
대용량 처리에 관심이 생겨서 한동안 Hadoop에 대해서 알아봤다. 그리고 Hadoop은 분산처리를 통한 빅데이터를 효과적으로 저장 및 처리를 할 수 있는 시스템이라는것을 알게 되었다.
프로젝트는 공공API에서 엄청난 양의 데이터가 쏟아져 들어온다. 물론 기업에서 사용하는 PB 급의 데이터는 절대 아니지만, 사이드 프로젝트로 수백MB정도 규모의 데이터를 처리해야 하는데 이를 활용하여 유의미한 데이터를 뽑아낸다면 좋은 결과를 낼 수 있다는 생각이 들었다.
따라서 Hadoop Ecosystem의 요소들을 사용하여 데이터를 분석하여 유의미한 데이터를 재생성하는 과정을 밟아보려고 한다.
아키텍처
목적
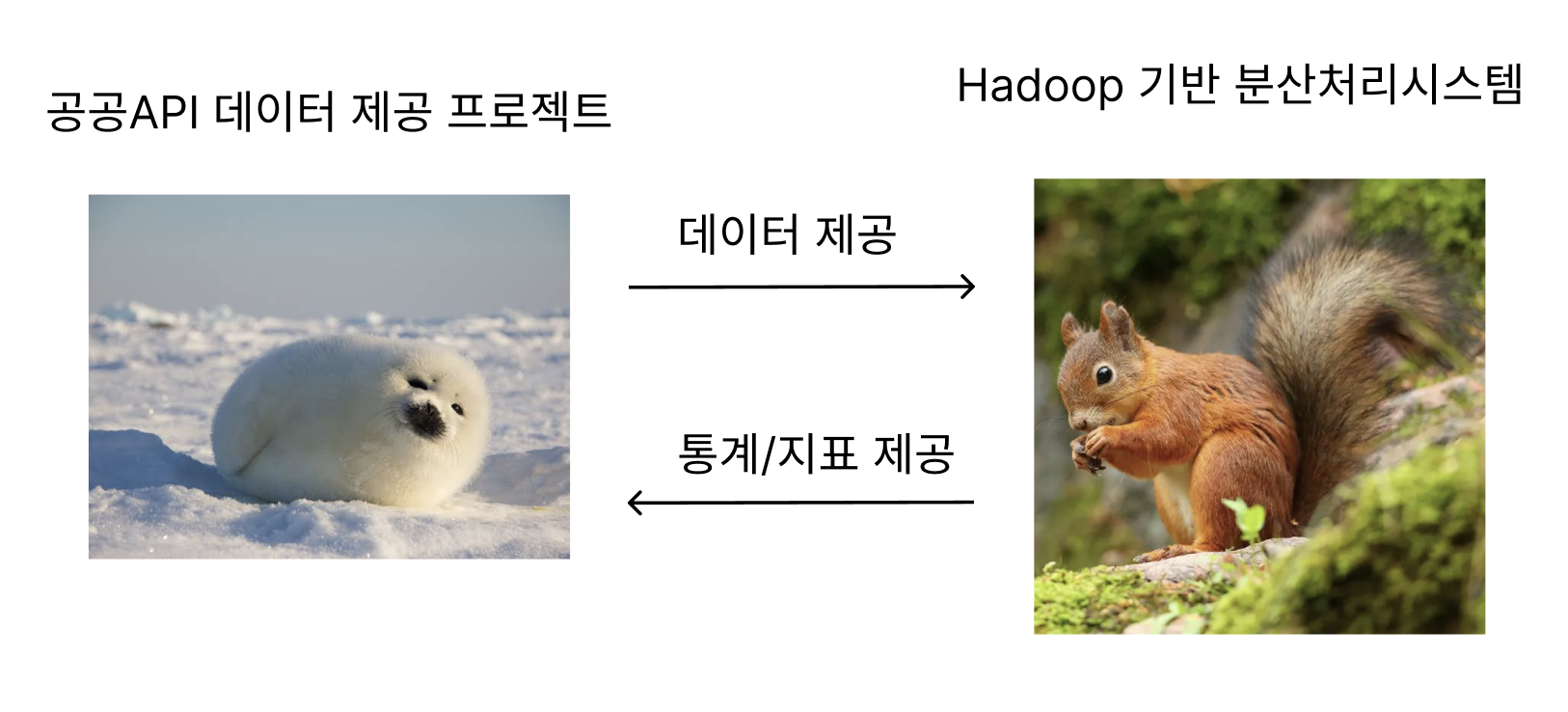
데이터 분산 처리를 통한 유의미한 데이터를 추출해 내고, 이를 제공하기 위한 처리 시스템을 구성한다. 기능은 다음과 같다.
- 원본데이터에서 필요한 데이터를 추출/가공하여 제공
- DW를 통한 지난 데이터의 통계 제공
- Hadoop 시스템의 활용을 통한 스택 경험
따라서 데이터들을 받아 통계/지표 등을 추출해 BE에 제공하는 시스템을 구성한다.
코어 스택
처음부터 모든것을 개발하지 않고, 기본 코어를 개발한 후 필요한 기능을 추가하는 방식으로 프로젝트를 키울 생각이다.
K8S
여러 프로그램을 사용해야 하기에 Container 기반 시스템이 필요했다.
Docker를 사용해도 되지만, 오케스트레이션을 경험하기 위해 K8S를 선택
Hadoop Core
데이터를 저장한다.
Spark
MapReduce보다는 Spark를 사용하기로 했다.
무엇보다 빠르고, M2air 기준 램16기가라서 용량도 넉넉하다.
Hive
지금 사용하는 공공 데이터는 월별로 계속 나오기 때문에 DW를 구성해보기로 했다.
수개월치 데이터를 저장하면서 비교분석해보면 꽤 좋은 데이터를 얻을 수 있을것이라 예상된다.
DB는 기존에 사용했던 PostgreSQL을 사용한다.
AirFlow
월별 데이터 조회를 하기 때문에 Batch 작업이 주가 될 것이기 때문에
AirFlow를 활용한 처리 자동화 및 모니터링 툴을 활용.
이 외의 추가 : 모니터링 및 고급 쿼리
Prometheus/Grafana/ELK/Loki 등과 같은 모니터링/로그 툴과
Presto/Trino 등의 쿼리 툴을 시간이 되면 사용해보기로 함.
일단 기본적인 시스템을 구성하는것을 목표.
기능
백엔드 서버 DB
이번달 데이터/Hadoop 처리값을 저장하는 용도
프론트에서 데이터를 요청했을때 빠르게 반환하는것을 목표
HDFS
지난 모든 데이터의 장기 보관
Hive/Spark를 통한 분석 및 가공에 활용되는 기초 스토리지
Spark
HDFS에 저장된 데이터를 분산 처리하는 엔진
YARN을 통한 리소스 관리 하에 실행
Hive의 실행 엔진으로도 사용 (HiveQL 쿼리 가속)
처리 결과를 HDFS에 저장하고, Hive 메타스토어를 갱신해 DW 테이블로 관리
Hive
DW구성을 위한 용도
HDFS의 데이터를 SQL로 활용하기 위한 배치처리를 함
PostgreSQL을 활용해 HDFS파일의 메타데이터를 생성함
AirFlow
Batch 처리를 위한 용도
월별/주기적 ETL 파이프라인 제어 및 모니터링
K8S 설치
Hadoop의 여러 요소들을 사용하기 위해 우선 K8S를 설치해 주려고 한다.
찾아보니 설치방법이 정말 어려운데 DockerDesktop이 있으면 간단하다!
그냥 Docker Desktop에서 Enable K8S 버튼 딸-깍 누르면 설치가 된다.
