Chapter 8) Planning and Learning with Tabular Methods
A unified view of reinforcement learning methods that
- require a model of environment - dynamic programming, heuristic search
- can be used without a model - MC, TD
model-based reinforcement learning method : planning
model-free reinforcement learning method : learning
- the heart of both kinds of methods is the computation of value functions
In this chapter, our goal is a similar integration of model-based and model-free methods - intermix them
Chapter 8.1) Models and Planning
model : anything that an agent can use to predict how the environment will respond to its action
distribution model : produce a description of all possibilities and their probabilities
sample model : produce just one of the possibilities
- models can be used to mimic or simulate experience : models simulate the environment and produce simulated experience
planning : any computational process that takes a model as input and produces or improves a policy for interacting with the modeled environment
- state-space planning : reinforcement learning algorithms in this book
- plan-space planning : genetic algorithm etc... not cover this topic in this book
state-space planning methods share a common structure
- 1) all state-space planning methods involve computing value functions as a key intermediate step toward improving the policy
- 2) they compute value functions by updates or backup operations applied to simulated experience
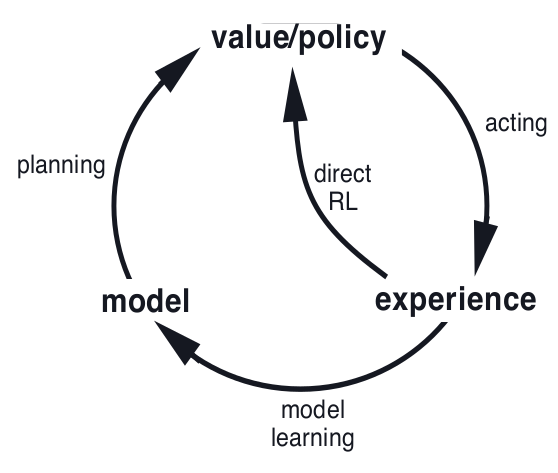
model →simulated experience →(backups) →values →policy
various state-space planning methods differ only in the kinds of updates they do
the difference between planning and learning
-
planning uses simulated experience generated by a model
-
learning methods use real experience generated by the environment
→ the common structure means that many ideas and algorithms can be transferred between planning and learning
learning methods require only experience as input and in many cases they can be applied to simulated experience just as well as to real experience
e.x. random-sample one-step tabular Q-planning

In addition the second theme in this chapter is the benefits of planning in small, incremental steps
