이번 포스팅에서는 MySQL의 EXPLAIN 명령어에 대해 알아보는 시간을 가지도록 하겠습니다.
👌 MySQL EXPLAIN이란?
MySQL의 EXPLAIN은 MySQL 서버가 어떠한 쿼리를 실행할 것인가, 즉 실행 계획이 무엇인지 알고 싶을 때 사용하는 기본적인 명령어입니다. 쉽게 말해 데이터 베이스에서 데이터를 어떻게 찾을 것 인가에 관련하여 설명해주는 명령어입니다.
만약 데이터베이스 스키마를 작성하고 쿼리를 날렸을 때 속도가 저하되는 부분에 대해서 쿼리 성능 개선을 하게 됩니다. 쿼리를 수정하기 위해서 MySQL 서버가 어떤 방식으로 데이터를 찾는지 알아야할텐데 그때 사용하는 것이 바로 EXPLAIN 명령어 입니다.
📌 MySQL 실행 순서
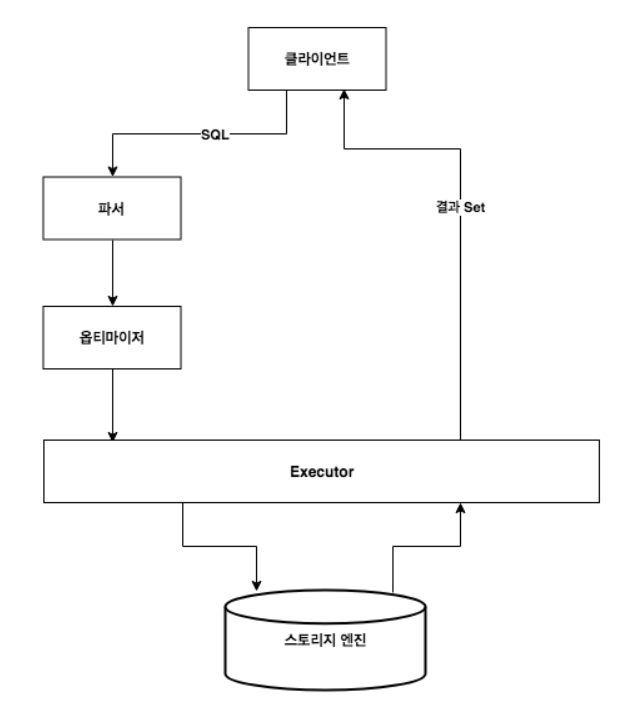
MySQL에서 SQL을 실행하면 먼저 Parser에서 SQL 구문을 분석하고 옵티마이징을 거친 후 Executor를 통해 쿼리를 실행하고 결과 데이터를 담아서 리턴하게 됩니다.
MySQL 옵티마이저 구조 - 사진 출처 : Yun Blog의 Mysql Explain
MySQL 옵티마이저는 비용 기반으로 어떤 실행 계획으로 쿼리를 실행했을 때 비용이 얼마나 발생하는지를 계한하여 비용이 가장 적은 실행 계획을 택하게 됩니다. 옵티 마이징은 내부적으로 가장 비용이 적은 방법을 찾아서 택하는 것을 의미합니다.
💡 MySQL EXPLAIN 사용
다음은 EXPLAIN 명령어 사용 방법에 대해 알아보도록 하겠습니다. 기본 구문은 다음과 같습니다.
EXPLAIN [EXTENDED] 실행할 쿼리(SELECT ... FROM ... WHERE ...) 예를 들어 다음과 같이 명령어를 날려보겠습니다.
EXPLAIN SELECT * FROM file f join file_info fi on f.file_id = fi.file_id;위와 같이 EXPLAIN 명령어를 실행한 결과는 아래와 같습니다.

✔️ id
쿼리 내에서 실행 순서를 나타냅니다. MySQL은 조인을 하나의 단위로 실행하기 때문에 조인을 수행하는 쿼리에서는 모든 행이 id는 항상 1이 되고 이는 동일한 단일 쿼리 블록을 나타냅니다.