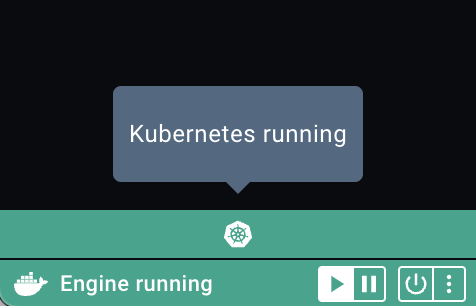

깔고나면 Kubernetes Running 이라는 글자가 뜨며 K8S가 설치되었다는 신호가 나오며 Terminal에서 K8S 노드가 떠있는 것을 확인 가능하다.
다시한번 Docker의 무서움을 보게 되었다..
Hadoop 설치 - Zookage(실패)
레퍼런스 : https://zookage.github.io/
Hadoop 뿐만 아니라 Spark/Hive도 같이 설치한다.
Hadoop을 또 언제 설치하나 하고 검색을 하다 Zookage라는 프로젝트를 발견했다.

Zookage는 쉽고 범용성 좋게 Hadoop을 깔수 있게 도와주는 프로젝트이다.
K8S가 있으면 사용 가능하다.

문서에 QuickStart가 있으니 따라하면 된다.
설치를 진행하면 Docker의 이미지파일이 계속 다운로드 되는데
속도가 매우 느려서 한참걸린다.
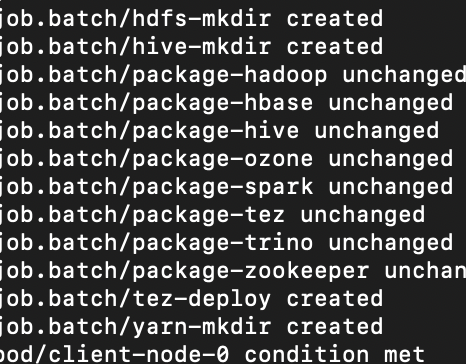
이렇게 로그가 계속 나오다가 멈추면 다운로드 속도가 느려서 그런거니 기다려보자.
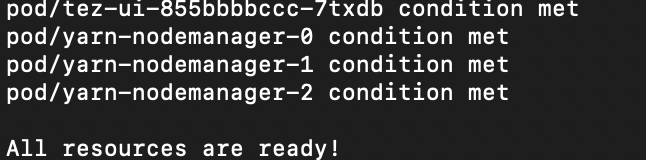
Docker 버전이 오래되서(아마 올해 3월) TLS 오류가 떴었는데 원인을 몰라서 한참 해맸다.
속도가 꽤나 느리긴 했지만 딸-깍 한번에 모든 설치가 완료되니 감사할 따름이다.
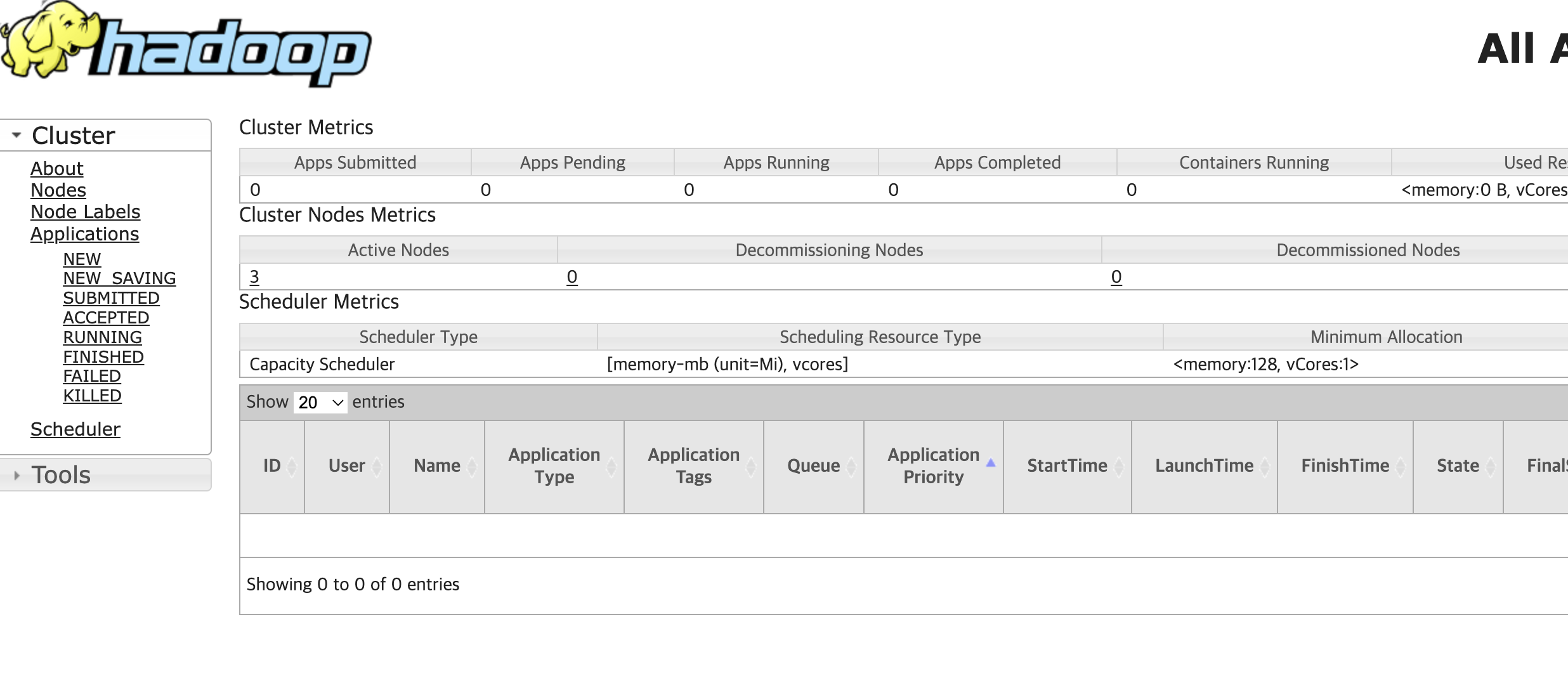
Hadoop Core 뿐만 아니라 여러 GUI 모니터링 툴도 함께 제공된다!
그리고 설치된 프로젝트는 다음과 같다.
- Apache Hadoop(HDFS, YARN, MapReduce)
- Apache HBase
- Apache Hive
- Apache Ozone
- Apache Spark
- Apache Tez
- Apache ZooKeeper
- Trino
있을건 다있다. Flink같은 다른 프로젝트를 사용하려면 따로 다운받아야 한다...
라고 했지만
hdfs-datanode-0 0/1 Running 14 (125m ago) 11h
hdfs-datanode-1 0/1 Running 15 (120m ago) 11h
hdfs-datanode-2 0/1 Running 3 (173m ago) 11h
hdfs-httpfs-c6fccdd7f-sjjhq 1/1 Running 2 (93m ago) 11h
hdfs-mkdir-t7d98 0/1 Completed 0 11h
hdfs-namenode-0 1/1 Running 1 (176m ago) 11h
A fatal error has been detected by the Java Runtime Environment:
#
# Internal Error (safepoint.cpp:384), pid=1, tid=0x00000040348be700
# guarantee(PageArmed == 0) failed: invariant
#
# JRE version: OpenJDK Runtime Environment (8.0_275-b01) (build 1.8.0_275-b01)
...
자바 충돌, datanode 미할당, 명령어 누락 등의 버그들이 터졌고, config를 새로 싹 뜯어고쳐야 하는 상황이 와서 그냥 다시 깔기로 했다.
