[논문리뷰]Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning(NeurIPS 2022)
논문 리뷰
Abstract
1. Introduction
2. Background
2.1. Few-shot in-context learning (ICL)
2.2. Parameter-efficient fine-tuning
3. Designing the T-Few Recipe
3.1. Model and Datasets
3.2. Unlikelihood Training and Length Normalization
3.3. Parameter-efficient fine-tuning with
3.4. Pre-training
3.5. Combining the ingredients
4. Outperforming ICL with T-Few
4.1. Performance on T0 tasks
4.2. Comparing computational costs
4.3. Performance on Real-world Few-shot Tasks (RAFT)
4.4. Ablation experiments
5. Conclusion
Self Q&A
Opinion
Abstract
Few-shot in-context learning(ICL)은 input의 일부로 소수의 training examples을 함께 제공하는 기법으로, pre-trained language models이 gradient-based training없이도 처음보는 task를 수행할 수 있도록 한다.
ICL은 한번의 prediction을 진행할 때마다 모든 training examples을 함께 입력으로 사용하기 때문에(즉 input sequence가 길기때문에) 상단한 연산량, 메모리, 저장공간를 필요로 한다.
Parameter-efficient fine-tuning(PEFT)은 ICL을 대체하는 패러다임이 될 수 있으며, 적은 숫자의 파라미터만을 훈련시켜도 unseen task에 대한 성능을 이끌어 낼 수 있다(즉, 대부분의 파라미터를 프리징하고 일부의 파라미터만을 파인튜닝하는 것만으로 모델 전체를 파인튜닝하는 것과 유사한 효과).
본 논문에서는 few-shot ICL과 PEFT을 엄격하게 비교하여, PEFT가 정확성뿐만 아니라 연산비용의 측면에서도 더 우수하다는 것을 입증했다.
그 과정에서, 본 논문에서는 새로운 PEFT 기법인 를 제안한다.
은 학습된 벡터를 통해 activation을 조절하여, 상대적으로 적은 양의 새로운 매개변수만 도입하면서도 더 강력한 성능을 달성했다.
논문에서는 또한 T0 모델을 기반으로 한 T-Few를 제안한다.
T-Few는 task-specific tuning이나 modifications 없이 새로운 task에 적용할 수 있다(training example을 이용한 task-specific한 학습은 이루어진다).
- modifications: 레이어 추가/제거/조정, 활성화 함수 변경, 다른 하이퍼파라미터 조정 등 구조적 변경
- fine-tuning: 파라미터 값의 직접적인 변경이 이루어지는 추가적인 학습
-> PEFT는, task-specific하게 fine-tuning하더라도 ICL에 비해 적은 연산량을 가지지만, 결국 ICL과 다르게 task-specific한 dataset을 필요. IA3는 ICL의 training example 숫자만으로 여러 task에 대해 좋은 성능을 기록하는 방법론이다는 의미
unseen tasks에 대한 T-Few의 효과를 평가하기 위해, RAFT benchmark에 적용시켜본 결과, 기존 SOTA 성능보다 6%높은 점수를 달성했으며, 이는 처음으로 human performance를 넘은 점수이다.
- 실험에서 사용한 모든 코드는 https://github.com/r-three/t-few 에서 확인할 수 있다.
1. Introduction
Pre-trained language models(LLM)이 자연어처리 분야의 초석이 된 덕분에, 목표 task에서 데이터 효율성을 획기적으로 개선할 수 있었다.
즉, 초기값으로 Pre-trained language models을 사용하여 적은 labeled 데이터만으로도 더 나은 결과를 얻을 수 있게 되었다.
그동안의 Pre-trained models을 이용한 일반적인 접근방식은 downstream task에 대한 fine-tuning을 진행하기 전에 초기값으로 Pre-trained model의 파라미터를 사용하는 것이었다.
이 방법을 통해 많은 task에서 SOTA를 달성할 수 있었지만, fine-tuning과정이 task-specific 하게 진행되었기 때문에(task-specific 데이터셋을 사용), 여러개의 task에 대해 학습을 진행해야 하는 상황에서는 실용적이지 않았다.
