2-1. Markov Decision Process(MDP)
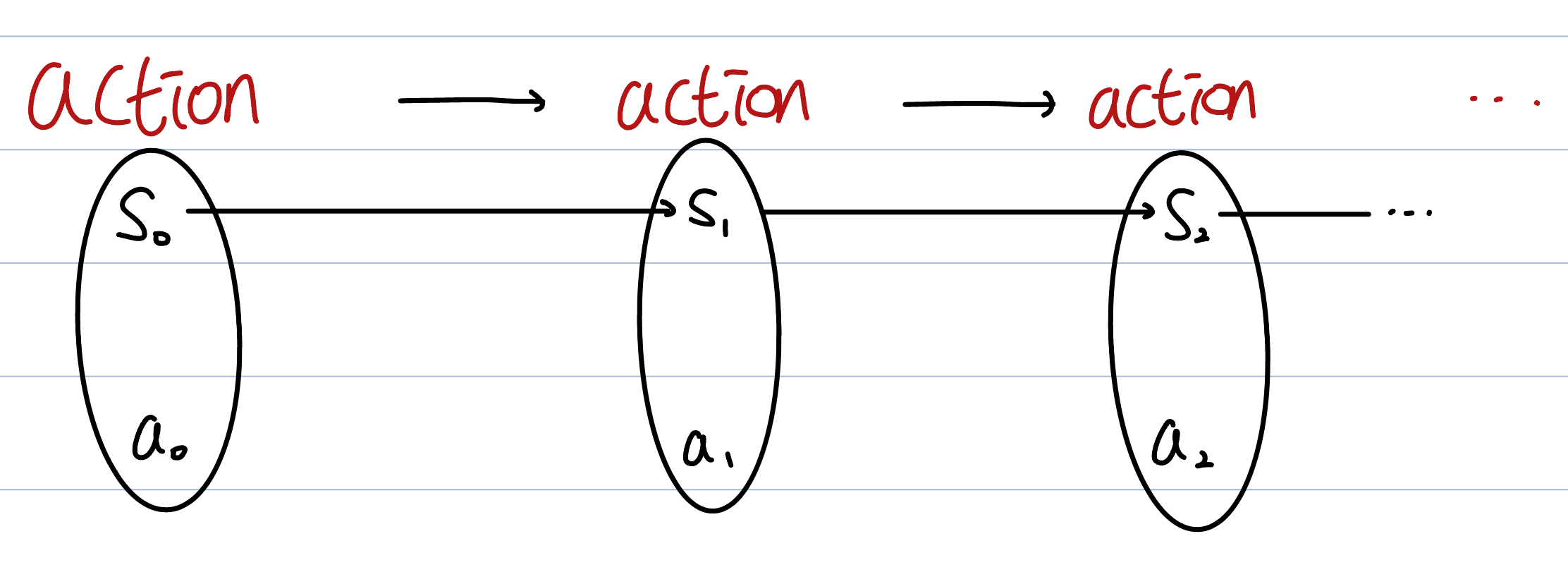
What is MDP?
Decision means, the agent decides what action to take in each state.
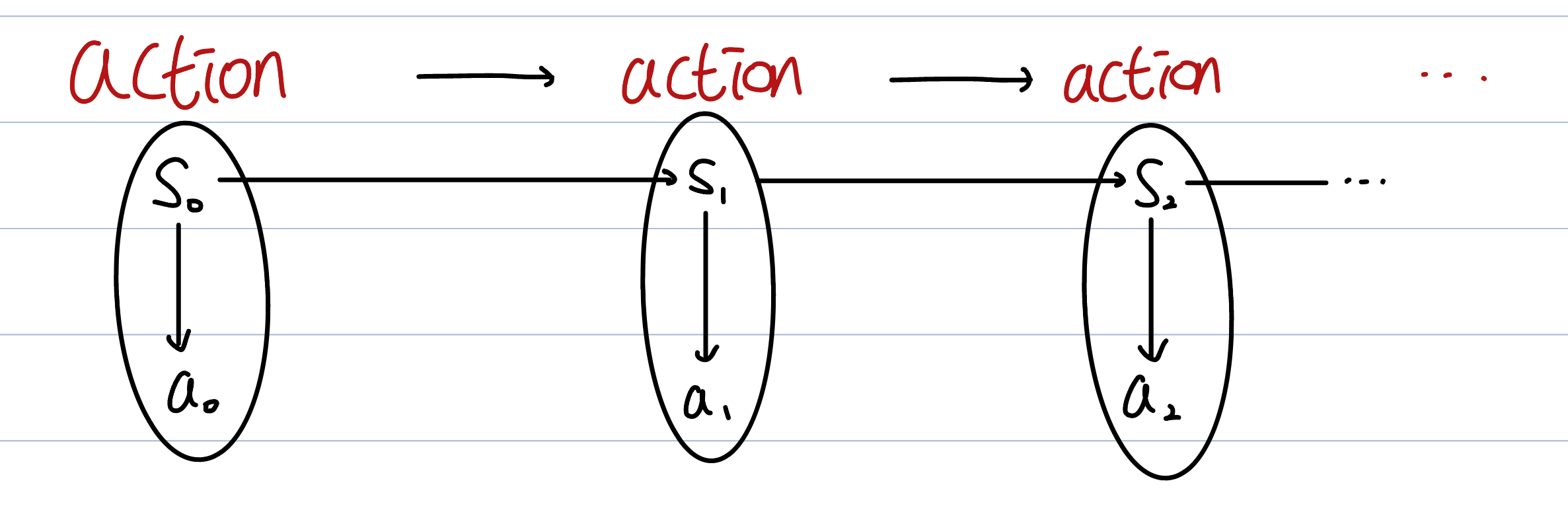
Every action() leads to next state().