K8S - Dashboard(실패)
Dashboard1 : https://kubernetes.io/ko/docs/tasks/access-application-cluster/web-ui-dashboard/
Dashboard2 : https://kindloveit.tistory.com/124
K8S Service 유형 : https://seongjin.me/kubernetes-service-types/
설치에 앞서서 K8S Dashboard를 먼저 설치하려고 한다.
위의 두 문서를 보고 하는데 한가지 문제가 발생했다.

Dashboard에 접속이 안된다...
이거때문에 ingress/metalLB 등의 여러방법을 시도했지만
하루를 잡아먹고 포기하게 되었다...
그 이유는
1. config 파일을 너무나도 많이 만져야 해서 감당이 안됨
2. 파일을 변경한다고 해도 되지 않음
문제의 원인은 간단했다.
K8S의 내부 노드를 외부에서 접근할 수가 없다.
포트포워딩을 수동으로 연결해주면 가능했지만
매번 그렇게 하는건 자신이 없었다..
멘탈이 와장창 깨지긴 했는데 한번더 도전해보자.
생각 정리 시간
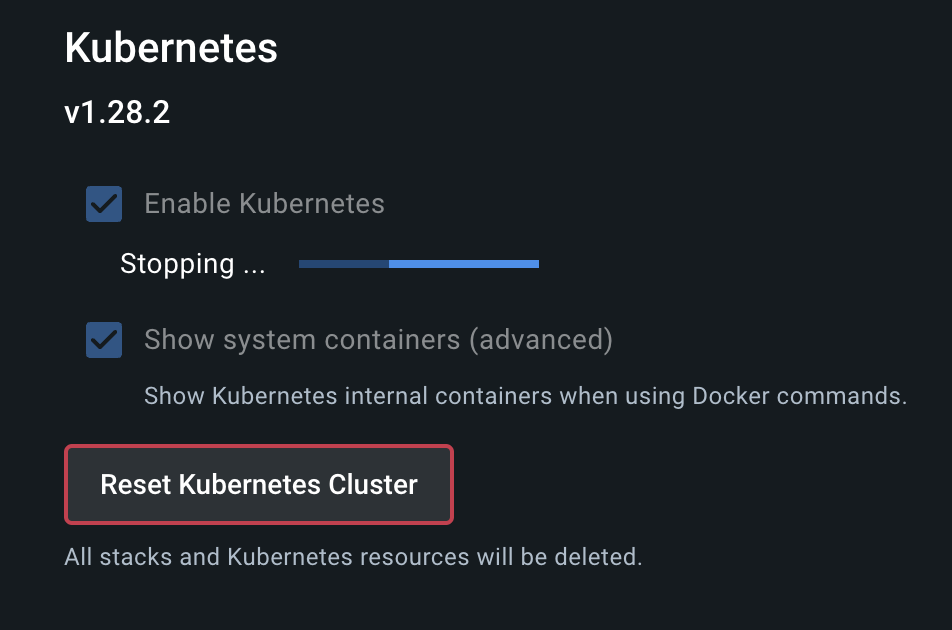
시원하고 깔끔하게 싹 밀었다.
내부 설정을 너무 많이 만졌고
싹다 지워도 컨테이너를 다시 가져오면 그만이다.
그리고 K8S 대시보드에 대해서 찾아봤는데
애초에 Proxy를 활용해서 접근하지, 외부에 공개하지 않는다.
자유롭게 접근하기 위해서 썼던 방법은
DashBoard의 접근을 위해 NodePort/Loadbalance 타입으로 바꾼다던가
ingress/MetalLB 등의 기술을 사용하는 등 억지로 끌어올리는 느낌이 강했다.
따라서 애초에 하지말라고 하는걸 하다가 시간날린 샘이 되었다..
K8S 모니터링 툴을 다른 오픈소스를 사용하기로 했다.
K8S에 대한 정보가 적다보니 하나하나 다 찾기가 너무 힘들다.
각각 다 공부하다가는 스택하나잡고 1달씩 걸릴 판이다..
그래서 여러 K8S monitoring tool 관련 글을 읽고 결론을 냈는데,
Prometheus + Grafana 조합이다.
그 이유는 다음과 같다.

(기업이 어떤 스택을 사용하는지 보여주는 사이트. Prometheus를 검색하면 위를 포함한 70여개의 기업이 검색됨.)
- 여러 공채를 볼때 압도적으로 많이 보였던 스택(모니터링 언급시 대부분 나옴)
- Prometheus + Grafana의 시너지
- 이를 제외하고도 여러 문서를 검색할때 자료양이 압도적으로 많음
Q : 다른 스택이랑 비교안하나?
A : 나도 진짜 비교하고 싶은데 시간도 없고 검색해도 뭐가뭔지 모름.
그런다고 자세하게 비교/분석 해놓은 자료를 찾지도 못했음.
=> 더이상 시간을 할당하기 힘들어서 선택함.
얼렁뚱땅 선택한거같이 보이긴 하는데 정말 고민 많이했고 현실적인 선택이라고 생각함.
Prometheus + Grafana의 장점과 단점을 보면
장점
(Prometheus)
- K8S와 완벽하게 통합
- 전용 쿼리언어 사용해서 복잡한 데이터를 분석/경향성 파악 가능
- 리소스 효율성이 뛰어남
- 알림 시스템 등을 사용가능
(Grafana) - 대시보드가 정말 강력함. 커스터마이징 가능
- 다양한 데이터 소스 지원(Prometheus 뿐만 아니라 엘라스틱서치, MySQL, Loki 등..)
- 플러그인 다양
이러한 장점으로 수평 확장이 유연하고 생태계가 엄청 큼.
멀티 클러스터 모니터링 가능하며 오픈소스이다.
단점
- 알림, 커스텀 메트릭 같은거 쓸때 초기설정이 복잡함
- 장기 데이터 저장하는데 힘듬. Thanos 같은 외부 스토리지 연동해야됨
- 빅데이터 처리시 I/O 많이 먹음
아니 빅데이터 처리용 플랫폼 만든다면서 I/O 많이먹는걸 써도 되냐? 라고 생각할수 있겠지만
빅데이터 input을 말하는게 아니라, 컨테이너에서 수집되는 데이터가 많아지는걸 의미함.
따라서 몇백 MB ~ 1자리 GB 수준은 별 상관없음.
Prometheus + Grafana
Prometheus 설치 레퍼런스 : https://whchoi98.gitbook.io/k8s/observability/prometheus-grafana
설치 방법을 쭉 따라갔다.
설치를 하다보면 서버가 Pending이 되는데
$ vi. values.yaml
server:
persistentVolume:
storageClass: hostpath #이 부분이 주석처리 되어있는데 수정
$ helm upgrade prometheus prometheus-community/prometheus -n prometheus -f values.yaml
# 이후 yaml 설정을 업데이트
values.yaml 파일로 들어가서 storageClass를 hostpath로 바꾸면 된다.
pvc/pv?? : https://kubernetes.io/ko/docs/concepts/storage/persistent-volumes/
- 컨테이너의 파일은 임시적이기 때문에 컨테이너가 crash될때 파일 손상이 발생한다.
- Pod에서 같이 실행되는 컨테이너 간에 데이터 공유가 필요하다.
이러한 이유에 의해서 일시적인 볼륨이 필요한데, 그러한 볼륨을 지정해주지 않아서 서버가 실행되지 않았던 것이다.
따라서 storageClass를 hostpath로 바꿨다.

주의해야 할 점은 hostpath는 보안상의 위험이 있다는 것이다.
이번 프로젝트에서는 K8S를 Local 환경에서만 돌리지만
만약에 Cloud 등의 배포환경에서는 다른 방안을 선택하는게 좋다.
접속완료!
Grafana도 마찬가지로 설치한다.

$ helm upgrade grafana grafana/grafana -n <실제-namespace> -f values.yaml위에서 설정했던 values를 grafana에도 적용한다.
