[The Matrix Calculus You Need For Deep Learning] Review - 1 Introduction
Abstract
이 자료는 딥러닝을 위한 모든 행렬 미적분에 대해서 설명하고 있다. 미적분 1에서 배운 것 이상의 수학 지식이 없다고 가정하고 관련된 수학지식들을 같이 설명한다. 이 자료는 신경망에 대해 알고 있고, 기초 수학에 대한 이해를 심화시키고 싶은 사람들을 위한 것이다.
참고: appendix에 여기서 설명하는 모든 주요 행렬 미적분 규칙과 용어를 요약해 두었습니다.
Introduction
딥러닝에 필요한 것은 scalar 미적분학이 아니라, Linear algebra와 multivariate calculus를 결합한 differential matrix calculus(미분행렬적분학?)이다.
음... 아마도 '필요'는 적합한 단어가 아닐 것이다. Jeremy's courses는 은 현대 딥 러닝 라이브러리에 내장된 자동 차별화 기능을 활용하여 최소한의 스칼라 미적분만으로 세계적인 딥 러닝 전문가가 되는 방법을 보여준다. 하지만 만약 여러분이 딥러닝이 어떻게 학습하게 되는것인지 알고 싶다면, 관련 논문을 이해하고 싶다면, 여러분은 행렬 미적분학 분야의 특정 부분을 이해할 필요가 있을 것입니다.
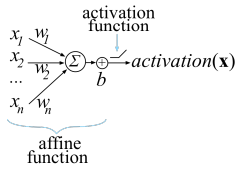
예를 들어, Neural Network의 하나의 unit에서 계산되는 activation은 dot product(from linear algebra)를 통해 계산된다.
input vector 와 weight vector 를 dot product하고 bias 를 더한다.
함수 는 unit의 affine 함수이며, 다음으로는 ReLU(Rectified Linear Unit)를 통해 계산한다. ReLU는 음수를 0으로 만든다.:
이러한 computational unit을 artificial neuron이라고 한다.
다음 그림을 보면 이해가 수월할 것이다.
Neural Network(이하 NN)는 이러한 여러 neuron의 모음으로 구성된 layer로 구성되어있다.
한 layer's unit의 activation은 다음 layer의 unit에 대한 입력(input)이 된다. 마지막 layer에서의 activation of unit을 해당 Neural Network의 출력(output)이라고 한다.
neuron을 Training 한다는 것은 N개의 inputs x에서 원하는 output을 얻을 수 있는 weights 와 bias 를 선택한다는 것을 의미한다. 이를 위해 loss function을 최소화한다.
loss function이란 NN의 final 와 (x의 원하는 output)의 차이를 비교하는 함수이다.
loss function에는 SGD(stochastic gradient descent), momentum, Adam 등이 있다. 이 loss fuction 들은 와 에 대한 activation(x)의 편미분(partial derivative)을 계산해야한다. 이것을 gradient 라고 부른다.
Training의 목표는 N개의 inputs x에서 loss function이 최소화하도록 와 를 점진적으로 조정하는 것이다.
만약 주의를 기울인다면, 가장 많이 사용되는 loss fuction의 scalar 버전인 MSE(Mean Squared Error)를 사용하여 gradient를 도출할 수 있다.
하지만, 이것은 단지 하나의 뉴런에서의 계산이고, NN에서는 모든 layer에서 모든 neuron의 w와 b에 대해 동시에 training을 수행해야 한다. 여러 개의 input x와 (잠재적으로) 여러 network의 output이 있기 때문에 vector 관련 function과 vector-valued function의 derivative에 대한 general rules가 필요하다.
즉, vector function과 vector-valued function을 같은 방법으로 미분할 수 있는 방법(수식)이 필요하다.
여기서는 vector, 특히 NN Training에 유용한 vector와 관련된 편미분(partial derivative)를 위한 몇 가지 중요한 rules을 설명한다. 관련된 학문은 행렬 미적분학이다. 행렬 미적분학의 일부분만 필요로 한다. 이 자료에서는 독자가 신경망에 대해 익숙하다고 가정하고 설명하기 때문에, 신경망에 익숙하지 않다면 https://course.fast.ai/ (Jeremy's course)의 Part1을 학습한 후에 이 글로 돌아오라고 조언한다. 수학은 문맥을 알고 공부할 때 이해가 더 잘된다고 한다.
Reference
본 포스팅은 The Matrix Calculus You Need For Deep Learning를 읽고 정리하였습니다. 저작권 관련 문제, 내용 수정 등 기타 문제사항 발생 시 댓글 남겨주시면 확인하고 피드백하겠습니다.
