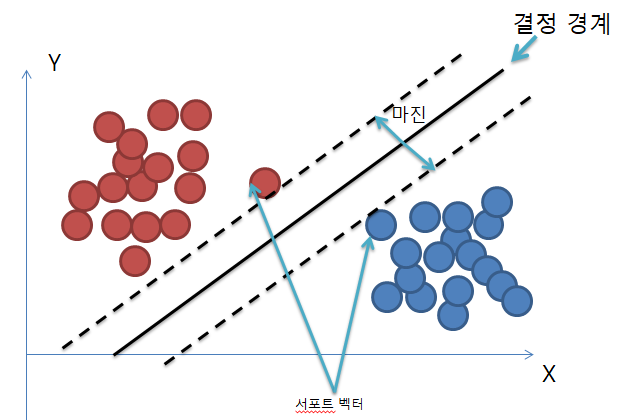
1. 서포트 벡터 머신(SVM)
1. 개념
- 지도 학습 알고리즘
- 복잡한 분류 문제에 적합
- 선형, 비선형 분류 모두 사용 가능
- 회귀에도 사용 가능
- 이진 분류만 가능 (이진 분류기를 여러 개 사용하여 다중 클래스를 분류하는 기법도 많음)
- 확률 추정치 제공 X
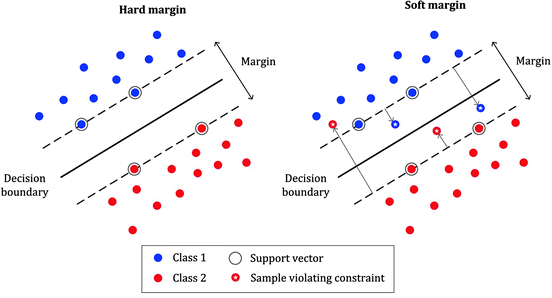
2. 하드 마진 분류(Hard Margin Classification)
- 모든 데이터가 서포터 벡터의 바깥에 존재하는 경우
3. 소프트 마진 분류(Soft Margin Classification)
- 과적합을 막기 위한 규제
- 에러를 고려하는 서포트 벡터 머신 모델
4. 손실 함수 정정
- C(페널티 계수): 오류를 어느정도 패널티를 줄 건지 결정
- C를 줄인다 = 규제를 많이 준다
- C값이 클수록 하드마진(규제를 적게 적용)
++ 다변량 데이터: 결정경계가 선이 아니라 초평면(Hyperplan)
5. 비선형 SVM 분류
-
Kernel Trick(커널 트릭): 저차원 데이터를 고차원 데이터로 매핑
ex) 선형, 다항식, 가우시안 RBF 커널, 유사도 -
커널을 이용하여 차원을 바꾼 후 분류
-
원래의 차원에서는 비선형 분류가 됨
-
커널
- poly 사용: degrees 파라미터 설정
- rbf 사용: gamma 값 설정
2. SVM 실습
- 이용 데이터: 피마인디언 당뇨병 데이터셋
1. 데이터 준비
!wget https://raw.githubusercontent.com/devdio/datasets/main/diabetes.csv# 원본 데이터 복제하여 df에 저장
df = diabetes.copy()
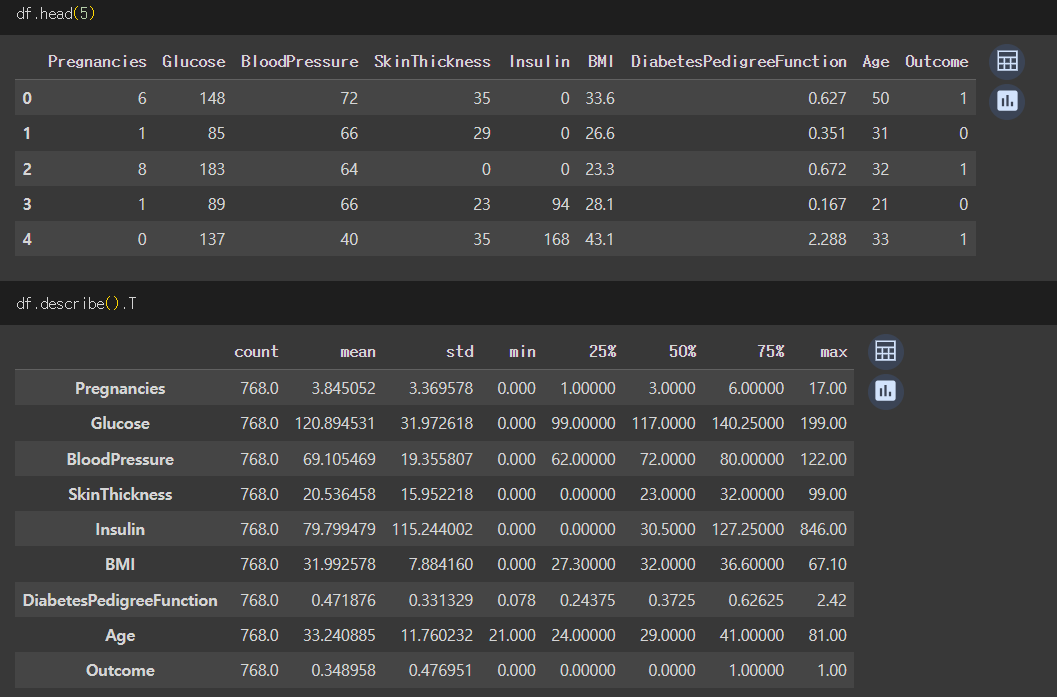
df.head(5)- 데이터 정보
# 당뇨병 환자수 확인
df['Outcome'].value_counts()2. 테스트 데이터 분리
X = df.drop("Outcome", axis=1)
y = df['Outcome']# 사이킷런 함수 사용
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)stratify: class label의 비율을 맞춰서 split
3. 전처리
- 결측치 확인
X_train.isna().sum(axis=0)- 이상치 처리
방법 1. 0인 값들을 결측 처리 후 삭제
df1 = X_train.copy()
# 값이 0이면 안되는 columns 명
cols = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI']
# 0을 결측치로 바꿔주기
df1 = df1[cols].replace(0, np.nan)
df1.isna().sum()
# 결측치 삭제
df1 = df1.dropna()방법 2. 0인 값을 적당한 값으로 채워넣는 방법
df2 = X_train.copy()
#0을 nan으로