나는 namespace를 grafana로 적었다.

그런데 grafana가 cluster ip를 할당받아서 외부 ip가 닫혀있는 상태이다.
$ kubectl get svc -n grafana
따라서 grafana의 타입을 LoadBalancer로 바꿔주고,

IP를 할당받고 LocalHost로 접속하면..!
접속완료!
만약 레퍼런스의 글을 그대로 따라했다면 username과 password는 다음과 같다.
username = admin
password = 1234Qwer
웰컴 페이지 까지 접속 가능해졌다.
이후 import dashboard를 들어가서
레퍼런스의 글을 쭉쭉 진행해 준다.
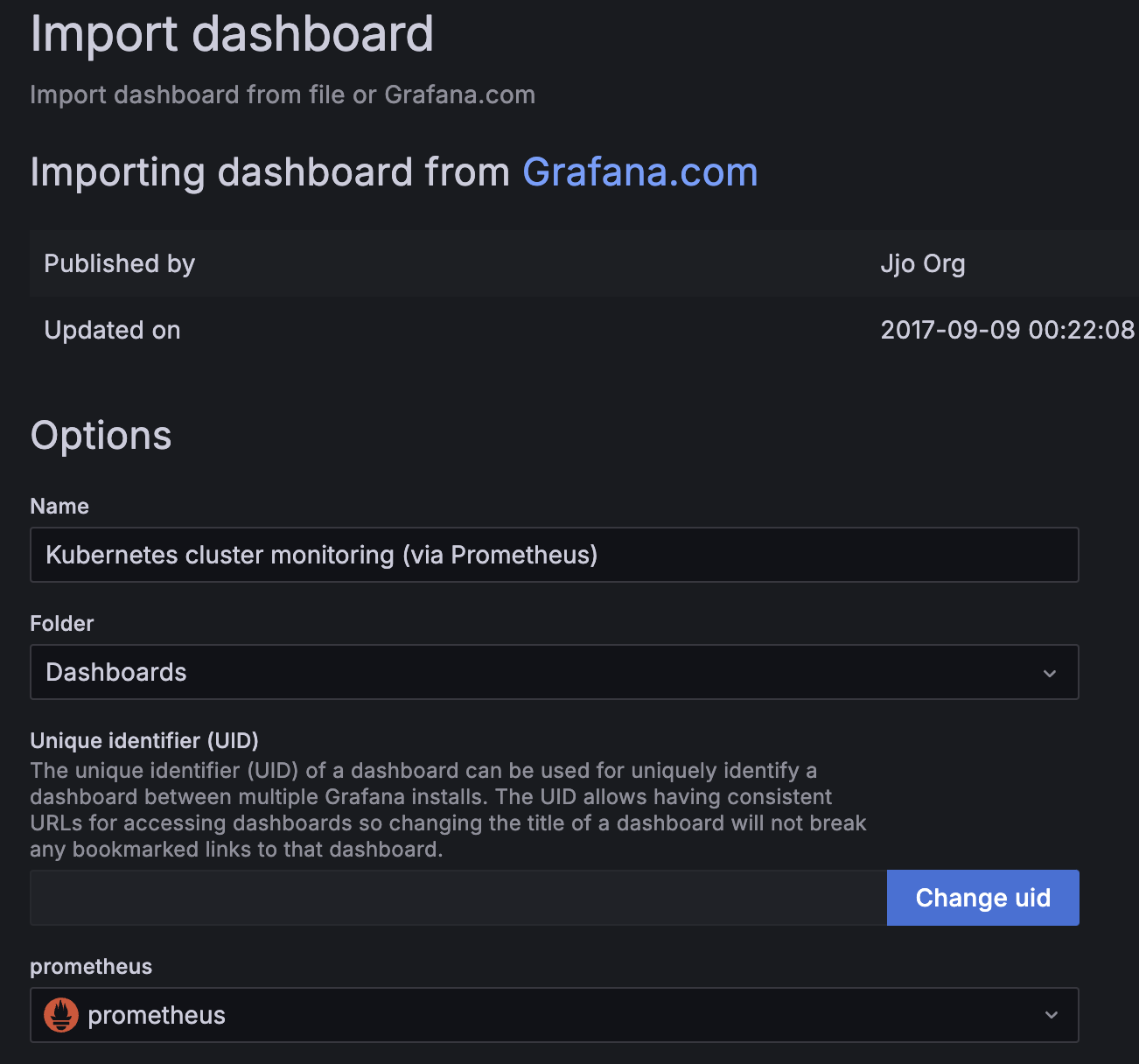
그리고 import 하면..!
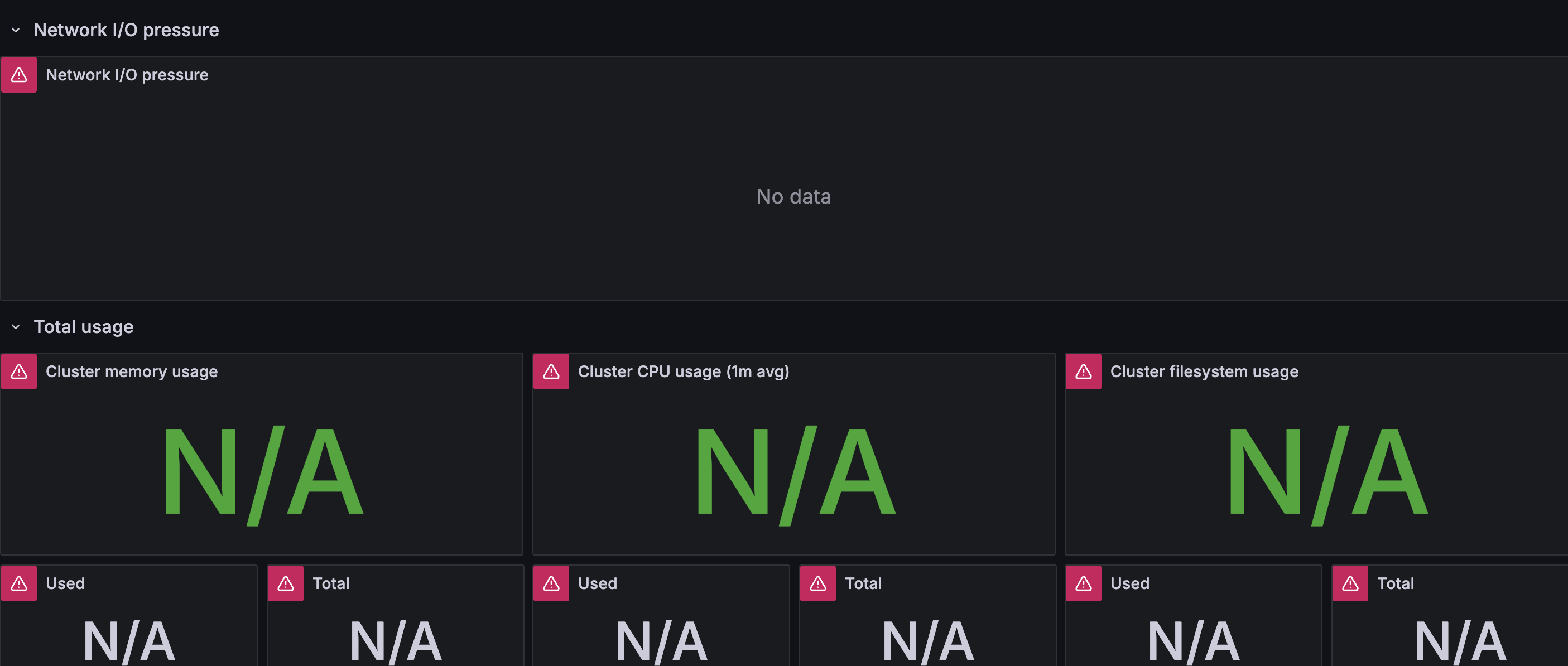
No Data가 뜬다.
