Abstract
1. Introduction
2. Related work
3. Visual Programming
4. Tasks
4.1. Compositional Visual Question Answering
4.2. Zero-Shot Reasoning on Image Pairs
4.3. Factual Knowledge Object Tagging
4.4. Image Editing with Natural Language
5. Experiments and Analysis
5.1. Effect of prompt size
5.2. Generalization
5.3. Utility of Visual Rationales
6. Conclusion
Self Q&A
Opinion
Abstract
본 논문은 neuro-symbolic 접근방식이자, NLP instructions(프롬프트와 유사한 개념)를 통해 복잡한 다양한 vision task를 해결할 수 있는 VISPROG를 소개한다.
- neuro-symbolic: 머신이 생각하는 방법에 관한 기존 접근법 2개를 합친 것.
- symbolic: 인공지능은 1950~1980에 주류를 이루던 전통적인 규칙기반 인공지능(전통적인 챗봇 등). 비용이 비싸고, 많은 규칙이 통합될수록 정확도가 떨어짐
- neuro: 인공지능은 데이터(패턴) 기반 신경망 즉 딥러닝 네트워크(GPT). '코너케이스' 문제와 같이 예외적인 경우에 약점(최근에는 벤치마크 데이터의 발전으로 해결되고 있음)
- 이 2가지를 합친 neuro-symbolic은 '효율성'의 관점에서 neuro에 코너케이스를 학습시키는 대신 인간의 추론능력(rule based=symbolic)을 통해 해결하는 관점(자율주행 자동차가 '불타는 신호등', '마차'를 인식하지 못할 때 인간의 논리의 개입으로 해결하는 개념-VISPROG는 인간의 논리로 LLM을 활용-)
-> VISPROG는 복잡한 computer vision문제를 해결하기 위해 LLM을 활용한 접근 방식을 제안(Instructions을 LLM이 이해하고 이를 코드로 변환하여, 단계적으로 computer vision task를 해결하는 접근)

VISPROG는 task-specific 학습 대신, LLM의 in-context learning 기능을 사용하여 python-like 모듈식 프로그램을 생성한 다음, 이를 실행하여 'solution(예측값)'과 상호 해석 가능한 'rationale'를 모두 얻는다.
생성된 프로그램의 각 줄은, 쉽게 적용할 수 있는 컴퓨터 비전 모델을 호출(vqa 등)하거나 이미지 처리를 수행(범위 선택 등)하거나, 또는 파이썬 함수 중 하나를 호출(덧셈연산 등)하여 프로그램의 뒷부분(최종 답변)에서 소비될 수 있는 중간 출력을 생성할 수 있다(즉, 최종 문제를 해결하는 중간 과정을 하나씩 수행한다는 의미).
본 연구에서는 4가지 다양한 task에서 VISPROG의 유연성을 증명했다(Sec. 4에서 하나씩 해설).
- compositional visual question answering
- zero-shot reasoning on image pairs
- factual knowledge object tagging
- language-guided image editing
VISPROG와 같은 neuro-symbolic 접근 방식은, 복잡한 롱테일(여기서는 상대적으로 드물게 발생하는 복잡한 작업으로 이해)에 대응할 수 있도록 AI 시스템의 범위를 쉽고 효과적으로 확장할 수 있는 흥미로운 방법이다.
1. Introduction
일반적인 AI 시스템 연구는 end-to-end 학습이 가능한 모델의 개발을 목표로 하고 있으며, 이를 구축하기 위한 접근 방식은 massive-scale unsupervised pretraining 이후, supervised multitask(specific) training을 진행하는 방법이 주류를 이루고 있다.
그러나 이러한 접근 방식은 각 task에 대해 품질이 좋은 데이터 세트가 필요하기 때문에, 궁극적으로 롱테일(소수의 예외적인 문제)까지 확장하기는 어렵다.
