당분간 자주 애용할 것 같다..
▶ 왼쪽과 오른쪽을 구별하는 Teachable machine Model을
p5.js로 가져간 후, Arduino에 시리얼 통신으로 전송하여
LCD에 'Left'혹은 'Right'를 출력하게끔 만들고
해당 과정을 제시하는 블로그 글을 작성하고 댓글에 링크로 제출하세요.
1. 코드에 대한 설명이 있어야 합니다.
2. 코드를 작성하는 과정이 있어야 합니다.
3. 작동하는 영상이 포함되어야 합니다.
- 네이버 블로그, T스토리, 개인 웹사이트,
Github md file, Notion등 모든 블로그 형식의 사이트 링크
제출기한 : 10월 16일 월요일 오후 16시 30분까지
점수 : 제출 시 정성평가 +40점
Teachable Machine.. 정말 오랜만에 들어봤다..
정보 시간에 별의별 포즈와 사진들을 갖고 놀았던 기억이 새록새록 났다;;
물론 그렇다고 놀기만 한 건 아녔다!!
자.. 저 주소 뒤가 /image냐 /pose냐에 따른 결과물의 차이를 그대는 아는가??
물론 뭔가 이상하지 않은 이상 주소가 다르다!거나
페이지가 다르다!는 걸 모르진 않을 것이다.
하지만! 오늘 활동에 있어서 꼭 알아둬야 할 것이 있다!!
바로...
학습 방식이다!
- /image는 촬영된 샘플(이미지)들의 픽셀을 학습하고,
- /pose는 촬영된 샘플(이미지)에서 말 그대로 자세를 학습한다!!
그래서 이미지 학습의 경우 뒷 배경이나 캠의 위치 등의