그 이유가 뭔가하니 Grafana에서 prometheus에 직접 연결해야 된다고 한다.
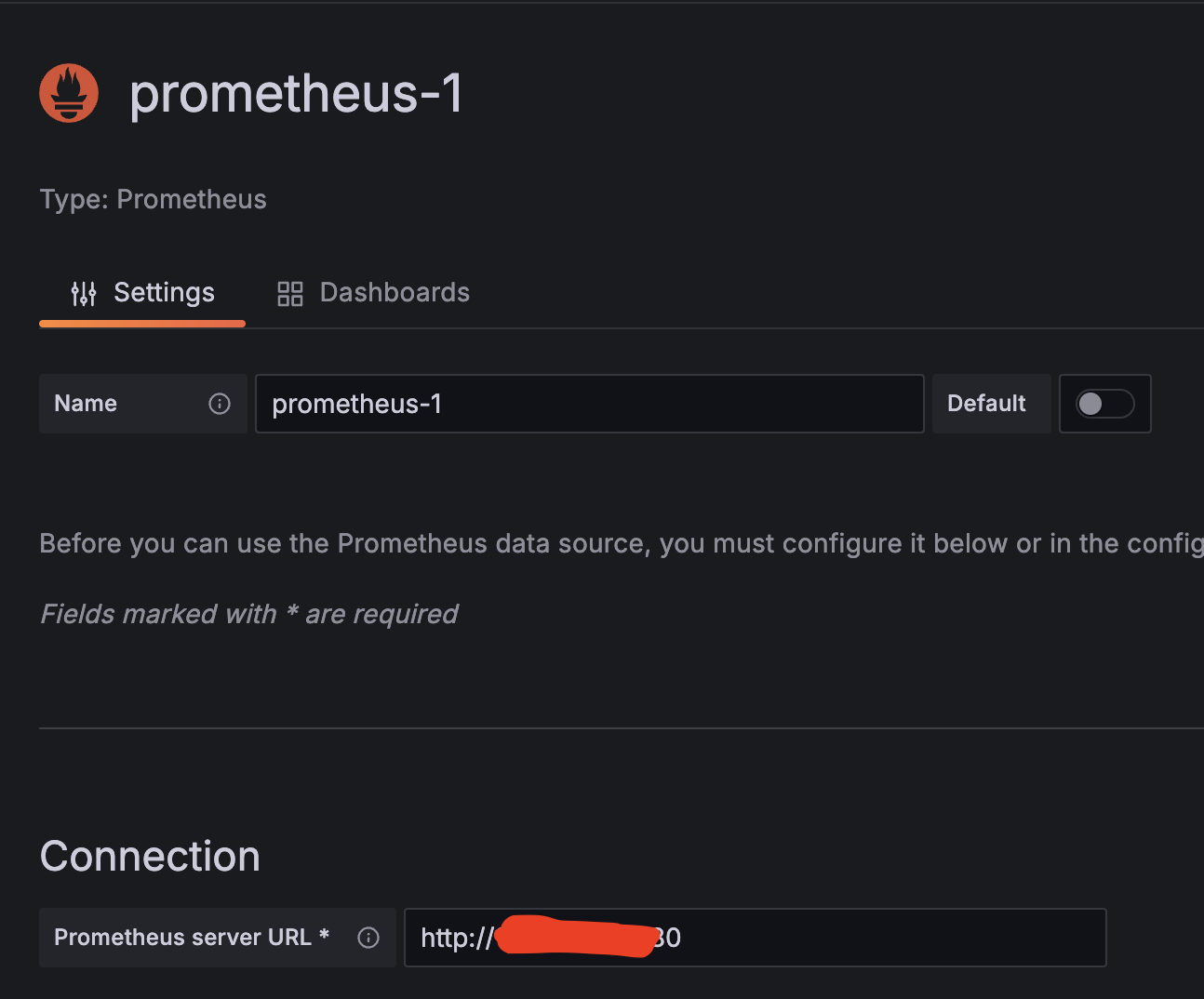
그래서 프로메테우스 서버를 NodePort로 바꾼뒤 DNS로 접근하게 설정하면
연결 확인이 되었다는 글이 뜨면서
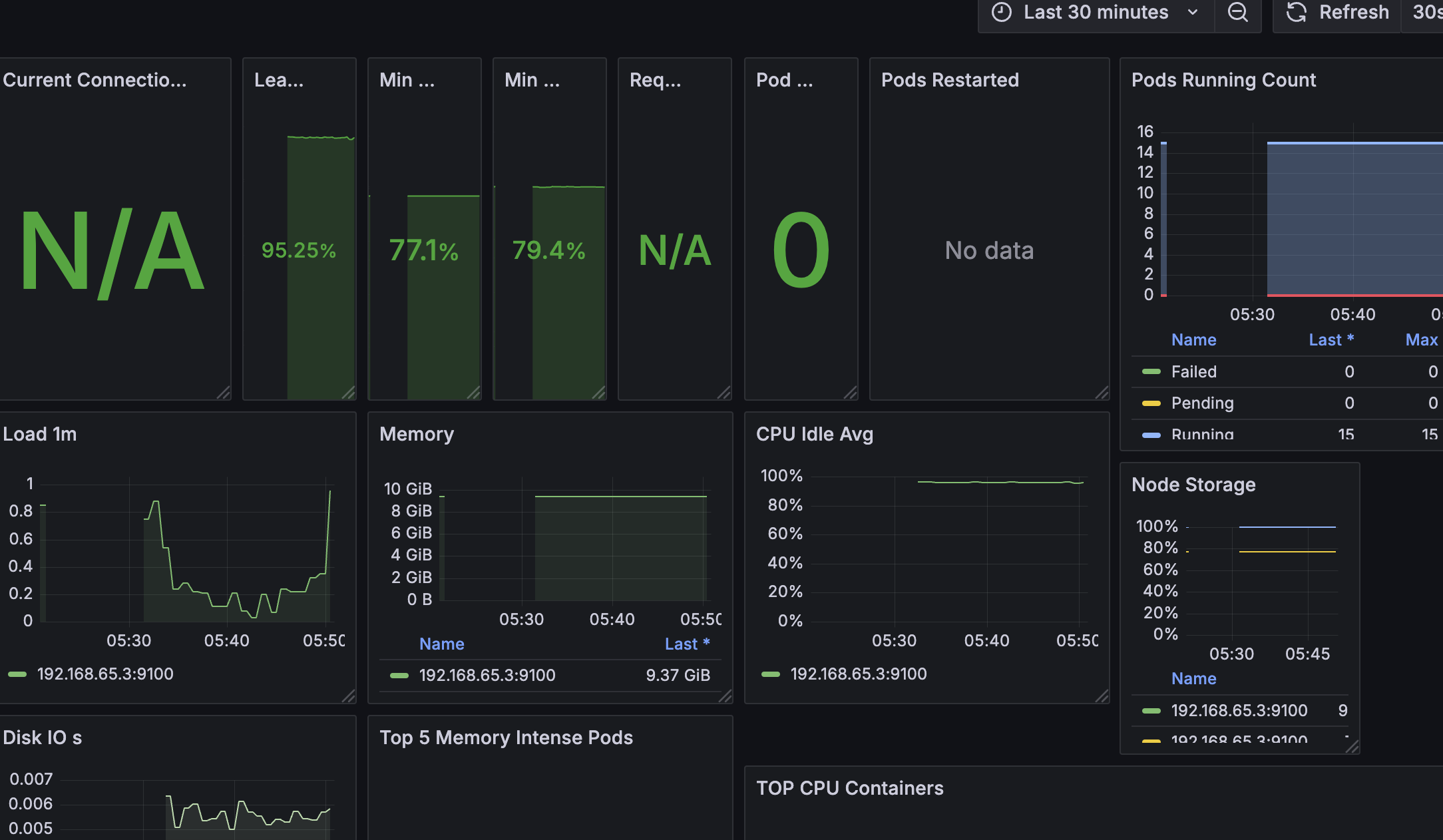
드디어 성공!!
helm - Hadoop 설치
hadoop : https://artifacthub.io/packages/helm/apache-hadoop-helm/hadoop
설치는 간단하다.