- enable planning to be interrupted or redirected as any time with little wasted computation
- a key requirement for efficiently intermixing planning with acting and with learning of the model
Chapter 8.2) Dyna: Integrated Planning, Acting, and Learning
Dyna-Q : a simple architecture integrating the major functions needed in an online planning agent
In planning, there are two roles for real experience
- 1) improve model (to make it more accurately match the real environment)
- 2) directly improve value function and policy using the kinds of reinforcement learning methods
1) : model-learning (indirect reinforcement learning), 2) : direct reinforcement learning
Indirect methods - make fuller use of a limited amount of experience and thus achieve a better policy with fewer environmental interactions
direct methods - much simpler and are not affected by biases in the design of the model
planning(model-learning) : random-sample one-step tabular Q-planning
direct reinforcement learning : one-step tabular Q-planning
model-learning method is also table-based and assumes the environment is deterministic
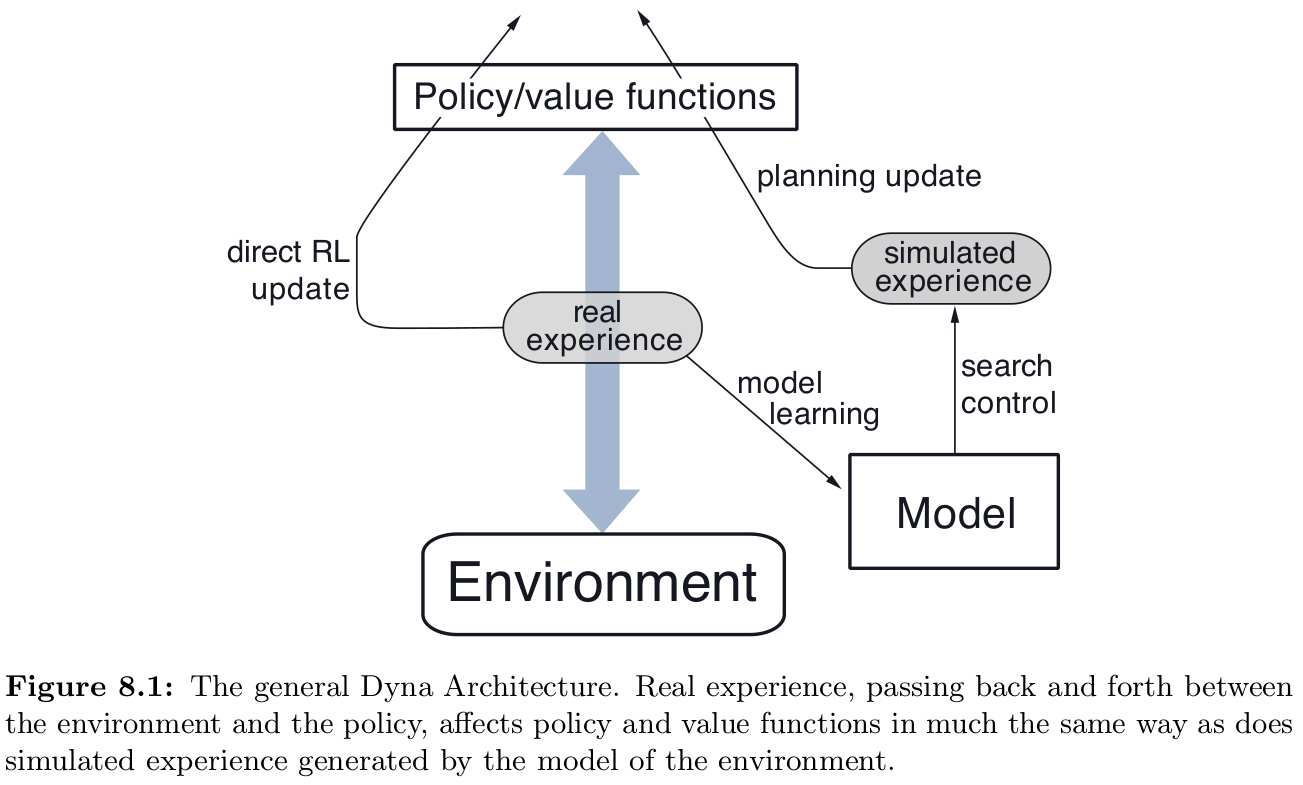
search control - the process that selects the starting states and actions for the simulated experiences generated by the model
Typically, as in Dyna-Q, the same reinforcement learning methods is used both for learning from real experience and for planning from simulated experience
The reinforcement learning method is thus the final common path for both learning and planning - differing only in the source of their experience

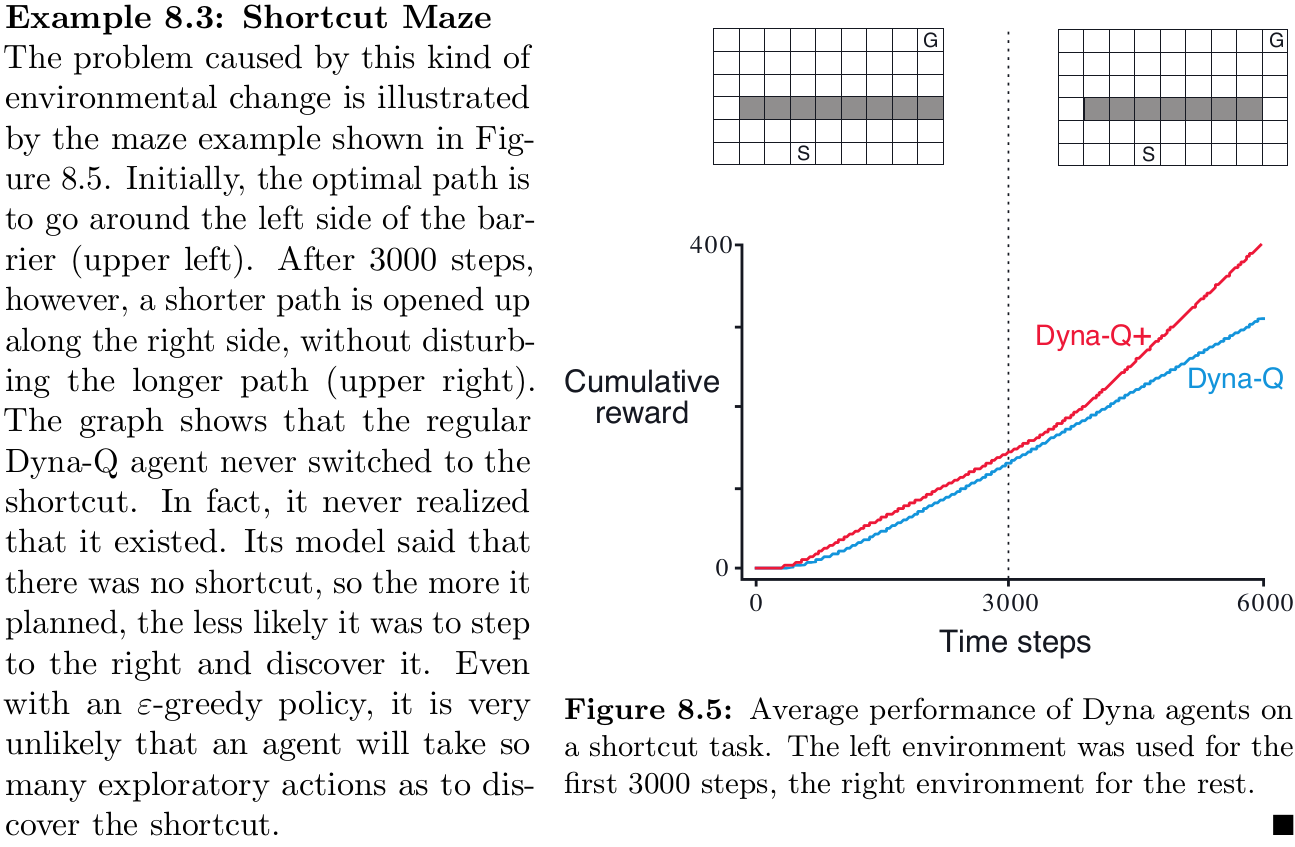
[**Example 8.1] Dyna Maze**

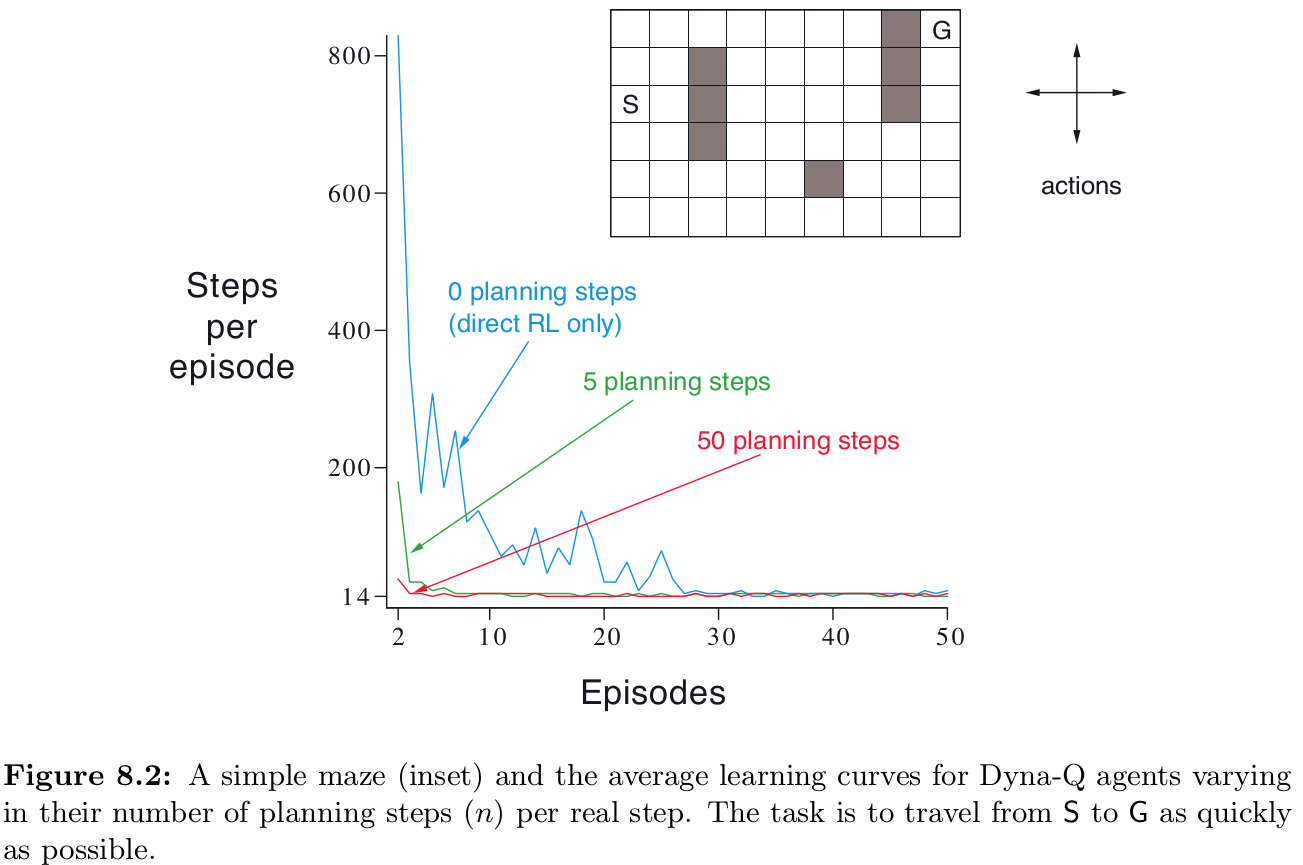
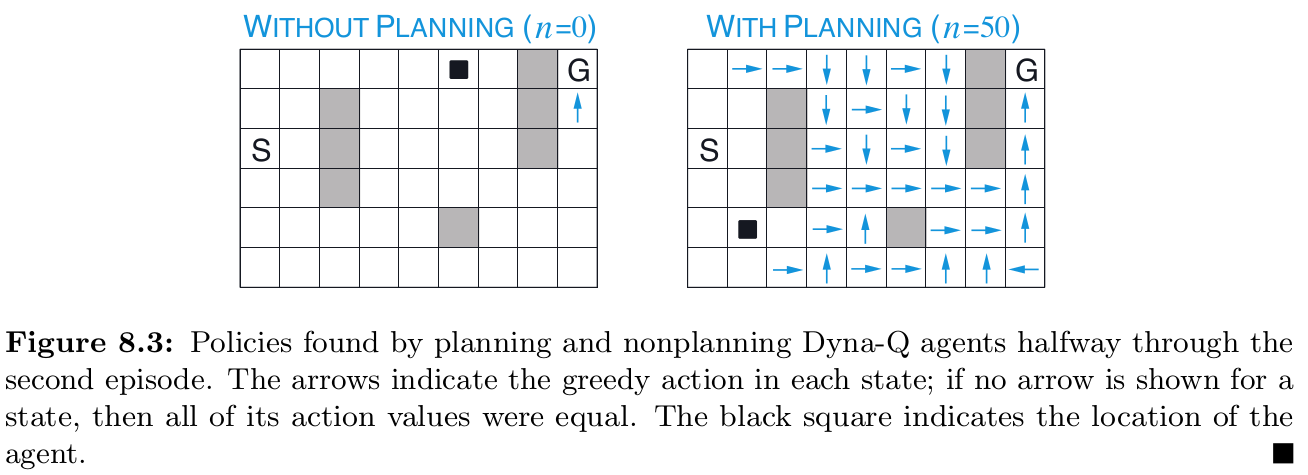
more step make optimal policy more faster than 0-step
I think more step will be better when the model is accurate because reflect the reward on value functions which are far away form termination state
Chapter 8.3) When the Model Is Wrong
Model may be incorrect because
- 1) the environment is stochastic
- 2) only a limited number of samples have been observed
- 3) the model was learned using function approximation that has generalized imperfectly
- 4) the environment has changed
