3.2 Monte Carlo(MC)
How can we get ?
We have learned how to calculate maximum value of state value function by optimal policy. If the is given, what we need to do is just find the policy maximizing . But, how can we get ?
Actually, we cannot get directly. We believe that if we train the agent with -greedy, its action value function will get closer to . It may not be the best policy. But we believe it’s performance may be good enough. After training, we test the agent with greedy action(not -greedy!!)
Monte Carlo : a method of getting
Recall expectation function :
The Monte Carlo method operates under the law of large numbers, asserting that as (N) increases, the approximated value in the equation above converges to the actual expectation.
Applying this method, we can express action value function in a different way.
In this approximation, follows the probability distribution().
Let’s get idea by reviewing Q-learning!
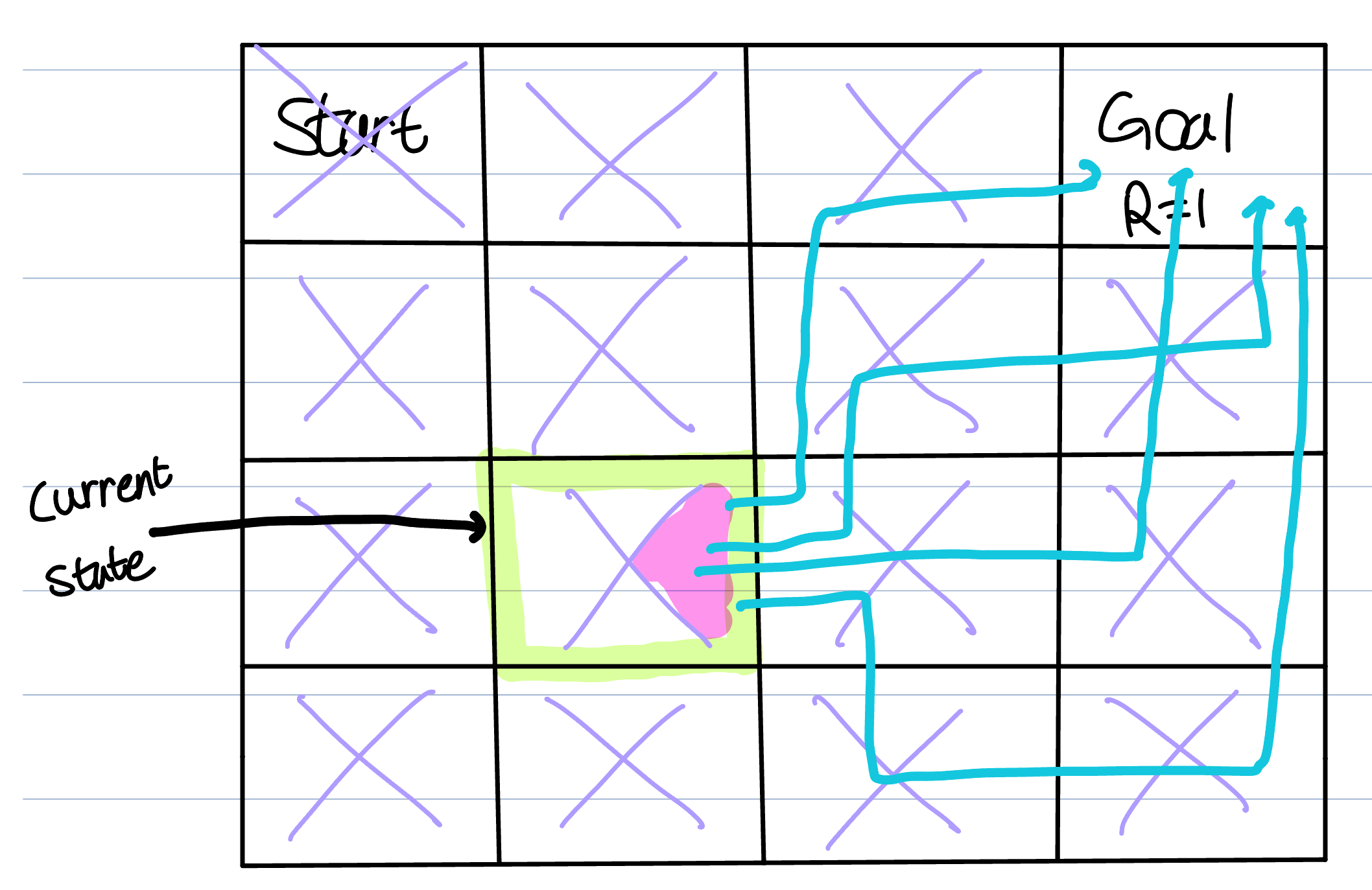
Let’s assume we want to evaluate at ‘right’ action(pink area). Initially, the agent explores all possible routes to reach the goal (this includes paths not marked in the given figure). The more paths the agent explores, the closer the approximation becomes to the original equation. However, it takes too much time. But we have to know the idea.
As the agent undergoes numerous episodes using epsilon-greedy, both Q and p improve. We train the agent until Q and p are sufficiently close to and the optimal policy, respectively. Moreover, as the agent explores more possible routes, its understanding of the probability distribution becomes more comprehensive.
