1. K-Means Clustering(K-평균 군집화)
: 레이블(정답)이 없는 데이터 안에서 패턴과 구조를 발견하는 비지도 학습
-
목표: 서로 유사한 데이터들을 같은 그룹으로 묶어주는 것
-
분류: 지도학습
-
군집: 비지도학습
-
K: 군집 개수(몇 개의 그룹으로 묶을 것인지)
-
SSE: K를 선택하는 방법
-> 군집들이 얼마나 뭉쳐져 있는지 나타냄
2. 차원 축소
-
차원: 공간에서 데이터의 위치를 나타내기 위해 필요한 축의 수
-
차원의 저주: 차원 증가(= features 증가) -> 데이터의 밀도 감소 -> 과적합 가능성 증가
해결 방법
- 샘플의 밀도가 높아질 때까지 훈련 세트의 크기 키우기
: 불가능한 경우가 대부분 - 차원 축소: 특징 선택, 특징 추출
- 샘플의 밀도가 높아질 때까지 훈련 세트의 크기 키우기
-
투영:분산이 큰 방향으로 투영해야, 데이터 손실이 적음
<주성분 분석(PCA)>
- 가장 인기 있는 차원 축소 알고리즘
- 분산이 최대로 되는 축 선택 후 투영(주성분으로 투영)
- 주성분: 데이터의 분산을 가장 잘 유지하는 축들
3. 실습
1) 데이터 준비
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
!wget https://raw.githubusercontent.com/devdio/datasets/main/iris.csv
iris = pd.read_csv('iris.csv')
df = iris.copy()
df.head()2) 데이터 분리&스케일링
X = df.drop(['Id','Species'], axis=1)
y = df['Species']
# PCA 사용 시, 스케일링 하는 것이 좋음
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_S = scaler.fit_transform(X)3) 차원 축소
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 2차원 데이터로(2차원으로 투영)
X_P = pca.fit_transform(X_S)- y 인코딩
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)- 그래프 그리기
data = pd.DataFrame(X_P, columns=['PC1', 'PC2'])
#그래프
plt.scatter(data['PC1'], data['PC2'], c=y, s=50) # y로 색깔 표현, 원의 크기 50
plt.show()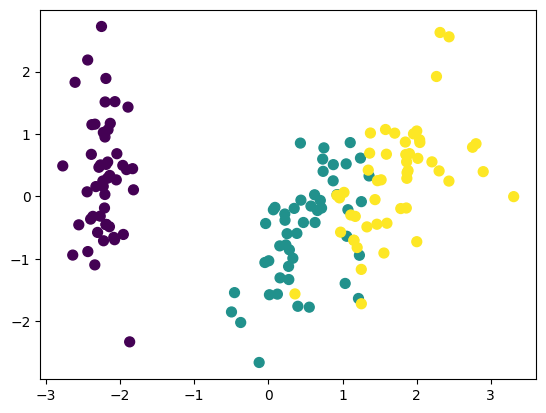
4) K-Means 군집화
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3)
km.fit(X_P) # 비지도학습이므로 정답값 y 들어가지 X
y_pred = km.predict(X_P)
# 그래프
plt.scatter(data['PC1'], data['PC2'], c=y_pred, s=50) # y로 색깔 표현, 원의 크기 50
plt.show()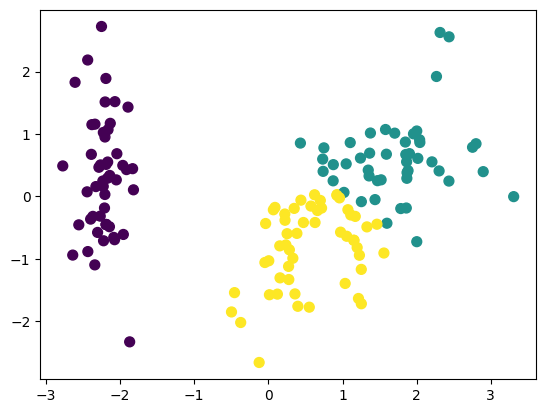
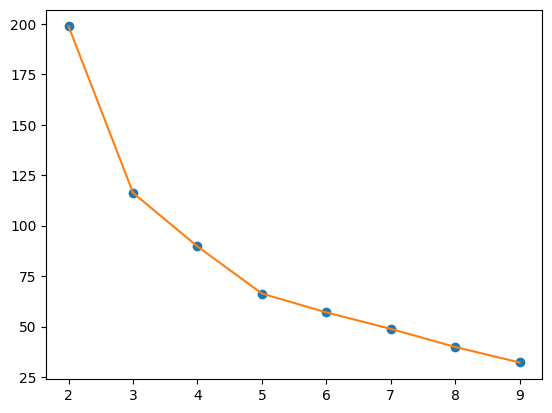
5) K값 찾기
inertia = []
for k in range(2, 10):
km = KMeans(n_clusters=k)
km.fit(X_P)
inertia.append(km.inertia_)
# 그래프
plt.plot(np.arange(2,10), inertia, 'o') # 점을 찍어라
plt.plot(np.arange(2,10), inertia, '-') # 선을 이어라
plt.show()