- 5) its new behavior has not yet been observed
when the model is incorrect, the planning process is likely to compute a sub-optimal policy
In some cases, the sub-optimal policy computed by planning quickly leads to the discovery and correction of the modeling error
Great difficulties arise when the environment changes to become better than it was before, and yet the formerly correct policy does not reveal the improvement
- modeling error may not be detected for a long time
- even with an -greedy policy, it is very unlikely that an agent will take so many exploratory actions as to discover the shortcut
this general problem is another version of the conflict between exploration and exploitation
- exploration : improve the model
- exploitation : behaving in the optimal way given the current model
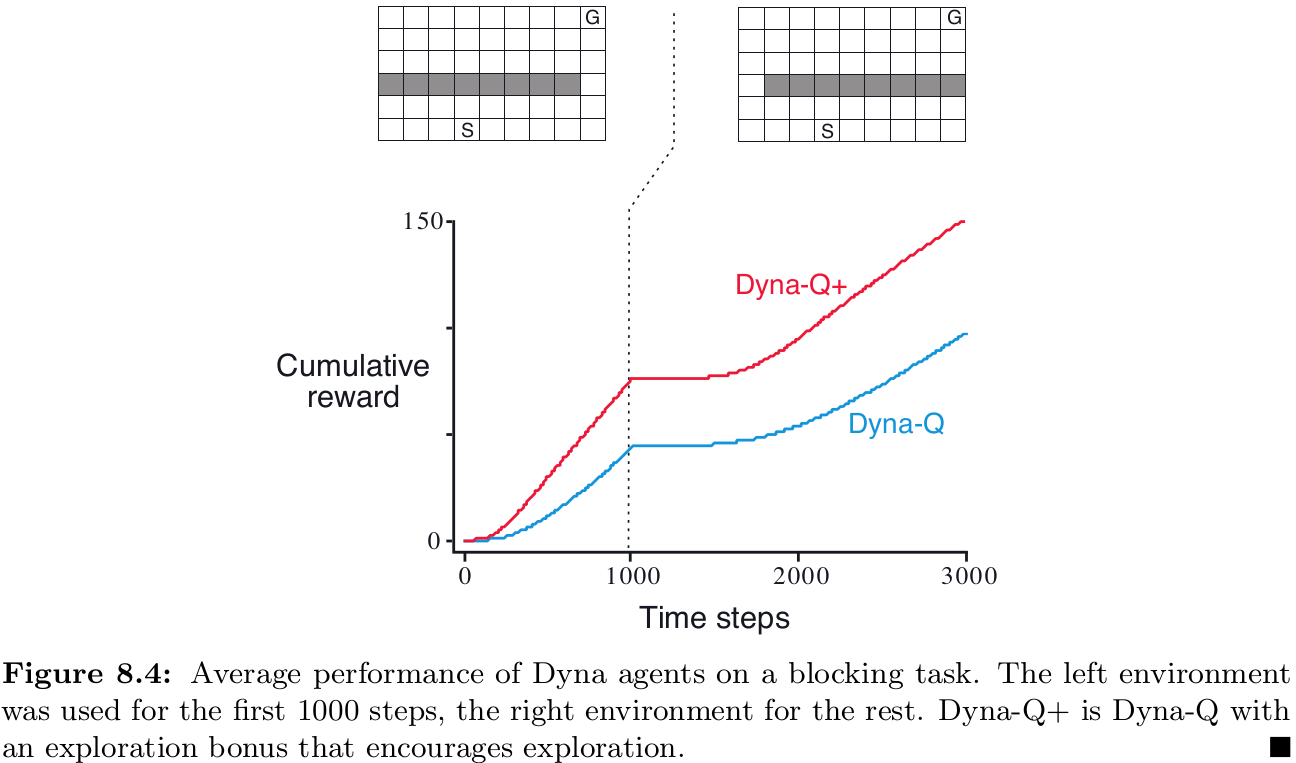
Dyna-Q+ solve this problem by heuristic method - to encourage the behavior that tests long-untried actions a special "bonus reward" is given on simulated experience involving these actions
time step , some small
reward would be
[**Example 8.2] Blocking Maze**

[**Example 8.3] Shortcut Maze**