위 링크를 타고 들어가면 이런 사이트가 나온다.
사이트의 오른쪽에 있는 INSTALL이라는 버튼을 누르면 아래와 같은 페이지가 열리는데
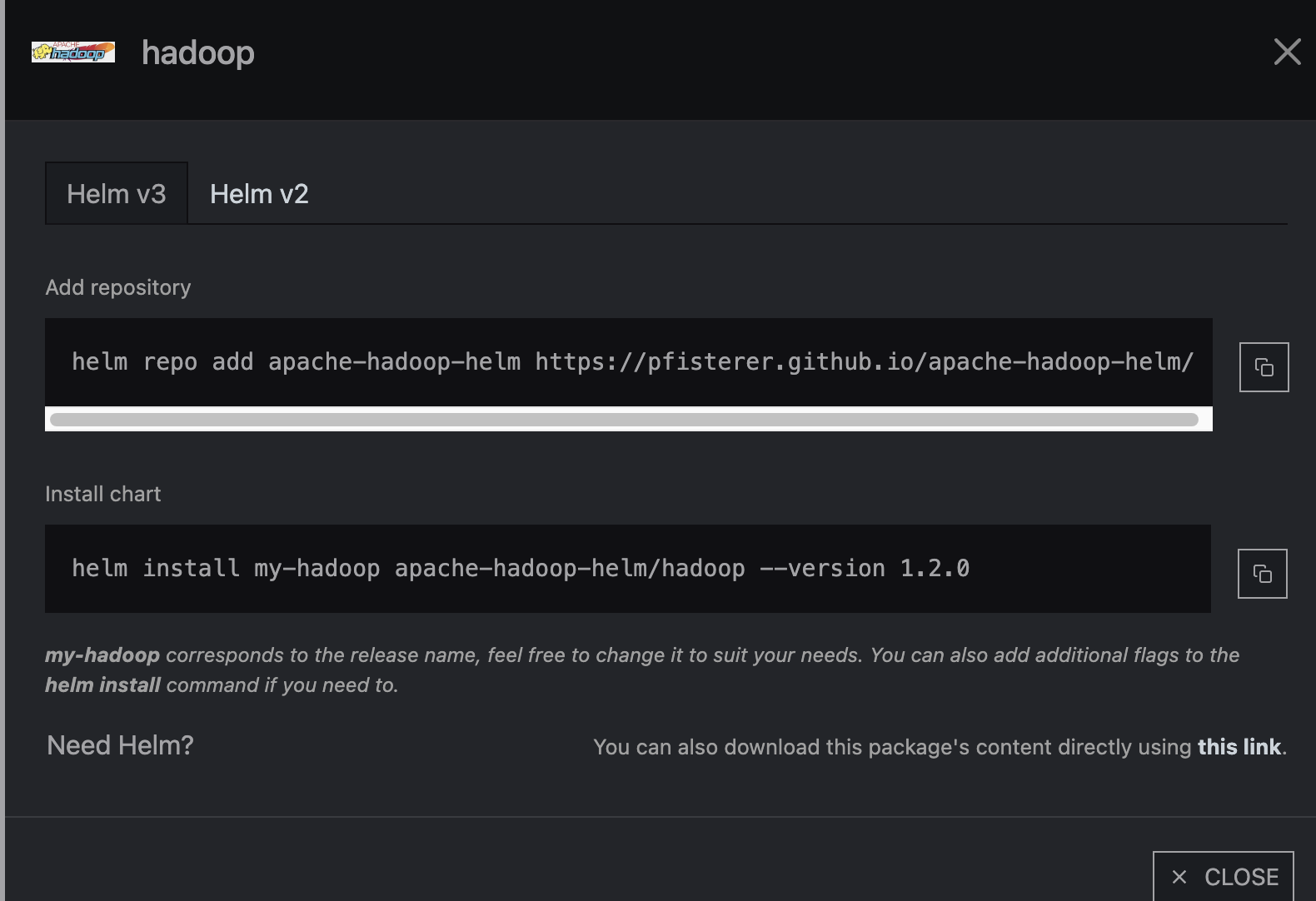
- K8S가 설치되어 있는 상태
- Helm이 install 되어있는 상태
에서 위/아래를 순서대로 CLI에 입력하면 된다.
$ helm install my-hadoop apache-hadoop-helm/hadoop --version 1.2.0
NAME: my-hadoop
LAST DEPLOYED: Sat Dec 21 20:12:07 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. You can check the status of HDFS by running this command:
kubectl exec -n default -it my-hadoop-hadoop-hdfs-nn-0 -- /opt/hadoop/bin/hdfs dfsadmin -report
2. You can list the yarn nodes by running this command:
kubectl exec -n default -it my-hadoop-hadoop-yarn-rm-0 -- /opt/hadoop/bin/yarn node -list
3. Create a port-forward to the yarn resource manager UI:
kubectl port-forward -n default my-hadoop-hadoop-yarn-rm-0 8088:8088
Then open the ui in your browser:
open http://localhost:8088
4. You can run included hadoop tests like this:
kubectl exec -n default -it my-hadoop-hadoop-yarn-nm-0 -- /opt/hadoop/bin/hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.2-tests.jar TestDFSIO -write -nrFiles 5 -fileSize 128MB -resFile /tmp/TestDFSIOwrite.txt