본 논문에서는 롱테일 문제(어려운 문제로 이해해도 됨)를 해결하기 위해 LLM을 사용하여 복잡한 instructions(사용자가 해결하고자 하는 downstream task)을 간단한 여러 step으로 분해하고, 각 step에 대해 (step별)specialized end-to-end 모델이나 프로그램(파이썬 함수 등)을 이용해 문제를 해결하는 방법을 제시한다.
나눠진 각 step을 해결할 수 있는 다양한 vision 및 language 시스템이 존재하지만(=각 step별 단일 task를 수행하는 것은 간단하지만), 복잡한 instruction(downstream task)을 한번에 실행하는 end-to-end 모델을 학습시키는 것은 사실상 불가능하다.
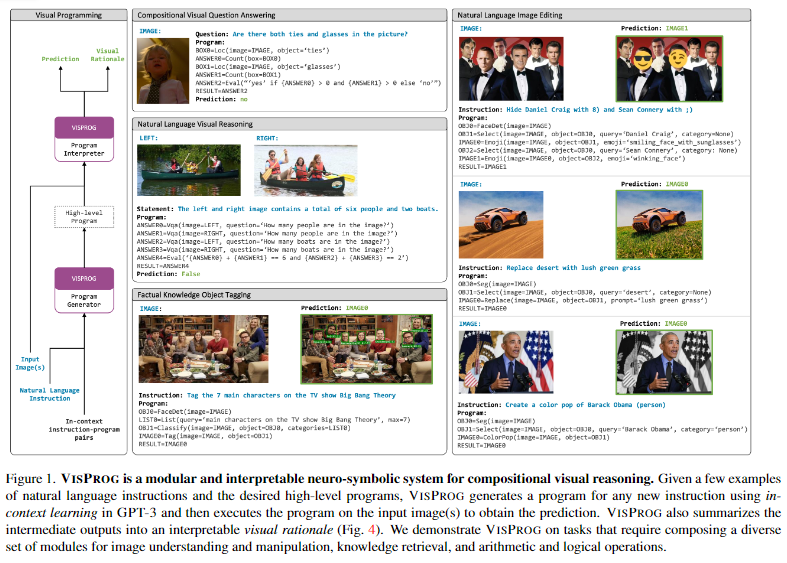
본 논문은 VISPROG 라고 하는 하나 혹은 여러개의 image와 natural language instruction을 입력받으면, 여러 단계의 step을 생성하고 실행하는 visual program을 소개한다.
VISPROG의 각 줄(=step)의 모듈은 컴퓨터 비전 모델, 언어 모델, OpenCV의 이미지 처리 기능, 산술 및 논리 연산자 등이 될 수 있다.
각 step에서는 이전 step들의 output을 input으로 사용할 수 있고, 각 step별로 출력한 중간 결과(step 별 결과)는 downstream 문제를 해결하는데 사용될 수 있다.

예를 들어 VISPROG에 "Tag the 7 main characters on the TV show Big Bang Theory in this image."라는 instruction이 주어졌을 때, 이 작업을 수행하기 위해 시스템은 먼저 LLM을 이용해 instruction의 의도를 파악하게 하고, 이를 해결하기 위해 필요한 step을 나누어 제시하도록 한다.
- 1)얼굴을 감지하고(face detector),
- 2)지식 기반에서 빅뱅 이론의 주요 캐릭터 목록을 검색하고(GPT-3),
- 3)캐릭터 목록을 사용하여 얼굴을 분류하고(CLIP),
- 4)인식된 캐릭터의 얼굴과 이름으로 이미지에 태그를 지정(OpenCV)하는 일련의 단계를 수행하도록 한다.
VISPROG에서 생성된 프로그램은 (한 step당 하나의 모듈로서)학습된 최신 모델들과 비신경망 파이썬 서브루틴(OpenCV 등)을 호출한다.