ICL
이에 대한 대안으로 등장한 접근방식이 in-context learning (ICL)이다.
ICL은 LLM에 prompted examples을 입력으로 함께 사용하여 downstream task를 수행하도록 유도하는 방법이다.
Few-shot prompting은 input-target pairs로 instructions(요구 task)와 examples(정답이 있는 예제)을 입력하면서, 마지막 prediction이 필요한 label이 없는 단일 example(정답이 없는 해결하고자하는 문제)를 입력하는 것이다.
- 즉, 내가 원하는 task(instruction)과 해결하는 예제(정답과 함께)를 함께 제공한 뒤 마지막에 풀고자하는 문제(정답없는 예제)에 대한 정답을 예측하게 하는 것
ICL은 추가적인 학습이 필요하지 않고 단일 모델만으로 다양한 tasks를 수행할 수 있다는 특성으로 인해, 최근 ICL에 대한 관심이 높아지고 있다.
**이러한 장점에도 불구하고, ICL은 심각한 단점이 존재한다.
- 첫째, 모델이 예측을 수행할 때마다 input-target pairs을 모두 처리하면 상당한 연산 비용이 발생
- 둘째, ICL은 일반적으로 fine-tuning에 비해 성능이 떨어짐
- 셋째, 프롬프트의 형식에 따른 예측 불가능성(어떤 프롬프트를 입력하느냐에 따라 예측값이 쉽게 달라짐)**
뿐만 아니라, 최근 연구에 따르면 ICL은 잘못된 label을 제공해도 잘 작동하는 것으로 나타나, (example에 대한)학습이 실제적으로 얼마나 이루어지고 있는지에 대한 의문이 제기되고 있다.
PEFT
parameter-efficient fine-tuning(PEFT)는, 최소한의 업데이트로 모델이 새로운 task를 수행할 수 있도록 하는 또 다른 패러다임으로, pre-trained model에서 소수의 추가적인/선택된 파라미터만 업데이트하여 fine-tuning하는 방법이다.
- 대표적인 방법 중 하나인 'adaptation'은 pre-trained model의 layer와 activations 사이에 학습 가능한 작은 feed-forward networks를 삽입하는 방법이다.
- 즉, pre-trained model의 weights는 고정해놓고 학습 가능한 작은 feed-forward networks만 아키텍쳐 중간 중간마다 추가함으로써 적은 수의 파라미터로 모델을 튜닝하는 기법이다.
PEFT를 적용하여 모델의 일부 파라미터(0.01%)만을 업데이트하거나 추가하는 것만으로, 전체 모델을 fine-tuning하는 것과 비슷한 성능을 기록했다.
또한, 특정 PEFT 방법(뒤에 나올 IA^{3})은 batch 내 다양한 examples을 각각 다르게 처리하는 mixed-task batches를 허용하기 때문에, multitask 모델에서 PEFT와 ICL을 같이 사용할 수 있다.
PEFT의 장점은 fine-tuning의 일부 단점(연산량)을 해결하지만(ICL에 비해), labeled 데이터가 거의 없는 경우 PEFT 방법이 잘 작동하는지(소수의 파라미터에 대해 fine-tuning이 잘 이루어질지)에 대한 관심은 상대적으로 적다(즉, task-specific 데이터없이, ICL처럼 traing example만으로 새로운 task에 대해서도 잘 적용하는 방법이 있을까에 대해 고민했다는 의미).
본 논문의 주요 목표는 사전 훈련된 모델을 새로운 task에 대해 파라미터를 극히 일부만 업데이트하면서도, 새로운 unseen task에서 강력한 성능을 달성하는 '레시피(모델, PEFT 방법, 하이퍼파라미터)'를 제안해 이 격차(필요 dataset의 크기)를 줄이는 것이다.
특히, 논문에서는 multitask가 혼합된 prompted datasets을 fine-tuned한 T5모델의 변형인 T0 모델을 기반으로 접근했으며, classification과 multiple-choice(답이 2개 이상) tasks의 성능을 개선하기 위해, unlikelihood(regularization)과 length normalization-based loss terms을 추가했다.