5. You can list the mapreduce jobs like this:
kubectl exec -n default -it my-hadoop-hadoop-yarn-rm-0 -- /opt/hadoop/bin/mapred job -list
6. This chart can also be used with the zeppelin chart
helm install --namespace default --set hadoop.useConfigMap=true,hadoop.configMapName=my-hadoop-hadoop stable/zeppelin
7. You can scale the number of yarn nodes like this:
helm upgrade my-hadoop --set yarn.nodeManager.replicas=4 stable/hadoop
Make sure to update the values.yaml if you want to make this permanent.그럼 위와 같은 텍스트가 주루루루룩 뜨면서 설치가 완료되었다고 뜨고
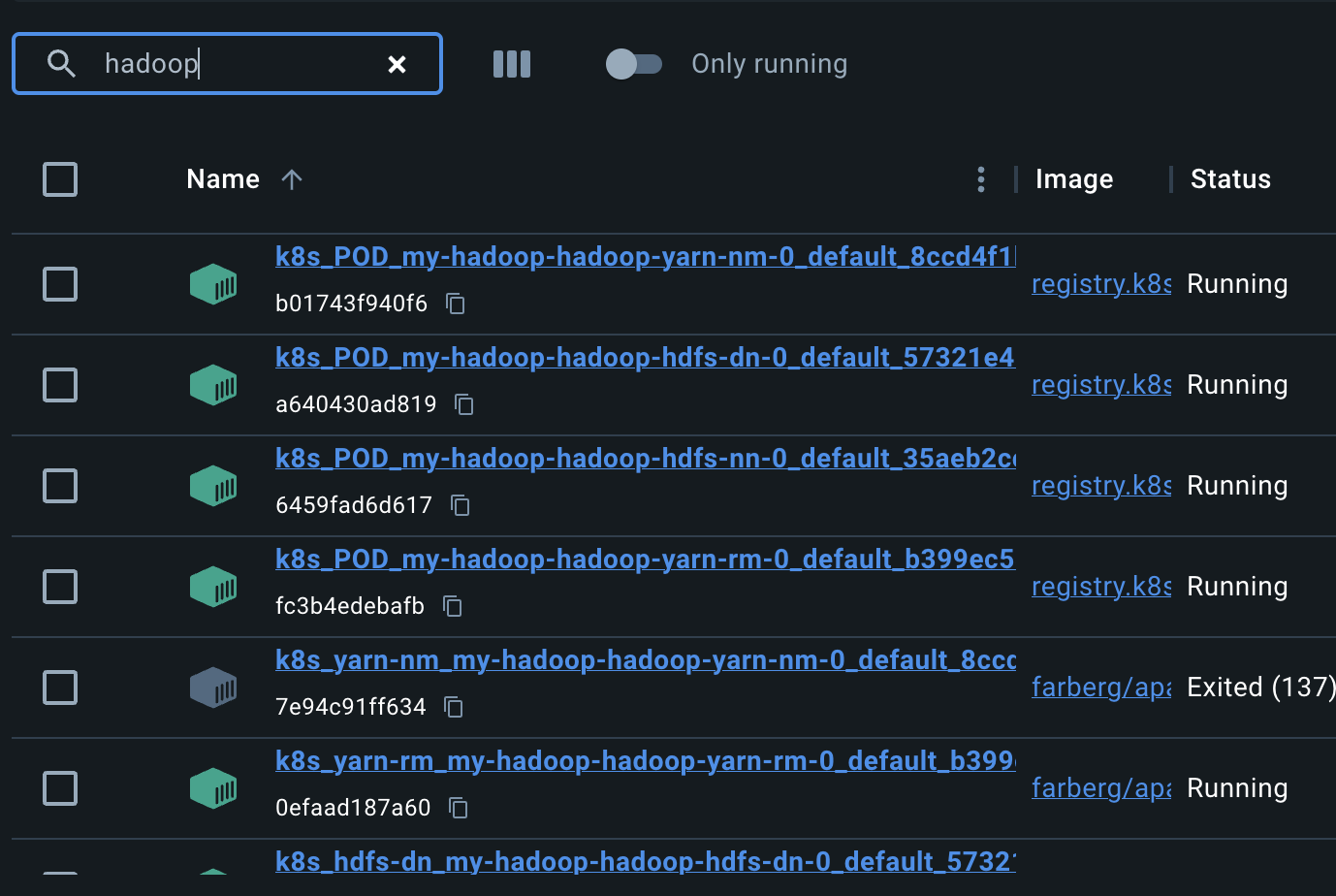
컨테이너가 자동으로 뜨면서 Hadoop이 실행된다.
nn/dn/nm/rm은 각각
- Name Node
- Data Node
- Node Manager
- Resource Manager
를 의미한다.
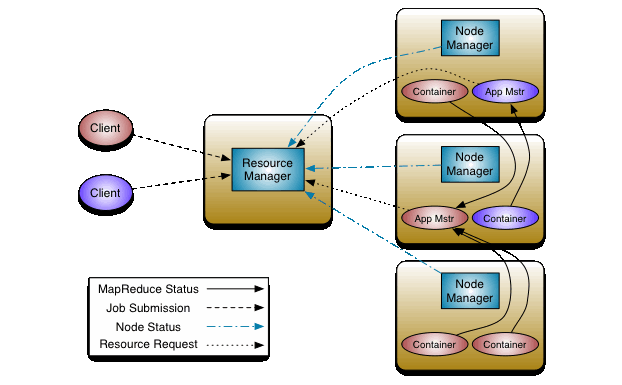
이거 생각하면 편하다.
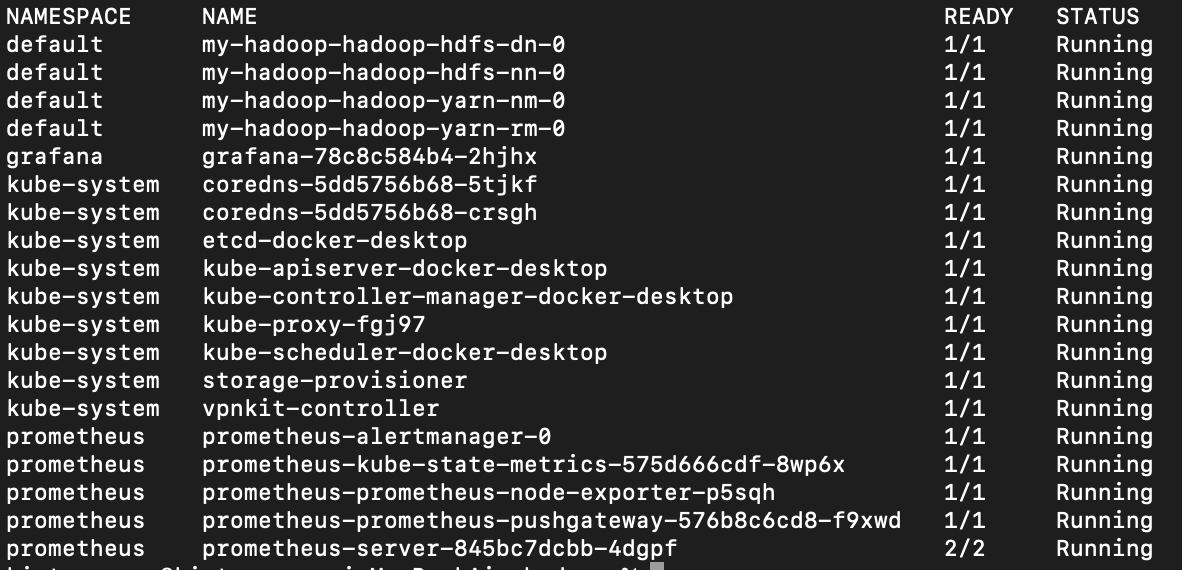
현재 실행중인 pod 목록은 다음과 같다.
- kube-system : K8S 운영 클러스터
- grafana/prometheus : 모니터링 툴
- hadoop : hdfs 파일시스템
Hive : https://artifacthub.io/packages/helm/bigdata-charts/hive
뭔가 쌔해서 호환표를 찾아봤다.

역시나 Hadoop의 모든 버전과 호환되는게 아니라, 호환되는 버전이 정해져 있었다.