사소한 요소라도 바뀌면 모델의 정확도가 떨어진다..
반면 포즈 학습은 진짜 자세를 학습하기에 이미지보단 덜 하지만,
(눈, 코, 입, 팔, 몸통 등의 특정 위치를 파악하는 방식)
이미지처럼 다양한 모습을 인식하지 못한다..
그렇기에 L&R을 구분하는 동작을 인식할 수 있는
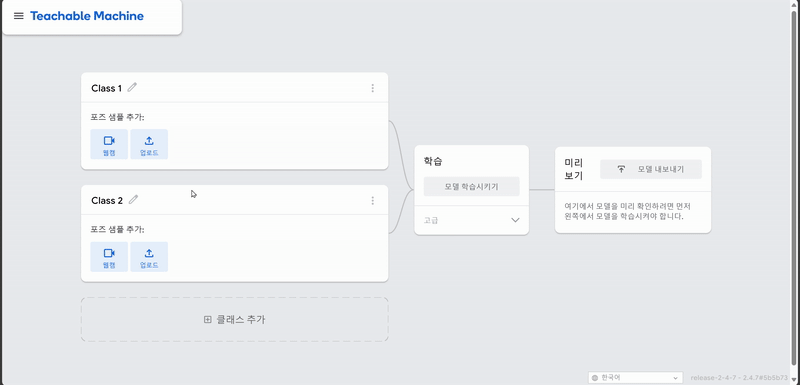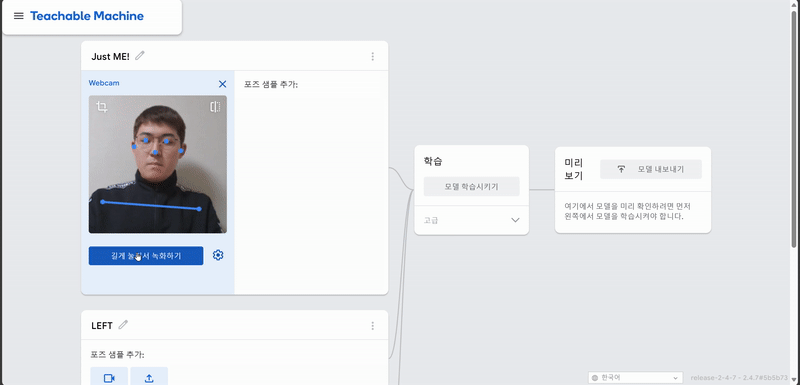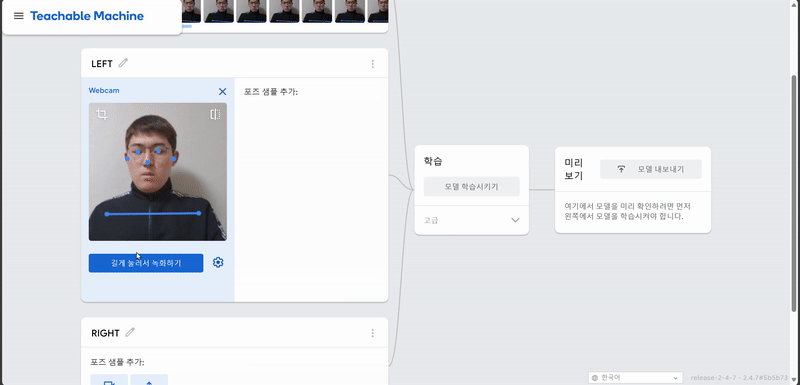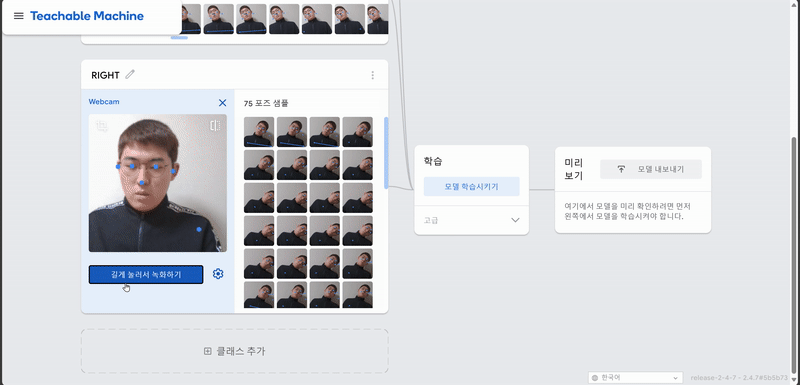
포즈 학습을 바탕으로 구현했다!
근데 이걸 p5.js와 아두이노에 활용할 수 있었다니... 쫌 쩌네??
1. Teachable Machine POSE 학습
결과
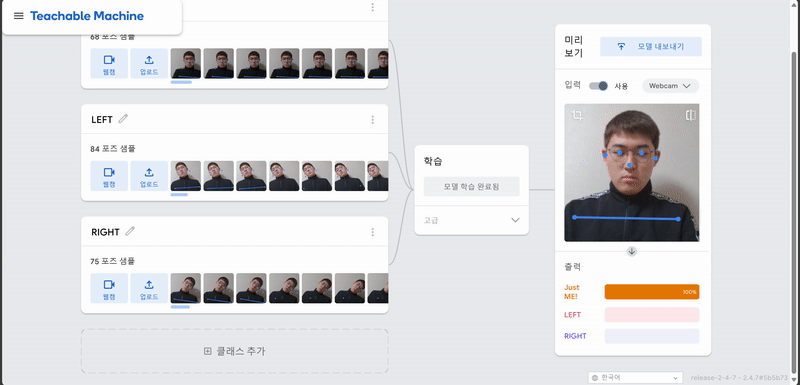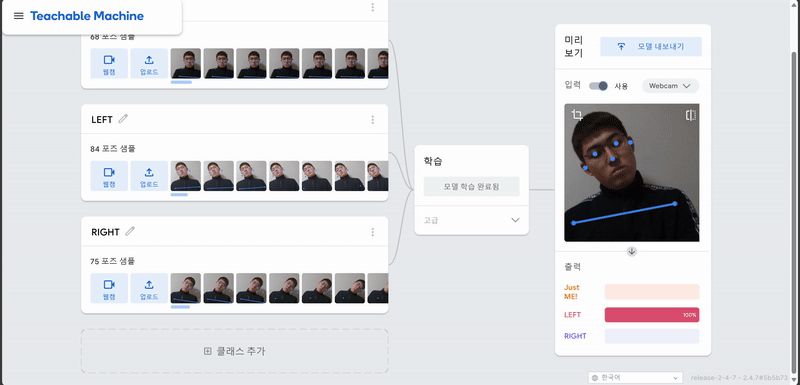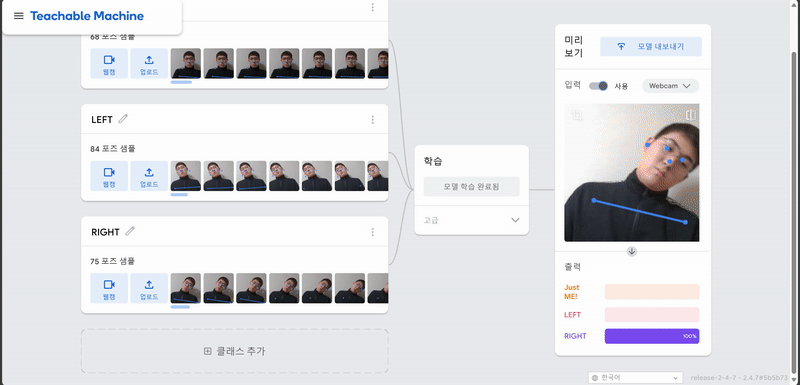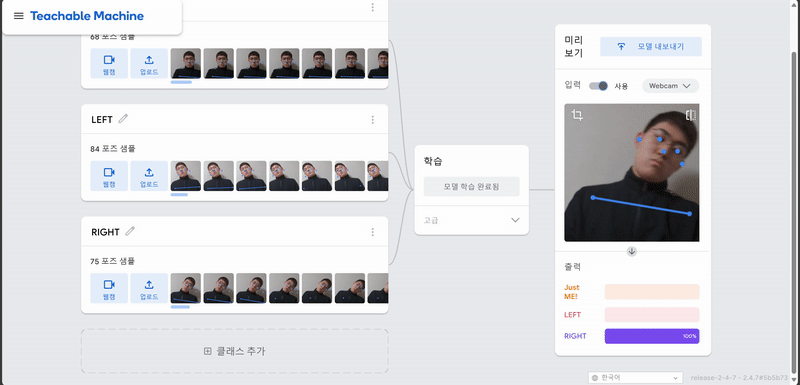
2. 아두이노와 p5.js에 코딩..
이게 정말 쉽지 않았다;; 이미지 모델은 굉장히 쉽고 예제도 많았는데...
출처 : https://m.blog.naver.com/icbanq/222934521411
- 아래는 변경된 코드!
아두이노 최종 코드
#include <LiquidCrystal_I2C.h>
LiquidCrystal_I2C lcd(0x27, 16, 2);
void setup() {
lcd.init();
lcd.backlight();
Serial.begin(9600);
}
void loop() {
// lcd.clear();나 delay(); 넣으면 제대로 동작 안함
if(Serial.available() > 0) {
char LMR = Serial.read();
switch(LMR){
case 'M' : // 中
lcd.setCursor(0,0);
lcd.print(" ! Just, ME ! ");
lcd.setCursor(0,1);
lcd.print("^^^^^^^^^^^^^^^^");
break;
case 'L' : // ←
lcd.setCursor(0,0);
lcd.print(" !LEeFT ");
lcd.setCursor(0,1);
lcd.print("<<<<<<<<<<<<<<<<");
break;
case 'R' : // →
lcd.setCursor(0,0);
lcd.print(" RigHT! ");
lcd.setCursor(0,1);
lcd.print(">>>>>>>>>>>>>>>>");
break;
}
}
else{
lcd.clear(); // Serial 포트 닫히면 초기화
}
}여기서부턴 국내 예제가 없어서 외국분들의 help가 필요했다..