또한, 중간 activations을 학습된 벡터로 곱하는 PEFT 방법인 을 소개한다.
는 논문에서 제안하는 PEFT의 방법 중 하나로, full-model fine-tuning보다 최대 10,000배 적은 파라미터만을 업데이트하면서 더 높은 성능을 달성했다.
또한 논문에서는 fine-tuning 전에 파라미터를 pre-training 하는 것의 이점을 입증했다.
기법을 사용하여 만든 'T-Few'라고 이름 붙인 '레시피(앞에서 언급한 레시피)'는 ICL보다 훨씬 뛰어난 성능을 보이며(심지어 16배 더 큰 모델에 비해서도), real-world few-shot learning benchmark인 RAFT(multitask datasets)에서, 처음으로 인간을 능가하는 성능을 보였다.
T-Few는 ICL보다 훨씬 적은 연산량을 필요로 할 뿐만 아니라, inference과정에서 mixed-task batches(batch 내 다양한 examples을 각각 다르게 처리)를 허용한다.
2. Background
Sec 2에서는 ICL과 PEFT의 연산량, 메모리, 저장공간에 대한 특성에 다룬다.
실제 비용은 구현과정과 하드웨어에 따라 달라지므로, 연산 비용에 대해서는 FLOPs, 메모리와 스토리지의 경우 bytes 단위로 비용을 설명한다.
이 장에서 말하고자 하는 바는, PEFT이 ICL에 비해 적은 연산량으로 높은 정확도를 기록했다는 점이다.
2.1. Few-shot in-context learning (ICL)
2.2. Parameter-efficient fine-tuning
3. Designing the T-Few Recipe
PEFT는 모델이 상대적으로 적은 저장공간과 연산비용으로 새로운 task에 대해 적용가능하게 하므로, ICL의 유망한 대안이 될 것이라고 생각한다(하지만 task-specific datsets이 필요).
본 논문의 목표는 모델이 새로운 task에 대해서 적은 labeled 데이터만으로도 높은 정확도를 달성하도록 하면서, inference 과정에서 mixed-task batches를 가능하게 하며 최소한의 연산량과 저장공간을 사용하는 '레시피'를 찾는 것이다.
'레시피'는, 어떤 새로운 task에 대해서도 모델 구조와 하이퍼파라미터 설정의 manual tuning없이(즉, task 맞춤 조정없이) 뛰어난 성능을 보이도록 하고자 한다.
이는, 평가에 사용할 수 있는 labeled 데이터가 제한적인 few-shot 환경에서 현실적인 옵션이다.
3.1. Model and Datasets
pre-trained 모델로는, 적은 labeled 예제를 이용해 fine-tuning 했을 때 높은 성능을 달성하는 모델을 선택해야 한다.
다양한 pre-trained 모델에 PEFT 방법을 적용한 예비 실험에서, T0의 성능이 가장 우수했다.
T0은 대규모 unlabeled 텍스트 데이터에 대해 masked language modeling을 통해 사전 학습된 encoder-decoder Transformer 모델인 T5를 기반으로 한 모델이다.
T0은 T5모델을 zero-shot 일반화를 가능하게 하기 위해, multitask mixture datasets에 대해 fine-tuning하여 만들어졌다.
T0은 T0-3B버전과 T0-7B버전 등이 있으며, 본 논문에서는 T0-3B를 사용했으며 이하 T0라고 부르겠다.
실험에 사용한 모든 모델과 실험은 Hugging Face Transformers를 사용했다.
T0모델이 zero-shot 일반화을 위해 설계되었다고 하지만, few labled examples만으로 fine-tuning을 진행했을 때 강력한 성능을 발휘하는지 실험을 진행했다(즉, T0은 일반화를 위해 만들어진 모델이지만, 추가적으로 few example을 이용해 task-specific하게 학습을 진행해 조금이라도 높은 성능을 가진 모델을 기준으로 잡고 실험을 진행하려는 의도).
평가 과정에서 'rank classification'을 사용하는데, 이는 일반 classification 문제뿐만 아니라 multiple-choice 문제를 풀기 위한 장치로, 가장 확률값이 높은 class 순서대로 정답의 개수만큼 예측값을 사용한다.