이를 통해, VISPROG는 해석 가능성(interpretable)을 높일 수 있다. VISPROG는 논리적으로 올바른지 확인할 수 있는 프로그램을 생성하고, 예측을 간단한 단계(step)로 세분화하여 사용자가 중간 단계의 결과를 검사하여 오류를 진단하고 필요한 경우 추론 프로세스에 개입할 수 있도록 한다.
정보의 흐름을 묘사하기 위해 중간 단계 결과(예: text, bounding boxes, segmentation masks, generated images 등)가 서로 연결되어,예측(downstream)의 visual rationale(시각적 근거)가 됩니다.
유연성(flexibility)을 보여주기 위해, VISPROG를 4가지 task에 대해 적용했다. 이 때 이미지 파싱과 같은 common skills(4가지 task에서 모두 사용)을 공유하지만, task별로 specialized한 기능이 사용된다.
(4가지 task는 아래와 같으며, Sec. 4에서 자세히 설명)
- (i) compositional visual question answering
- (ii) zero-shot natural language visual reasoning (NLVR) on im-age pairs
- (iii) factual knowledge object tagging from natu-ral language instructions
- (iv) language-guided image editing
언어 모델(GPT3) 등 각각의 모듈들은 어떤 식으로든 fine-tune되지 않는다.
instruction과 해당 프로그램으로 구성된 몇 가지 상황에 맞는 예제를 제공하기만 하면 모든 task에 VISPROG를 적용할 수 있다.
VISPROG는 사용하기 쉬우면서도, compositional VQA task에서 기존 base VQA 모델보다 2.7점 높은 점수를 보여줬고, NLVR에서 이미지 쌍에 대한 트레이닝 없이 62.4%의 강력한 제로 샷 정확도를 보였다.
knowledge tagging 및 image editing task에서도 정성적, 정량적으로 만족스러운 결과를 기록했다.
논문에서 소개하는 VISPROG의 주요 기여 사항으로는 다음과 같은 것들이 있다.
- (i) LLM의 in-context 학습 기능을 사용하여 compositional visual tasks를 해결하기 위해, natural language instructions로부터 visual programs을 생성하는 시스템(Sec. 3).
- (ii) 단일 end-to-end 모델로는 성공하지 못했거나 제한적인 성공을 거둔 knowledge object tagging(Sec. 4.3) 및 language guided image editing(Sec. 4.4)과 같은 복잡한 시각적 작업에 대해 유연성을 입증
- (iii) 이러한 tasks에 대한 visual rationales(시각적 근거)를 생성하여 오류 분석 및 사용자 중심 instruction 튜닝에 대한 유용성(utility)을 보여줌(Sec. 5.3).
2. Related work
Neuro-symbolic는 LLM의 understanding, generation, in-context learning 능력으로 인해 다시금 주목받고 있다.
Sec. 2에서는 이전에 Vision task에서 사용되던 프로그램 생성 및 실행 접근 방식, 최근 Vision분야에서의 LLM 사용 연구, language tasks을 위한 추론(reasoning) 방법의 발전에 대해 다루고 있다.
Program generation and execution for visual tasks
- Neural module networks(NMN)이 주로 사용되었으나, LLM을 사용한 VISPROG가 더 좋은 프로그램이라는 내용
LLMs for visual tasks
- PICa, SMs, ProgPrompt 등
- 이전 연구에 대한 개괄적인 설명이며(PICa, SMs), ProgPrompt은 instructions을 통해 python-like modules을 사용해 robot action을 실행한 연구
Reasoning via Prompting in NLP
- Chain-of-Thought (CoT)
- 자연어처리 작업에서 decomposer prompt를 이용해 (step별) sequence of sub-tasks를 수행한 연구
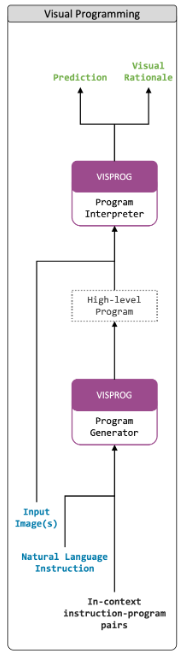
3. Visual Programming
지난 몇 년 동안 AI 커뮤니티는 object detection, segmentation, VQA, captioning, text-to-image generation 등 다양한 vision 및 language tasks에서 task-specific 모델을 통해 높은 performance를 달성했다.
task-specific 모델은 well-defined but narrow(잘 정의된 지엽적인) 문제를 해결하지만, 현실 세계에서 우리가 일반적으로 해결하고자 하는 문제는 조금 더 광범위하고 느슨하게 정의되어 있는 경우가 많다.