df2[cols] = df2[cols].replace(0, np.nan)
df2.isna().sum()
# 결측치를 중앙값으로
df2['Glucose'] = df2['Glucose'].fillna(df2['Glucose'].median())
df2['BloodPressure'] = df2['BloodPressure'].fillna(df2['BloodPressure'].median())
df2['SkinThickness'] = df2['SkinThickness'].fillna(df2['SkinThickness'].median())
df2['Insulin'] = df2['Insulin'].fillna(df2['Insulin'].median())
df2['BMI'] = df2['BMI'].fillna(df2['BMI'].median())
# 확인
df2.isna().sum()- 스케일링
X_train = df2.copy()
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# scaler.fit(X_train)
# scaler.transform(scaler)
X_train_s = scaler.fit_transform(X_train)
X_train_s # numpy array 형태로 출력4. 학습
from sklearn.svm import SVC
clf = SVC(random_state = 42)
clf = clf.fit(X_train_s, y_train)5. 예측
-
테스트 데이터 전처리 먼저
- 0인 값을 위에서 계산한 값으로 넣는 작업
- 스케일링df3 = X_test.copy() df3[cols] = df3[cols].replace(0, np.nan) df3.isna().sum() # 결측치를 중앙값으로 df3['Glucose'] = df3['Glucose'].fillna(df3['Glucose'].median()) df3['BloodPressure'] = df3['BloodPressure'].fillna(df3['BloodPressure'].median()) df3['SkinThickness'] = df3['SkinThickness'].fillna(df3['SkinThickness'].median()) df3['Insulin'] = df3['Insulin'].fillna(df3['Insulin'].median()) df3['BMI'] = df3['BMI'].fillna(df3['BMI'].median()) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_test_s = scaler.fit_transform(X_test) # 예측 y_pred = clf.predict(X_test_s) # 정확도 from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score acc = accuracy_score(y_test, y_pred) rs = recall_score(y_test, y_pred) ps = precision_score(y_test, y_pred) f1 = f1_score(y_test, y_pred) print(f'accuracy : {acc}') print(f'recall : {rs}') print(f'precision : {ps}') print(f'f1 : {f1}')