3.2. Unlikelihood Training and Length Normalization
Unlikelihood Training
실험에 앞서 2개의 추가적인 loss terms을 추가했다.
Language models은 일반적으로 cross-entropy loss()를 사용한다.
평가를 위해 rank classification을 사용했는데, multiple-choice tasks에서는 모델이 correct choice를 할당하는 것과 incorrect choice를 할당하는 것을 모두 학습시킬 수 있어야 하기 때문에, 훈련 과정에서 이를 고려하기 위해 unlikelihood loss를 추가하는 것을 고려해야 한다(correct choice과 incorrect choice를 동시에 사용하기 위해, 정답이 나올 확률만 높이는게 아니라, 오답이 나오지 않도록 하는 확률도 높이기 위해 도입).
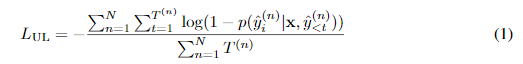
- N은 incorrect choice(N번째 incorrect choice)
- 는 N의 i번째 token
논문에서는 L_{UL}을 추가하면 모델이 incorrect choice에 더 낮은 확률을 할당하도록 훈련되어, correct choice가 가장 높은 순위에 오를 확률이 높아져 결과적으로 rank classification의 성능이 개선될 것이라는 가설을 세웠다.
Length Normalization
확률에 따라 각 choice 항목의 순위를 책정할 경우, 답변이 짧은 choice가 'faver(선호)'될 수 있다(모델이 각 토큰에 할당하는 확률이 1이하 이기 때문에 0.x가 계속 곱해지기 때문).
- 예제를 통한 설명(실제 chat-GPT처럼 확률에 따른 랜덤 생성이 아닌, 바로 Rank 기준 top-N개를 정답으로 사용하기 때문에 고려해야 하는 사항)
- 1) 즐겁다(0.7) = 0.7
- 2) 오늘(0.5) 기분이(0.4) 좋다(0.8) = 0.16
- 3) 오늘(0.5) 날씨가(0.3) 맑으니(0.6) 기분이(0.7) 좋다(0.8) = 0.0504
이 문제를 해결하기 위해 rank classification를 진행할 때, length normalization을 사용하는 것을 고려했다(GPT-3에서 사용한 방법을 인용).
- softmax cross-entropy loss을 최소화하는 방법을 통해 answer choice의 길이가 나올 확률을 높이는 작업
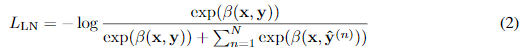
Final Loss
을 단순히 더한 값을 최종 Loss로 사용했다.
에 을 추가했을 때 정확도가 60.7%에서 62.71%로 향상되었고, 까지 추가한 결과 정확도가 63.3%로 향상되었다.
새롭게 추가한 Loss terms은 추가적인 하이퍼파라미터를 도입하지 않고도 성능을 향상시키기 때문에 레시피에 포함시키고 이후의 모든 실험에 사용했다.