이러한 실질적인 작업을 해결하려면 새로운 task-specific 데이터셋을 수집하거나(많은 비용), 다양한 신경망 모델, 이미지 처리 서브루틴(예: 이미지 크기 조정, 자르기, 필터링, 색공간 변환), 기타 연산(예: 데이터베이스 조회 또는 산술 및 논리 연산)을 호출하는 프로그램을 세심하게 구성해야 한다.
무한히 생성되는 롱테일 문제를 해결하기 위해 이러한 프로그램을 수동으로 만들기 위해서는, 프로그래밍 전문 지식이 필요할 뿐만 아니라 비용이 든다(시간적, 인적, 하드웨어적).
VISPROG는 자연어로 task를 설명하고 AI 시스템이 (추가적인)학습 없이 해당 visual 프로그램을 생성하고 실행할 수 있다.
(VISPROG의 대한 본격적인 내용->)
Large language models for visual programming


- GPT-3의 in-context learning 기능(빈칸을 놓으면 입력으로 어떤 것을 원하는지 알아서 파악. VISPROG도 동일하게 작동).
- Fine-tuning 없이 good evening에 대해서 영어-불어 번역 진행

- NLVR code(in-context example)
https://github.com/allenai/visprog/blob/main/prompts/nlvr.py, https://github.com/allenai/visprog/blob/main/notebooks/nlvr.ipynb
VISPROG는 GPT-3의 이러한 in-context learning 기능을 활용하기 위해, 자연어 instructions을 입력으로 받아, in-context examples과 함께 GPT3에 입력한다.
**<VISPROG의 in-context examples>-(위 사진과 코드를 본 뒤 아래 내용 참조)**
VISPROG 프로그램의 각 line(=step)은 모듈의 이름(name of a module), 모듈의 입력 인자 이름과 그 값(module’s input argument names and their values), 출력 변수 이름(output variable name)으로 구성되며, 과거 단계의 출력 변수를 미래 단계의 입력으로 사용하는 경우가 많다.
GPT-3가 각 모듈의 입력 및 출력 유형과 기능을 이해할 수 있도록 설명적인 모듈 이름(예: "Select", "ColorPop", "Replace"), 인자 이름(예: "image", "object", "query"), 변수 이름(예: "IMAGE", "OBJ")을 사용한다.
이러한 in-context examples은 자연어 instructions와 함께 GPT-3에 입력된다. 이미지나 그 내용을 관찰하지 않고도 VISPROG는 GPT3의 in-context learning 능력을 이용하여, 입력 이미지에 대해 실행할 수 있는 프로그램(Fig. 3)을 생성하여 instruction을 수행한다.
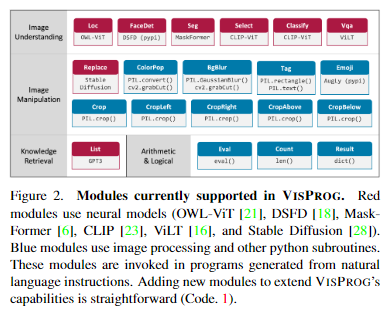
Modules
Modules은 각 step별로 실행할 수 있는 기능을 의미한다.
VISPROG는 20개의 모듈을 지원하며, 각 모듈은 Python Class로 구현되어 있다.

