cirtus 데이터 셋
1. 필요 라이브러리 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns2. 데이터 준비
!wget https://raw.githubusercontent.com/devdio/datasets/main/citrus.csvcitrus = pd.read_csv('citrus.csv')
df = citrus.copy() # 원본 복제
df.head()
df.info()
df.describe()-> 데이터의 정보들을 파악
# 결측치(Missing Value)
df.isna().sum(axis=0)-> 결측치가 있는지 확인
# 타겟값(name) 개수 확인
df['name'].value_counts()3. 테스트 데이터 분리
- 일반적으로 8:2 분리
- 위에서부터 500개는 orange, 밑의 500개는 grapefruit이므로 데이터를 섞어줘야 한다.
df = df.sample(frac=1)
# 전체 섞기: frac=1- 타겟값 분리(입력.출력 분리)
-> y: 타겟값, X: 타겟 제외한 나머지 column명
y = df['name']
X = df[['diameter', 'weight', 'red', 'green', 'blue']]- 테스트 데이터 분리(슬라이싱 기능 이용)
idx = int(len(X) * 0.8) # 8000
X_train = X.iloc[:idx]
X_test = X.iloc[idx:]
y_train = y.iloc[:idx]
y_test = y.iloc[idx:]-> shape로 맞게 분리되었는지 확인
4. 전처리
- 스케일링(Z-score 정규화)
u = X_train['diameter'].mean() # 평균
std = X_train['diameter'].std() # 표준편차
X_train['diameter'] = (X_train['diameter']- u)/std
u_w = X_train['weight'].mean() # 평균
std_w = X_train['weight'].std() # 표준편차
X_train['weight'] = (X_train['weight']- u_w)/std_w
u_r = X_train['red'].mean() # 평균
std_r = X_train['red'].std() # 표준편차
X_train['red'] = (X_train['red']- u_r)/std_r
u_g = X_train['green'].mean() # 평균
std_g = X_train['green'].std() # 표준편차
X_train['green'] = (X_train['green']- u_g)/std_g
u_b = X_train['blue'].mean() # 평균
std_b = X_train['blue'].std() # 표준편차
X_train['blue'] = (X_train['blue']- u_b)/std_b
- 인코딩
# 문자 -> 숫자 인코딩
y_train = y_train.map({'grapefruit':0, 'orange':1}) # grapefruit는 0, orange는 1로5. 학습
- dataframd을 numpy로 바꿔주기
X_train = X_train.values
y_train = y_train.values
type(X_train), type(y_train)- 베이스 모델 학습
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier() # 객체 만들기, neighbors의 default = 5 <- 아무런 튜닝도 하지 않은 베이스 모델
clf = clf.fit(X_train, y_train) # 학습시키기6.평가
- X_test 전처리(스케일링)
X_test['diameter'] = (X_test['diameter']- u)/std
X_test['weight'] = (X_test['weight']- u_w)/std_w
X_test['red'] = (X_test['red']- u_r)/std_r
X_test['green'] = (X_test['green']- u_g)/std_g
X_test['blue'] = (X_test['blue']- u_b)/std_b- y_test 인코딩
y_test = y_test.map({'grapefruit':0, 'orange':1}) # grapefruit는 0, orange는 1로- numpy로 바꾸기
X_test = X_test.values
y_test = y_test.values- 예측
y_pred = clf.predict(X_test)- 정확도
np.sum(y_test == y_pred) / len(y_test)- 오차행렬
from sklearn.metrics import confusion_matrix
cf = confusion_matrix(y_test, y_pred) # 정답값, 예측값 순- 시각화
s = sns.heatmap(cf, annot=True, cmap='Blues', fmt='d', cbar=False)
s.set(xlabel='Prediction', ylabel='Actual')
plt.show()- 성능
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score
acc = accuracy_score(y_test, y_pred)
rs = recall_score(y_test, y_pred)
ps = precision_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f'accuracy : {acc}')
print(f'recall : {rs}')
print(f'precision : {ps}')
print(f'f1 : {f1}')7. 모델 튜닝
score = []
for k in range(3, 100):
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
score.append(acc)- 시각화
plt.plot(range(3,100),score)
plt.show()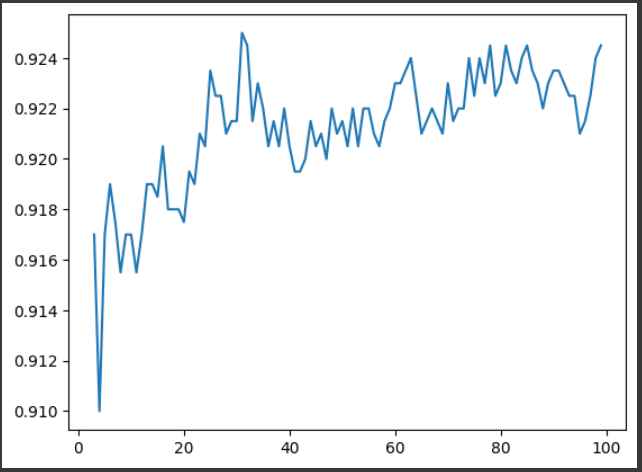
-> k=40일 때가 best라고 가정 후 재학습
best_clf = KNeighborsClassifier(n_neighbors=40)
best_clf = best_clf.fit(X_train, y_train)