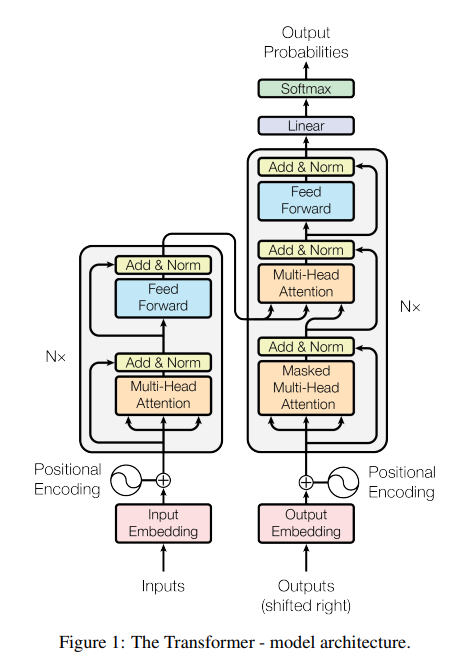
3.3. Parameter-efficient fine-tuning with )
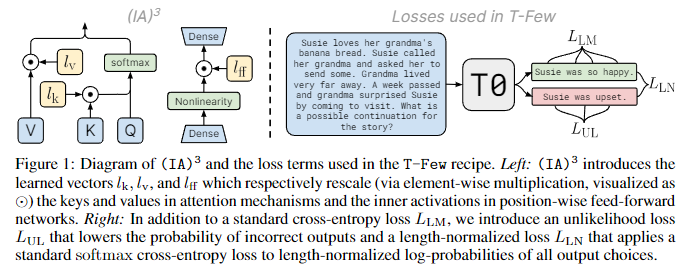
**few-shot ICL에 비해 효과적인 PEFT가 되기 위해서는 다음과 같은 조건을 만족해야 한다.
- 1) storage 및 memory 비용이 발생하지 않도록 가능한 한 적은 수의 파라미터의 추가나 업데이트가 이루어져야 한다.
- 2) 새로운 task에 대한 few-shot training 이후, ICL에 비해 높은 정확도를 달성해야 한다.
- 3) ICL의 주요 기능인 mixed-task batches를 허용해야 한다.**
그러나 뒤에서 다룰 내용에 따르면, 즉각적인 튜닝을 통해 합리적인 정확도를 달성할 수 없었고, 성능이 더 뛰어난 PEFT 방식은 mixed-task batches를 허용하지 않는다는 사실을 발견했다.
따라서 본 논문에서는 위 요구사항을 충족하는 새로운 PEFT 방법인 를 개발했다.
먼저, learned vector에 대한 모델의 activations의 element-wise multiplication(rescaling)을 조사해 보았다.
- 대표적인 방법은 'adaptation'
다만 저자들은 예비 실험에서, 트랜스포머 모델 각 층의 activation 세트에 대해 learned rescaling vector를 도입할 필요가 없다는 것을 발견했다.
대신, rescaling vectors를 self-attention 및 encoder-decoder attention mechanisms의 1)keys와 2)values, 3)position-wise feed-forward networks의 중간 activation에 도입하는 것으로 충분하다는 것을 알게 되었다.
구체적으로, 세 가지 learned vectors 를 attention mechanisms 다음과 같이 추가했다.
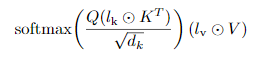
- key에 learnable rescaling vector()를 element-wise로 곱해준 뒤(모든 행에 대해 동일한 벡터가 곱해짐),
- 이 값에 Query를 곱한 뒤 softmax를 통과시켜 attention score의 distribution을 구하고,
- value에 learnable rescaling vector()를 element-wise로 곱한 값을 최종적으로 곱해준다.
position-wise feed-forward networks의 경우 기존 수식 에서 로 정의할 수 있는데(앞의 수식을 통과한 값이 ), 단순히 활성화함수를 통과한 값에 learnable rescaling vector를 element-wise로 곱해주고 이를 학습시키면 된다.
number of new parameters
3개의 learnable rescaling vector가 추가된 이후 파라미터 개수의 변화를 살펴보면, Transformer의 Layer block L개에 대해, encoder에서는 Layer마다 ()개의 파라미터가 추가되었고, decoder에서는 L개마다 ()의 파라미터가 추가되었다(decoder의 경우 self-attention과 encoder-decoder attention이 존재).
- T5 모델의 경우, 6(64+64+2048) + 6(2*(64+64)+2048) = 26800
논문에서는 이 방법을 Infused Adapter by Inhibiting and Amplifying Inner Activations라고 정의하며, 라고 부른다.
는 배치 내 각 activations의 sequence는 개별적이고 저렴하게 learned task vector를 곱할 수 있기 때문에 mixed-task batches를 가능하게 한다.
또한 모델이 single task에만 사용되는 경우에도, element-wise multiplication만 사용하지 않으면 되기 때문에, 에서 도입한 modifications(구조 수정)을 영구적으로 적용하여도 모델의 아키텍처가 변경되지 않도록 할 수 있다는 점도 주목할 만하다.
- 이는 에서 수행되는 element-wise multiplication이 항상 matrix multiplication과 함께 발생하기 때문이다.