- (i) parse the line to extract the input argument names and values, and the output variable name
- (ii) execute the necessary computation that may involve trained neural models and update the program state with the output variable name and value
- (iii) summarize the step’s computation visually usinghtml(used later to create a visual rationale)
새로운 모듈을 추가하려면 모듈 클래스를 구현하고 등록하기만 하면 되며, 이 모듈을 사용한 프로그램의 실행은 VISPROG interpreter가 자동으로 처리한다.
Program Execution
프로그램 실행은 interpreter가 처리한다.
- 1) interpreter는 instruction을 입력받아 프로그램 상태(변수 이름을 해당 값에 매핑하는 사전. 즉, line을 생성)를 초기화
- 2) 해당 line에 지정된 입력값으로 적합한 모듈을 호출
- 3) 프로그램을 한 줄씩 단계별로 실행
- 각 단계를 실행한 후 프로그램 상태는 해당 단계의 변수명과 출력값으로 업데이트(OBJ0=Seg(image=IMAGE)
Visual Rationale

각 모듈 Class는 필요한 계산을 수행하는 것 외에도 HTML 스니펫에 모듈의 입력과 출력을 시각적으로 요약하는 html()이라는 메서드를 구현한다.
인터프리터는 모든 프로그램 단계의 HTML 요약을 visual rationale(시각적 근거)으로 간단히 연결하여, 프로그램의 논리적 정확성을 분석하고 중간 결과물을 검사하는 데 사용할 수 있다.
또한 visual rationale을 통해 사용자는 실패 원인을 이해하고, 자연어 instructions을 최소한으로 조정하여 성능을 개선을 시도할 수 있다(Sec. 5.3).
4. Tasks
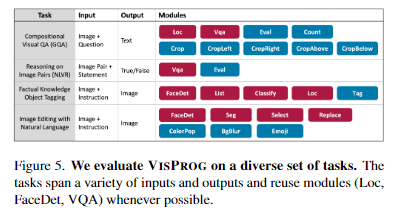
VISPROG는 다양하고 복잡한 visual tasks에 적용할 수 있는 유연한 프레임워크를 제공한다. 공간 추론(spatial reasoning), 여러 이미지에 대한 추론(reasoning about multiple images), 지식 검색(knowledge retrieval), 이미지 생성 및 조작(image generation and manipulation) 등 다양한 기능을 필요로 하는 4가지 tasks에 대해 VISPROG를 평가한다.
- Compositional Visual Question Answering
- Zero-Shot Reasoning on Image Pairs
- Factual Knowledge Object Tagging
- Image Editing with Natural Language
4.1. Compositional Visual Question Answering
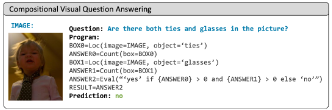
VISPROG는 구조에 따라 구성되므로 compositional, multi-step visual question answering task에 적합하다: GQA(VQA 모듈을 포함하는 벤치마크 데이터셋)
- GQA 예시: "헬멧을 쓴 사람들의 왼쪽에 작은 트럭이 있는가, 아니면 오른쪽에 있는가?"
- VISPROG는 먼저 '헬멧을 쓴 사람들'의 위치를 파악하고, 이 사람들의 왼쪽(또는 오른쪽) 영역을 크롭한 다음, 그쪽에 '작은 트럭'이 있는지 확인하고, 있으면 '왼쪽'을, 그렇지 않으면 '오른쪽'을 반환
VISPROG는 VILT에 기반한 question answering 모듈을 사용하지만, instruction으로 주어진 원본 질문을 입력하지않고, step별 질문의 답변만을 위해 사용한다.
그 결과, VISPROG는 GQA 데이터셋에 대해 해석가능성을 제공할 뿐만 아니라, VILT보다 정확도도 더 높다(원본 질문을 넣는 것보다, 나눠서 넣은 결과가 더 좋다는 의미).
4.2. Zero-Shot Reasoning on Image Pairs

일반적인 VQA 모델은 단일 이미지에 대한 질문에 답하도록 훈련된 반면, VISPROG는 이미지 쌍에 대한 질문에 답이 가능하다.