The first important properties of MDP is that every action is done randomly. This means state and action has (discrete) probability distribution.
The arrows shown in the figure represent the information needed to find the probability distribution of the random variable.
So if we know the information of , then we don’t need anymore.(The probability distribution becomes ). This is because already has the information about and .
On the same principle, we can simplify the distribution of .
It first represented as .
Since already has the information about , we do not need anymore. Therefore we need to decide the distribution of .
Policy
We know how to represent the probability distribution about each state and action. The probability distribution of the action is called Policy. Since the agent has information about current state, and prior states, instructions on what action to take are expressed as a probability distribution.
The goal of reinforcement learning is to maximize reward. To be specific, the agent tries to maximize expected return.
Return can be expressed in a formula as follows:
The formula means the return is sum of the discounted reward. ( is the discounted factor as we learned in Q-learning)
Let’s recall the Q-learning.
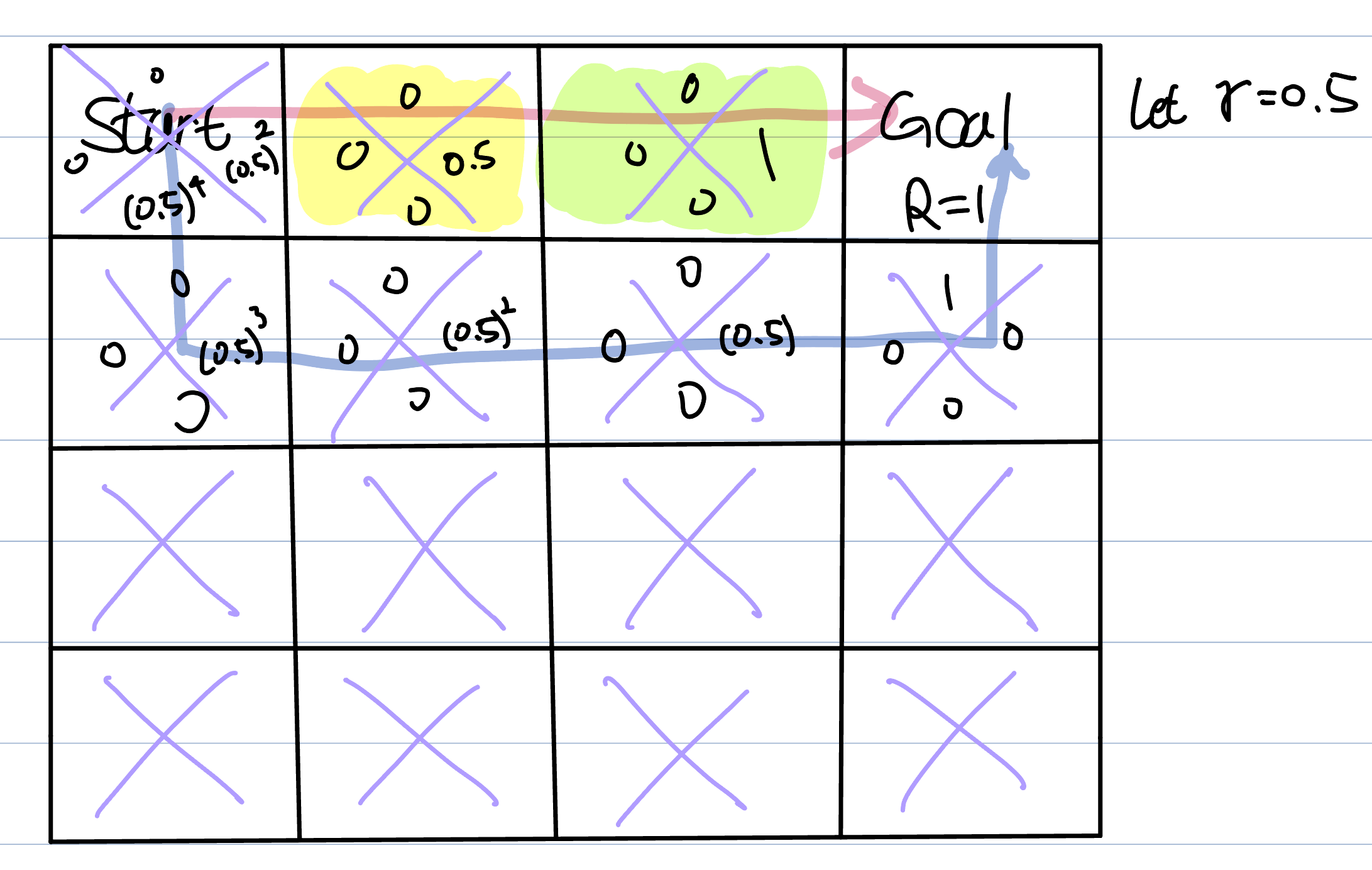
Look at the yellow box. The return of this box is 0.5. Since the next box do not have any reward, becomes 0. The only return is .
In contrast, the return of the green box is (because the next box is goal).
The agent acts randomly -> next state and reward is random as well.
we need expected reward.
The policy forces the agent to maximize average of random rewards.
In conclusion, Markov Decision Process is to find the optimal policy that maximizes the expected return.