- 즉, lWx = (l W)x이기 때문에 가능합니다.
- 가 성립하기 때문에,
- 단순히 만 사용하지 않을 경우 기존 모델의 형태(single task에 맞게 fune-tuning 가능)로 되돌릴 수 있다.
를 평가하기 위해, held-out tasks(적은 training examples만 있는 task)의 few-shot 데이터셋에 대해, T0-3B를 fine-tuning 하는 기존의 다양한 PEFT 방법(9개)과 비교해 보았다.
또한 full-model을 fine-tuning한 baselines도 비교에 포함하였다.
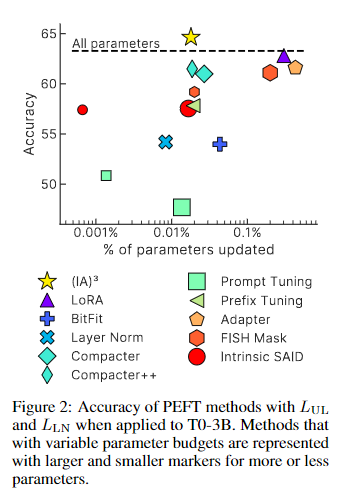
결과를 살펴보면, 는 유일하게 full-model-fine-tuning baseline보다 높은 성능을 달성한 모델이다.
다른 PEFT 방법들에 비해, 저 적은 파라미터 업데이트만으로 더 높은 정확도를 보여준다.
3.4. Pre-training
최근 연구에 따르면, prompt tuning에서 prompt embeddings을 pre-training하면, downstream few-shot tasks를 fine-tuning할 때 성능을 향상시킬 수 있다고 한다.
pre-training의 경우, 에서 추가한 새로운 파라미터를 T0 훈련에서 사용된 것과 동일한 multitask mixture 데이터셋을 이용해 사전 훈련을 진행했다.
사전훈련은 batch size 16으로 100,000 step 진행한 뒤, 각 개별 downstream 데이터 세트를 이용해 의 파라미터를 fine-tuning 했다.
pre-training을 통해 fine-tuned 정확도가 64.6%에서 65.8%로 향상되는 것을 확인하여 레시피에 추가했다.
3.5. Combining the ingredients
T-Few 레시피를 요약하자면 다음과 같다.
- Backbone으로 T0모델 사용
- downstream task에 대한 성능향상으 위해 을 추가
- 파라미터의 초기값 설정을 위해 T0의 학습에 사용했던 multitask mixture datasets을 사용해 pre-training을 진행(batch size 16으로 100,000 step)
- Loss로 (Language modeling loss), (unlikelihood loss), (length-normalized loss)
- batch size 8로 1000 steps, Adafactor optimizer, learning rate , linear decay schedule, 60-step warmup
강조하는 점은, 데이터 세트별(task 별로 다르게) 하이퍼파라미터 조정이나 modifications 없이 모든 downstream dataset에 정확히 동일한 방식으로 이 레시피를 적용할 수 있다.
따라서, 이 레시피는 validation sets이 적은 few-shot learning 환경에서 현실적인 옵션이 될 수 있다.
4. Outperforming ICL with T-Few
T0-3B를 이용해 설계한 T-few 레시피를 이용해, T0-11B와 성능을 비교해보았다(모든 task에서 동일한 레시피와 하이퍼파라미터 사용).