다중 이미지 모델을 훈련하는 대신, 다중 이미지 예제에 대한 훈련 없이도 단일 이미지 VQA 시스템을 여러번 사용하여 여러 이미지가 포함된 task를 해결할 수 있다.
이미지 쌍에 대한 진술을 검증하는 NLVRv2 벤치마크에서 VISPROG를 적용해보았다.
일반적으로 NLVRv2 문제를 해결하기 위해 NLVRv2의 데이터셋(이미지 쌍을 입력으로 사용) 맞춤형 모델 아키텍처(이미지 쌍 입력이 가능한)를 훈련해야 한다.
반면 VISPROG는 추가적인 훈련 없이, 복잡한 문장을 개별 이미지에 대한 간단한 질문, 산술 및 논리 연산자가 포함된 파이썬 표현식, 이미지 수준 질문에 대한 답변으로 분해하여 문제를 해결한다.
단일 이미지 수준의 답변을 얻기 위해 VILT-VQA를 사용했으며, statement를 확인하기 위해 파이썬 표현식을 사용했다.
4.3. Factual Knowledge Object Tagging
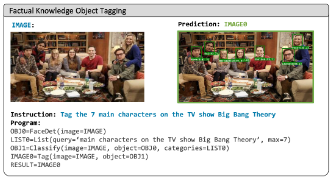

이미지에서 이름을 알 수 없는 유명인, 정치인, TV 프로그램 속 캐릭터, 국가 국기, 기업 로고, 생물 종 등을 식별하는 문제이다(Sec. 1에서 다룬 빅뱅이론 문제).
이 task를 해결하려면 사람, 얼굴, 사물을 localizing할 뿐만 아니라 factual knowledge을 찾은 뒤, 분류를 위한 카테고리 세트를 구성해야 한다(Object Detection과 유사한 형태로 만드는 작업).
이 task를 줄여서 Knowledge Tagging, 또는 Factual Knowledge Object Tagging 라고 한다.
Knowledge Tagging을 해결하기 위해 VISPROG는 implicit knowledge base로 GPT-3를 사용한다("TV 쇼 빅뱅 이론의 주요 등장인물을 쉼표로 구분하여 나열하세요"와 같은 자연어 프롬프트로 쿼리).
- GPT-3는 Instruction과 in-context example을 이용해 프로그램 상태를 초기화(line을 생성)하는데 사용되면서, Knowledge Tagging의 모듈로도 사용(혼동 주의)
이렇게 생성된 카테고리 목록(class 종류)은 localization 및 face detection 모듈로 생성된 image regions을 분류하는 문제로, CLIP 모델을 사용한 image classification 으로 해결할 수 있다.
4.4. Image Editing with Natural Language
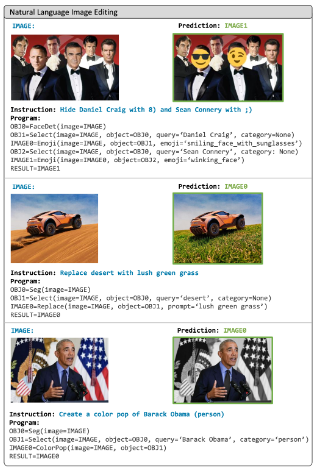

이미지 생성은 지난 몇 년 동안 DALL-E, Parti, Stable Diffusion과 같은 모델을 통해 인상적인 발전을 이루었다.
VISPROG는 얼굴 감지, 분할, 이미지 처리 모듈을 조합하여 프로그래밍 방식으로 비교적 간단하게 달성할 수 있는 "Hide the face of Daniel Craig with :p", "Create a color pop of Daniel Craig and blur the background"와 같은 프롬프트를 처리하는 것은 아직 앞선 모델의 기능을 뛰어넘지 못하고 있다.
