- https://www.kaggle.com/code/parulpandey/penguin-dataset-the-new-iris/input?select=penguins_size.csv 이용
- 타겟: 펭귄 종류
- SVM 사용
- 테스트 파일(20%): 미리 준비
1. 데이터 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
penguin = pd.read_csv("/content/drive/MyDrive/SKT FLY AI_수업 코드/penguins_size.csv")
penguin.shape2. 테스트 데이터 분리
1. X, y 분리
X = df.drop( ['species'] , axis = 1)
y = df['species']2. train / test 데이터 분리
from sklearn.model_selection import train_test_split
X_train , X_test , y_train , y_test = train_test_split( X,y,test_size=0.2, random_state = 1, stratify=y ) # stratify : y값을 보고 공정하게 나눠주는 역할3. 데이터 전처리
1. 인코딩
-
get_dummies() 함수 사용하지 않는 것이 좋음!
-
one-hot encoding
범주형 데이터를 기계학습을 위해, 해당 범주에 속하는 경우 1로, 속하지 않는 경우 0으로 표시되도록 인코딩
- pd.get_dummies(): 명목변수만 0과 1로 원-핫 인코딩 + 명목변수: '남녀'같이 카테고리를 표현하는 변수로, 순위를 나타내지 않는 변수 + 첫 번째 인자: 더미변수로 바꿔줄 데이터 대입 + 두 번째 인자: 더미변수로 바꿔 줄 범주형 컬럼 이름 대입 ( columns을 따로 지정하지 않으면 문자열 데이터로 이루어진 컬럼들이 자동으로 지정됨) - OneHotEncoder(): train 데이터셋과 test 데이터셋의 범주 개수가 다른 경우에, test 데이터의 범주 개수를 train 데이터셋에 맞춰서 똑같이 생성 가능(dummies 사용하면, 이 경우에 오류 발생)
replacement_dict = {'Adelie': 0, 'Chinstrap': 1, 'Gentoo': 2}
df['species'] = df['species'].replace(replacement_dict)
replacement_island_dict = {'Torgersen': 0, 'Biscoe': 1, 'Dream': 2}
df['island'] = df['island'].replace(replacement_island_dict)2. Nan 처리
ex) 평균값, 중앙값, 최댓값, 최솟값, 삭제, 0 등등
- 수치형 데이터들의 nan: 평균 대입
df['culmen_length_mm'] = df['culmen_length_mm'].fillna(df['culmen_length_mm'].mean())
df['culmen_depth_mm'] = df['culmen_depth_mm'].fillna(df['culmen_depth_mm'].mean())
df['flipper_length_mm'] = df['flipper_length_mm'].fillna(df['flipper_length_mm'].mean())
df['body_mass_g'] = df['body_mass_g'].fillna(df['body_mass_g'].mean())- 성별열(Sex열) 처리
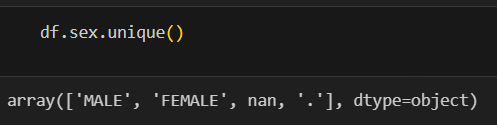
-> .을 삭제 후 범주형 변수처럼 처리
df = df.drop(df[df.sex == '.'].index, axis=0)replacement_sex_dict = {'FEMALE': 0, 'MALE': 1}
df['sex'] = df['sex'].replace(replacement_sex_dict)4. 스케일링
# MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_s = scaler.fit_transform(X_train)
X_train_S
from sklearn.preprocessing import MinMaxScaler
X_test_s = scaler.transform(X_test)
X_test_s# StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_s = scaler.fit_transform(X_train)
X_train_s
from sklearn.preprocessing import StandardScaler
X_test_s = scaler.transform(X_test)
X_test_s5. SVM 모델 불러오기
from sklearn.svm import SVC
clf = SVC(random_state = 42)
clf = clf.fit(X_train_s,y_train)6. 예측
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_test,y_pred) # 정답값, 예측
print(f'optimal_accuracy: {acc}')7. 튜닝
from sklearn.model_selection import GridSearchCV
params = {
"C" : [ 0.1 , 1 , 10 , 100 ],
"gamma" : [0.01 , 0.1 , 1 , 10 ],
"degree" : [ 3 ],
"kernel" : [ "linear" , "rbf" , "poly" ]
}
grid_cv = GridSearchCV( SVC() , params, cv = 2 , refit = True , verbose = 3 ) # 5번 돌려서 평균 내기
grid_cv.fit( x_train_s , y_train )
print( grid_cv.best_estimator_ )
print( grid_cv.best_score_ )
print( grid_cv.best_params_ )-> best parametr 찾아서 대입
clf = SVC( C = 0.1, degree = 3, gamma = 0.01, kernel = 'linear' )
clf = clf.fit( x_train_s , y_train )
y_pred = clf.predict( x_test_s )
acc = accuracy_score( y_test , y_pred )
print( f"정확도 : {acc}" )