4.1. Performance on T0 tasks
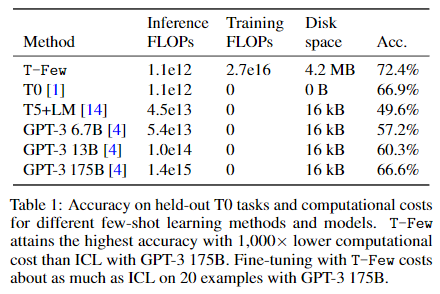
- few-shot ICL(GPT)이 zero-shot T0보다 성능이 낮음
- T-Few는 다른 모든 방법에 비해 크게 향상된 성능
- T-Few은 GPT-3 175B를 사용한 few-shot ICL에 비해서 16배 적은 파라미터로 6% 향상된 성능 달성
4.2. Comparing computational costs
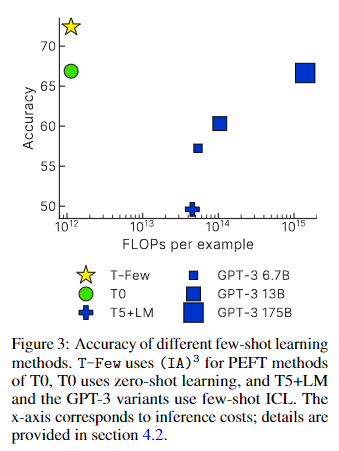
- FLOPs-per-token을 기준으로 비교
- T-Few는 ICL-based 모델을 넉넉하게 앞서 있음
- 상세 내용은 논문 참조
4.3. Performance on Real-world Few-shot Tasks )
real world에서 T-Few의 성능을 더 잘 평가하기 위해 RAFT 벤치마크에 대해 평가를 진행했다.
RAFT는 real-world 작업을 반영하는 것을 목표로 하는 11개의 'economically valuable' 작업으로 구성되어 있다.
각 RAFT 데이터 세트는 validation set 없이, 50개의 training examples만 존재한다(test set은 별도로 존재).
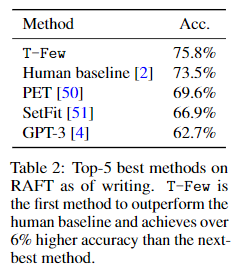
- top-5의 정확도를 비교(다른 방법들은 위 5개보다 낮음)
- T-Few는 정확도 75.8%로, SOTA를 달성하면서 처음으로 인간의 정확도 73.5%를 뛰어넘다.
- GPT-3 175B based ICL은 62.7%의 정확도만을 기록했다.
4.4. Ablation experiments
레시피의 각 ingredient를 추가한다고 해서(3.5에 정리), 모든 individual dataset의 정확도가 항상 향상되는 것은 아니지만, 각 ingredient는 데이터 세트의 평균 성능을 일관되게 향상시켰다.
5. Conclusion
논문에서는 parameter-efficient few-shot learning recipe T-Few인을 소개한다.
T-Few는 few-shot ICL보다 적은 연산량으로 더 높은 성능을 달성했다.
에서 사용된 T-Few는, 새로운 PEFT 방법으로 learned vectors을 사용해 inner activations을 rescales한다.
는 심지어 추가한 파라미터만을 업데이트하는 방법으로, full model을 fine-tuning하는 것 보다도 높은 성능을 기록했다.
또한 T-Few는 모델이 incorrect choices에 대해 더 낮은 확률을 출력하도록 유도하고, 여러 answer choices의 길이를 고려하기 위해 두 가지 추가적인 loss terms을 사용했다.
(task-specific 하이퍼파라미터 튜닝이나 기타 변경 없이) T-Few를 그대로 RAFT 벤치마크에 적용했을 때, 처음으로 인간을 넘어서는 성능을 달성했으며 이전 연구들을 큰 차이로 앞질렀다.
연산 비용에 대한 상세한 특성 분석을 통해 T-Few는 GPT-3를 사용한 few-shot ICL보다, inference 과정에서 1,000배 더 적은 FLOPs을 사용하며, 하나의 NVIDIA A100 GPU를 이용해서 훈련하는 데 30분밖에 걸리지 않는다.
논문의 모든 실험은 classification task에 대한 것이었기 때문에, 향후 연구에서는 summarization이나 question answering과 같은 생성 작업에 T-Few를 적용시킬 수 있을지에 대해서도 관심이 간다.
본 논문의 연구 결과가 LLM으로 few-shot learning을 잘 수행하는 방법에 대한 새로운 관점을 제시하기를 바란다.
Self Q&A
- 를 단순히 더하는 것은, 의 영향이 너무 크지않을까?
- (우연히)에서 answer choice의 length와 동일한 length의 incorrect choice가 여러개가 있다면, 잘못된 방향으로 학습될 수도 있지않을까?