6. 튜닝
- C, gamma, kernel, degrees 하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV
params = {
"C": [0.1, 1, 10, 100],
"gamma": [0.01, 0.1, 1, 10],
"degree": [2,3],
"kernel": ["linear", "poly", "rbf"]
}
grid_cv = GridSearchCV(SVC(), params, cv=5, refit=True, verbose=3) # cv=5: 5번 돌려서 정확도의 평균 계산, refit=True: 학습이 완료된 상태로 남아있겠다는 의미
grid_cv.fit(X_train_s, y_train)- 위의 경우의 수 중 어떤게 best?
grid_cv.best_estimator_
grid_cv.best_score_
grid_cv.best_params_- 베스트 모델 학습: 위에서 구한 값 대입
clf = SVC(C=0.1, degree=2, gamma= 0.01, kernel='linear')
clf = clf.fit(X_train_s, y_train)7. 모델 저장
import pickle
with open('svc_c_0.1_degree_2_gamma_0.01_rbf.pickle', 'wb') as f:
pickle.dump(clf, f)
with open('standard_scaler.pickle', 'wb') as f:
pickle.dump(scaler, f)- 모델 사용
with open('svc_c_0.1_degree_2_gamma_0.01_rbf.pickle', 'rb') as f:
clf = pickle.load(f)
with open('standard_scaler.pickle', 'rb') as f:
scaler = pickle.load(f) 
8. K-nn알고리즘 학습
# 베이스 모델 학습
from sklearn.neighbors import KNeighborsClassifier
clf2 = KNeighborsClassifier() # 객체 만들기
clf2 = clf.fit(X_train_s, y_train) # 학습시키기
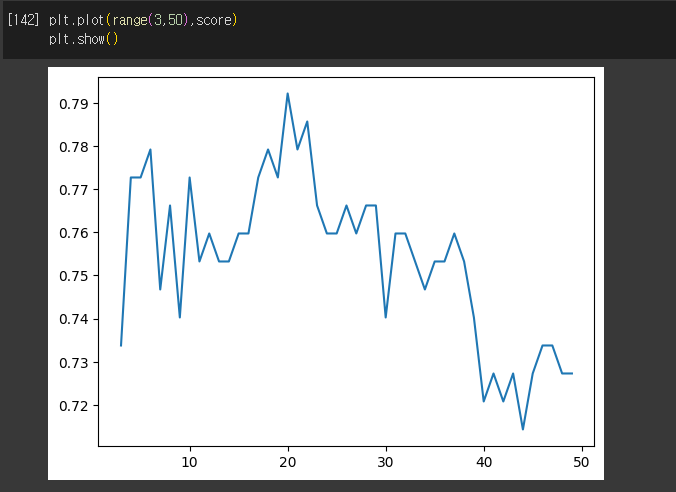
score = []
for k in range(3, 50):
clf2 = KNeighborsClassifier(n_neighbors=k)
clf2.fit(X_train_s, y_train)
y_pred = clf2.predict(X_test_s)
acc = accuracy_score(y_test, y_pred)
score.append(acc)