근데 불러와야 하는 파일(index.html의 scripts)과 코드의 길이가 ㅎㄷㄷ;;;
- 아래는 '수정'된 코드!
p5.js 최종 코드
// sketch.js
const URL = "https://teachablemachine.withgoogle.com/models/iWCYDl95I/";
let model, webcam, ctx, labelContainer, maxPredictions;
let serial;
init();
async function init() {
// Serial 추가 (아두이노 LCD 표현 위해)
serial = new p5.SerialPort();
serial.open('COM9');
serial.clear();
// POSE Model
const modelURL = URL + "model.json";
const metadataURL = URL + "metadata.json";
// load the model and metadata
model = await tmPose.load(modelURL, metadataURL);
maxPredictions = model.getTotalClasses();
// 웹캠 설치
const size = 400;
const flip = true; // 좌우 반전
webcam = new tmPose.Webcam(size, size, flip); // 가로, 세로, 좌우 반전 여부
await webcam.setup();
await webcam.play();
window.requestAnimationFrame(loop);
// index.html에서 선언된 항목 불러오기
const canvas = document.getElementById("canvas");
canvas.width = size;
canvas.height = size;
ctx = canvas.getContext("2d");
labelContainer = document.getElementById("label-container");
for (let i = 0; i < maxPredictions; i++) {
labelContainer.appendChild(document.createElement("div"));
}
}
async function loop(timestamp) {
webcam.update(); // 새로운 Frame 불러오기
await predict();
window.requestAnimationFrame(loop);
}
async function predict() {
// Prediction #1: run input through posenet
// estimatePose : 이미지, 비디오, canvas, html 요소들 불러오기
const {
pose,
posenetOutput
} = await model.estimatePose(webcam.canvas);
// Prediction 2: run input through teachable machine classification model
const prediction = await model.predict(posenetOutput);
for (let i = 0; i < maxPredictions; i++) {
const classPrediction =
prediction[i].className + " : " + prediction[i].probability.toFixed(2);
labelContainer.childNodes[i].innerHTML = classPrediction;
}
// 추가
if (prediction[0].probability >= 0.90) {
serial.write("M"); // Just ME!
}
else if (prediction[1].probability >= 0.90) {
serial.write("L"); // LEFT
}
else if (prediction[2].probability >= 0.90) {
serial.write("R"); // RIGHT
}
// finally draw the poses
drawPose(pose);
}
function drawPose(pose) {
if (webcam.canvas) {
ctx.drawImage(webcam.canvas, 0, 0);
// draw the keypoints and skeleton
if (pose) {
const minPartConfidence = 0.5;
tmPose.drawKeypoints(pose.keypoints, minPartConfidence, ctx);
tmPose.drawSkeleton(pose.keypoints, minPartConfidence, ctx);
}
}
}<!-- index.html -->
<html>
<head>
<meta charset="UTF-8">
<title>Left or Right</title>
<!-- Teachable Machine POSE에서 업로드할 때 보였음 -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@1.3.1/dist/tf.min.js"></script>
<!-- 말 그대로 POSE 때문에 -->
<script src="https://cdn.jsdelivr.net/npm/@teachablemachine/pose@0.8/dist/teachablemachine-pose.min.js"></script>
<!-- 이건 이미지 모델에서 봤던.. -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/p5.js/1.1.9/p5.min.js"></script>
<!-- Serial 통신 때문에 -->
<script src="https://cdn.jsdelivr.net/npm/p5.serialserver@latest/lib/p5.serialport.js"></script>
</head>
<body>
<h1>p5.js + UNO R4, Teachable Machine</h1>
<p>Teachable Machine을 통해 Left, Right를 구별하고
시리얼 통신과 LCD를 통해 상태를 출력합니다.</p>
<div id="label-container"></div>
<script src="sketch.js"></script>
<div><canvas id="canvas"></canvas></div>
</body>
</html>왜 수정된 코드를 먼저 썼는가 함은..
2개의 사이트를 참고했는데 비슷하면서도 달라서;;
Teachable Machine POSE와 거의 유사한 환경!!
대부분의 코드가 여기서 사용됐지만,
필요하지 않은 부분을 삭제하고(mqtt, client, console 등) 수정!!
Teachable Machine보다 자세한데 눈 아픔;; (선 X)
- https://editor.p5js.org/zsk236/sketches/VIsHVCZJ4
- 각 부위별로 이름이 나옴 ex) LR 눈, 코, 입, LR 팔 ...
원래 여기 코드가 배웠던 코드와 유사해서 사용하려고 했는데...
→ 구현방식이 좀 달라서 합치기 어려움;;;
여기서 Serial 추출...!
(원래 여기다 선 그리는 것만 추가하려고 했음..)
구현 영상