그러나, "Replace Barack Obama with Barack Obama wearing sunglasses"와 같은 정교한 Image Editing을 수행하는데 강점이 있다.
VISPROG는 image inpainting과 같은 작업을 수행할 때 Stable Diffusion을 사용한다.
5. Experiments and Analysis
5.1. Effect of prompt size
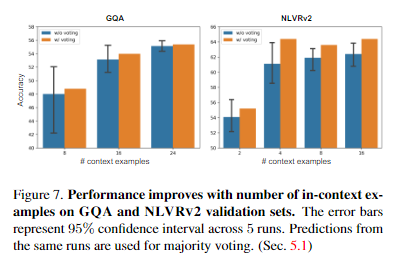
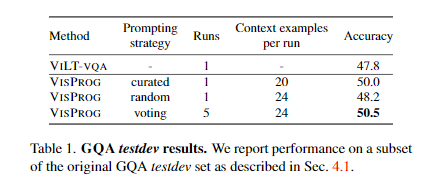
GQA와 NLVR의 프롬프트에 사용되는 in-context examples 개수가 증가함에 따라 validation performance가 점진적으로 향상됐다.
또한 각 실행은 random seed를 기반으로 annotated in-context examples의 subset을 무작위로 선택하는데, random seed에 대한 majority voting(Hard voting)은 평균 성능보다 일관되게 더 나은 성능을 나타냈다(즉, Instruction을 고정하고 여러 in-context examples을 바꿔가며 나온 downstream task의 답변을 Hard voting했다는 의미).
NLVR에서 VISPROG의 성능당 프롬프트 수는 GQA보다 적은 숫자에서 saturates(포화. 성능이 크게 달라지지 않는 시점이자 overfitting 가능성이 있는 기점)된다.
이는 NLVRv2에 필요한 모듈 수가 GQA보다 적기 때문으로 추정된다.
5.2. Generalization
GQA
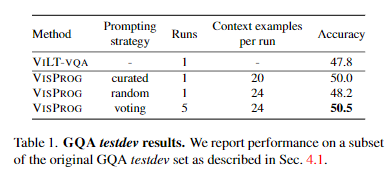
validataion set에서 평가한 가장 큰 프롬프트 크기(24 in-context examples)를 기준으로, 5번의 실행(각 실행은 총 31개 in-context examples 중 24개를 무작위로 샘플링)을 통해 'random'과 'voting'을 선정
- random: 단일 모델로 가장 성능이 좋은 모델(24 in-context examples)
- voting: 5개의 majority voting의 결과로 가장 성능이 좋은 모델(각각 24 in-context examples)
- curated의 경우, 연구자가 선정한 20개의 in-context examples을 사용한 모델(16개는 31개의 annotated in-context examples로부터 가져오고, 4개는 오류를 직접보며 문제를 잘 맞추는데 도움이 될 것 같은 4개의 in-context examples입력)
random 프롬프트는 VILT-VQA보다 약간 더 나은 성능을 보이지만, voting을 사용할 경우 2.7점이라는 향상된 결과를 얻는다.
curated 프롬프트는 컴퓨팅을 5배나 적게 사용하면서도 voting과 동일한 성능을 발휘하여 프롬프트 엔지니어링의 가능성을 보여줬다(Visual Rationale 부분에서 다뤘던, 사용자가 Instruction을 수정해가며 성능을 향상시킬 수 있다는 것과 같은 맥락).
NLVR
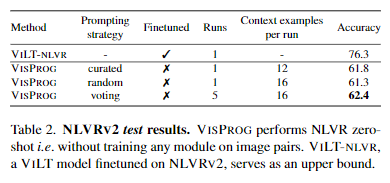
VISPROG는 이미지 쌍에 대한 트레이닝 없이 제로 샷으로 NLVR 작업을 수행했음에도, NLVRv2에 대해 미세 조정된 VILT 모델인 VILT-NLVR와 비교해 크게 떨어지지 않았다?(upper bound on performance).