✔️ select_type
쿼리의 유형을 나타냅니다. 여기서는 SIMPLE로 표시되며, 이는 서브쿼리를 포함하지 않는 단순한 SELECT 쿼리임을 나타냅니다. 서브쿼리나 UNION이 있으면 id와 select_type이 변하게 됩니다.
✔️ table
어떤 테이블에 대한 접근을 표시하고 있는지를 표시해주는 필드입니다.
✔️ partitions
쿼리에 사용된 파티션을 나타냅니다. 이 경우 NULL로 표시되어 파티션이 사용되지 않았음을 나타냅니다.
✔️ type
type은 접근 방식을 표시하는 필드입니다. 접근 방식은 테이블에서 행 데이터를 어떤 방식으로 가져올 것인가를 말합니다. 예를 들어, eq_ref는 조인 시 기본키나 고유키를 사용하여 하나의 값으로 접근(최대 1행만을 정확하게 패치), ref는 여러 개의 행을 패치할 가능성이 있는 접근을 의미합니다.
접근 방식은 대상 테이블로의 접근이 효율적일지 여부를 판단하는데 아주 중요한 항목입니다.
이들 접근 방식 가운데도 주의가 필요한 것은 ALL, index, ref_or_null입니다. ALL, index 두 가지는 테이블 또는 특정 인덱스가 전체 행에 접근하기 때문에 테이블 크기가 크면 효율이 떨어집니다. ref_or_null의 경우 NULL이 들어있는 행은 인덱스의 맨 앞에 모아서 저장하지만 그 건수가 많으면 MySQL 서버의 작업량이 방대해집니다. 추가로 ALL 이외의 접근 방식은 모두 인덱스를 사용합니다.
| 접근 방식 | 설명 |
|---|---|
| const | 기본키 또는 고유키에 의한 lookup(등가비교), 조인이 아닌 가장 외부의 테이블에 접근하는 방식이며 결과는 항상 1행입니다. 단 기본키, 고유키를 사용하고 있으므로 범위 검색으로 지정하는 경우 const가 되지 않습니다 |
| system | 테이블에 1행 밖에 없느 경우의 특수한 접근 방식 |
| ALL | 전체 행 스캔, 테이블의 데이터 전체에 접근합니다 |
| index | 인덱스 스캔, 테이블의 특정 인덱스의 전체 엔트리에 접근합니다 |
| eq-ref | 조인이 내부 테이블로 접근할 때 기본키 또는 공유키에 의한 lookup이 일어납니다. const와 비슷하지만 조인의 내부 테이블에 접근한다는 점이 다릅니다 |
| ref | 고유키가 아닌 인덱스에 대한 등가비교, 여러 개 행에 접근할 가능성이 있습니다 |
| ref_or_null | ref와 마찬가지로 인덱스 접근 시 맨 앞에 저장되어 있는 NULL의 엔트리를 검색합니다 |
| range | 인덱스 특정 범위의 행에 접근합니다 |
| fulltext | fulltext 인덱스를 사용하는 검색입니다 |
| index_merge | 여러 개의 인스턴스를 사용해 행을 가져오고 결과를 통합합니다 |
| unique_subquery | IN 서브쿼리 접근에서 기본키 또는 고유키를 사용합니다. 이 방식은 쓸데없는 오버헤드를 줄여 상당히 빠릅니다 |
| index_subquery | unique_sunquery와 거의 비슷하지만 고유한 인덱스를 사용하지 않는 점이 다릅니다. 이 접근 방식도 상당히 빠릅니다 |
✔️ possible_keys
쿼리 실행 시 이용 가능성이 있는 인덱스의 목록을 나타냅니다.
✔️ key
possible_keys 필드의 이용 가능성이 있는 인덱스의 목록 중에서 실제로 옵티마이저가 선택한 인덱스가 key가 됩니다. NULL로 표시되면, 인덱스가 사용되지 않았음을 나타냅니다.
