3.1 Optimal policy - more details
Optimal policy(derivation)
As we have learned, the optimal policy is a function that maximizes the state value function. The state value function focuses on maximizing the reward from the current state. But, how can we maximize the state value function? let's dive into equation.
In the equation, we can see the policy : . Our goal is to find the policy maximizing the equation.
If we apply Bellman equation to Q, we know that Q has every future policy inside.
Here is more detail about bayesian rule:

We'll denote the optimal policy as , and it's corresponding action value function as , when reflects every future optimal policy. And let's assume that we have already found the optimal policy for future actions.
Then, we need to focus on current policy only : .
let’s find probability distribution maximizing state value function.
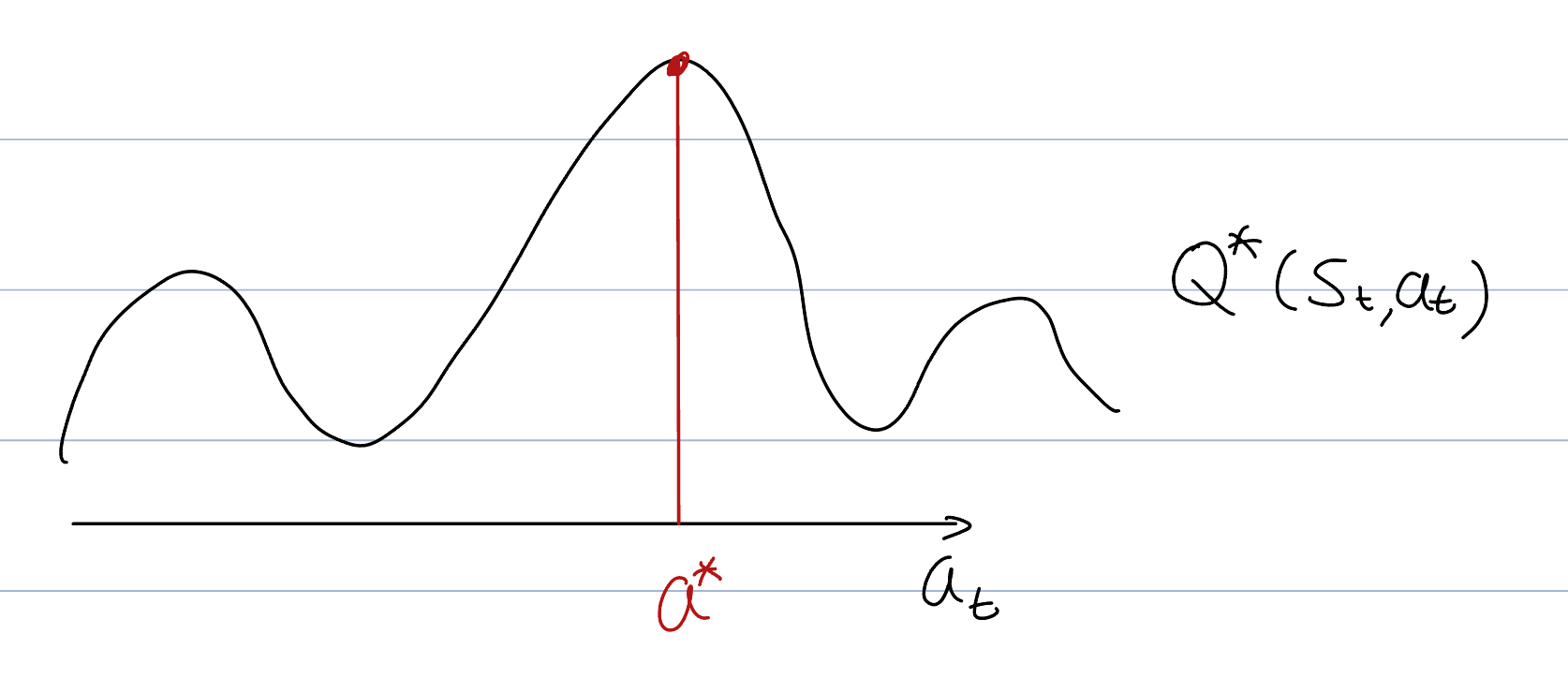
The state value function's equation is integral, implying that the optimal policy (probability) must yield only . This is possible only if the probability distribution is a delta function. A delta function is unique in that it is concentrated at a single point yet still retains an integral value of 1.