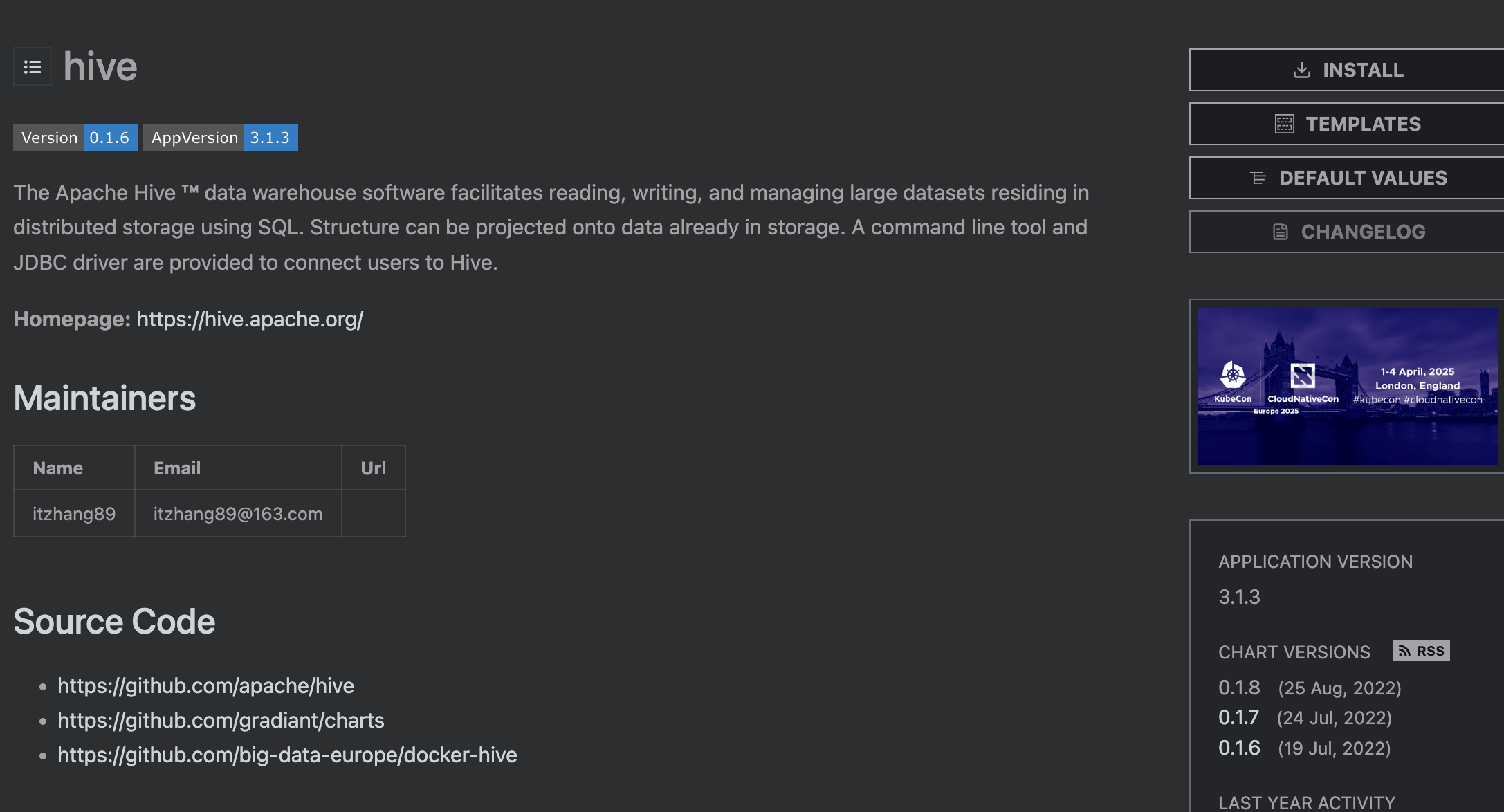
따라서 호환이 확인된 3.1.3버전을 사용했다.
Hive
24일)
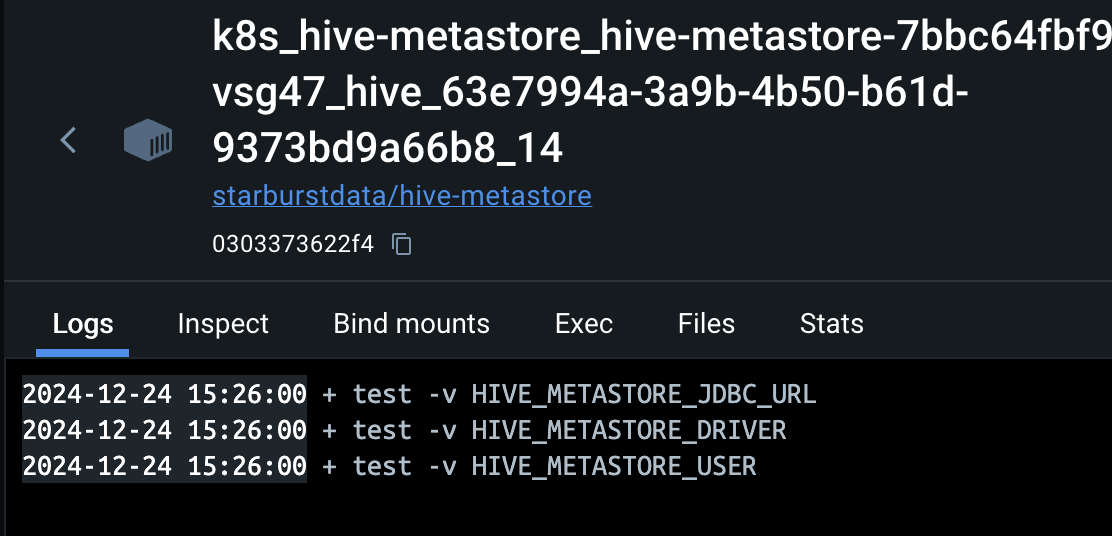
도대체 왜 안되는거니..!
3일째 원인 찾는중
26일)
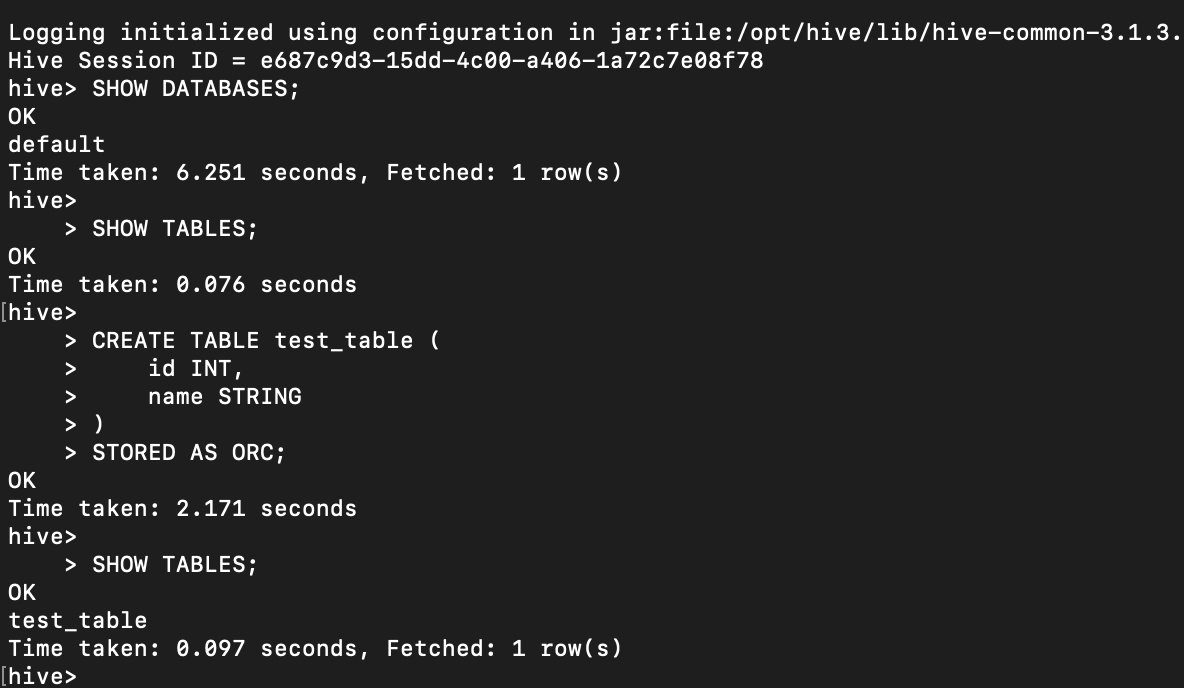
하.. 드디어 끝났다
거의 1주일 가까이 세팅만 했는데
드디어 환경 세팅이 끝났다.

원인을 알수없는 버그와
처음보는 환경, config/cli/yaml과의 싸움이 드디어 끝났다