✔️ key_len
key_len 필드는 선택된 인덱스의 길이를 의미합니다. 만약 key_len 필드의 값이 크다면 인덱스가 너무 길다는 것을 의미하므로 비효율적일 수 있습니다.
✔️ rows
옵티마이저가 예측한 이 쿼리에서 읽어야 할 행 수를 나타냅니다. 최초에 접근하는 테이블에 대해서 쿼리 전체에 의해 접근하는 행 수, 그 이후에 테이블에 대해서는 1행의 조인으로 평균 몇 행에 접근했는가를 표시합니다. 단 어디까지나 통계 값으로 계산한 값이므로 실제 행 수와 반드시 일치하지 않습니다.
✔️ filtered
filtered 필드는 행 데이터를 가져와 그 중 WHERE 검색 조건이 적용되면 몇 행이 남는지를 표시합니다. 이 값도 통계 값 바탕으로 계산한 값이므로 현실의 값과 반드시 일치하지 않습니다.
✔️ extra
추가적인 정보나 옵티마이저의 주석을 나타냅니다. 위의 결과에서 첫 번째 행에서는 아무것도 없고, 두 번째 행에서는 Using where; Using join buffer (hash join)로 표시되어, WHERE 조건을 사용했으며 해시 조인 버퍼를 사용했음을 나타냅니다. extra 필드는 EXPLAIN 명령어를 사용해 옵티마이저의 행동을 파악할 때 매우 중요한 역할을 합니다.
| Extra | 설명 |
|---|---|
| Using where | 접근 방식을 설명한 것으로, 테이블에서 행을 가져온 후 추가적으로 검색 조건을 적용해 행의 범위를 축소한 것을 표시합니다 |
| Using index | 테이블에는 접근하지 않고 인덱스에서만 접근해서 쿼리를 해결하는 것을 의미합니다. 커버링 인덱스로 처리되고 index only scan이라고도 부릅니다 |
| Using index for group-by | Using index와 유사하지만 GROUP BY가 포함되어 있는 쿼리를 커버링 인덱스로 해결할 수 있음을 나타냅니다 |
| Using filesort | ORDER BY 인덱스로 해결하지 못하고, filesort(MySQL의 quick sort)로 행을 정렬한 것을 나타냅니다 |
| Using where with pushed | 엔진 컨디션 pushdown 최적화가 일어난 것을 표시합니다. 현재는 NDB만 유효합니다 |
| Using index condition | 인덱스 컨디션 pushdown(ICP) 최적화가 일어났음을 표시합니다. ICP는 멀티 컬럼 인덱스에서 왼쪽부터 순서대로 컬럼을 지정하지 않은 경우에도 인덱스를 이용하는 실행 계획입니다 |
| Using MRR | 멀티 레인지 리드(MRR) 최적화가 사용되었음을 표시합니다 |
| Using join buffer(Block Nested Loop) | 조인에 적절한 인덱스가 없어 조인 버퍼를 이용했음을 표시합니다 |
| Using join buffer(Batched Key Access) | Batched Key Access(BKA) 알고리즘을 위한 조인 버퍼를 사용했음을 표시합니다다 |
📝 참고 사항
커버링 인덱스(Covering Index) :
커버링 인덱스는 인덱스가 쿼리에서 필요한 모든 데이터를 포함하고 있는 경우를 말합니다. 이를 위해 인덱스는 키 값과 함께 추가적인 열 값을 저장합니다.
조인 버퍼의 동작 방식
1. 테이블 읽기: 첫 번째 테이블의 데이터를 읽습니다.
2. 버퍼에 저장: 첫 번째 테이블의 데이터를 조인 버퍼에 저장합니다.
3. 두 번째 테이블 스캔: 두 번째 테이블을 한 행씩 읽으면서, 조인 조건에 맞는 행을 조인 버퍼에서 찾습니다.
4. 조인 결과 생성: 두 번째 테이블의 각 행에 대해 조인 조건을 만족하는 첫 번째 테이블의 행을 조인 버퍼에서 찾아서 결과를 생성합니다.