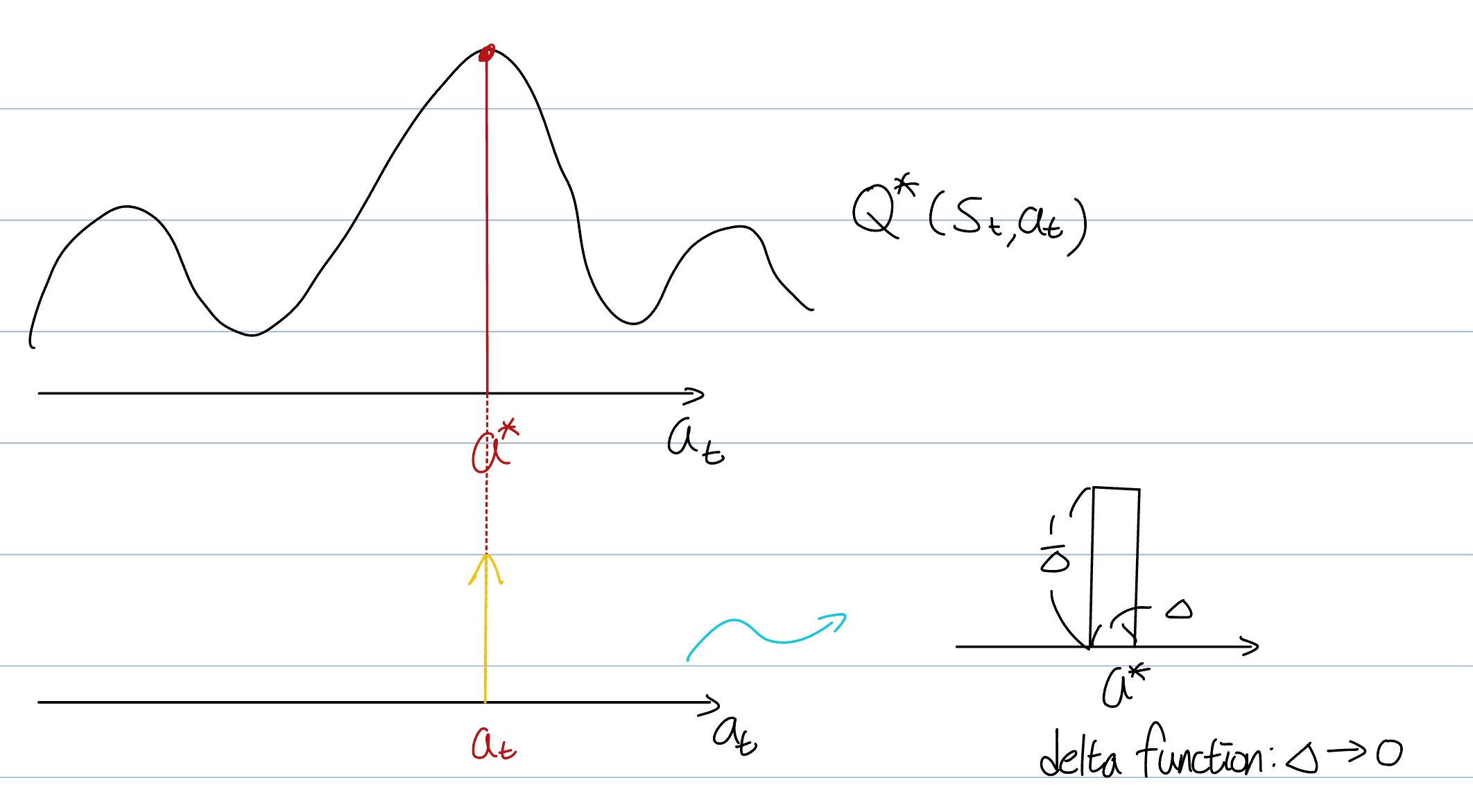
The equation of is:
And, the distribution becomes:

In short, the policy(probability distribution) is that find the maximizing , and integral only with
We have learned about -greedy.
Due to the mathematical definition of in Q-learning, beyond just an intuitive understanding from diagrams, the -greedy strategy is employed.