- (리뷰자는 점수 차이가 꽤 커보인다고 생각)
점수차이가 존재하지만, VISPROG는 단일 이미지 VQA모델과 LLM(추론을 위한)만을 사용하여 강력한 제로 샷 성능을 보여준다.
참고로 VISPROG의 단일 이미지에 대한 VQA모듈은 VILT-VQA를 사용했다(VILT-NLVRv2을 사용하지 않았다는 의미).
Knowledge Tagging
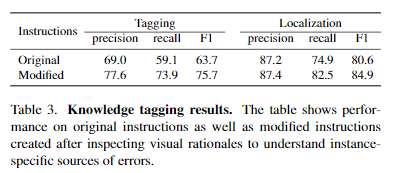
Knowledge Tagging의 instructions에는 localization(~의 얼굴 localization)뿐만 아니라 localized objects에 tag를 지정할 카테고리를 가져오기 위해 knowledge base를 쿼리하는 작업(~의 얼굴의 특징을 GPT로부터 찾기)도 필요하다.
original instructions에 대해서는, VISPROG는 localizing와 naming을 모두 포함하는 tagging에서 63.7 F1 score라는 점수를 달성했으며, TaggingLocalization만으로는 80.6 F1 score라는 점수를 기록했다(impressive라고 표현).
Image Editing

위 실험 결과는 face manipulations, highlighting objects 등 장면의 주요 요소(예: 사막)를 교체할 수 있는 VISPROG의 광범위한 능력을 보여준다
- (Sec 5.3 Instruction tuning에서 다시 결과 해석)
5.3. Utility of Visual Rationales
Error Analysis
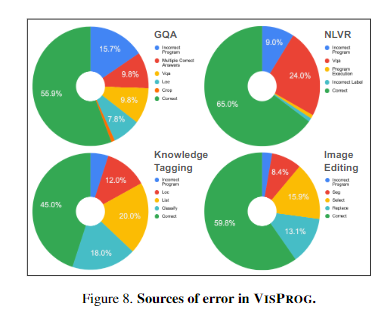
VISPROG는 중간결과를 출력하므로, Visual Rationale을 통해 실패 모드(어느 단계에서 실패했는지)를 철저히 분석할 수 있다.
각 task에 대해 100개의 샘플을 수동으로 검사하여 오류의 원인을 분석했다.
이러한 분석은 다양한 task에서 VISPROG의 성능을 개선하기 위한 명확한 방향성을 제공한다.
예를 들어, GQA에서 Incorrect Program Error가 샘플의 16%에 영향을 미치는 주요 오류 원인이므로, 현재 VISPROG가 실패하는 instructions과 유사한 in-context examples을 더 많이 제공함으로써 GQA의 성능을 개선할 수 있을 것이다.
NLVR의 경우, VQA Error가 24%이므로, VILT-VQA 모델을 NLVR에 맞게 fine-tuning하거나, 더 나은 VQA 모델로 교체하면 성능이 향상될 수 있을 것이다.
Instruction tuning

visual rationale이 유용하려면 궁극적으로 사용자가 자신의 task에서 시스템 성능을 개선할 수 있어야 한다(각 예시가 그림에 있음).
- (i) Localization 모듈에 대한 better 쿼리(예: "item" 대신 "kitchen appliance")
- (ii) knowledge retrieval을 위한 better 쿼리(예: "CEO of IBM" 대신 "most recent CEO of IBM")
- (iii) 카테고리 이름 제공하여 지정된 카테고리 카테고리에 속하는 세분화된 영역으로 검색을 제한(예: "table-merged")
- (iv) 목록 모듈의 최대 인수를 통해 지식 태그에 대한 분류 카테고리 수를 제어(예: max=4)


Instruction tuning을 통해(Modified) 지식 Knowledge tagging 및 Image editing task에서 성능 향상을 이끌어 낼 수 있음을 보여준다.
6. Conclusion
VISPROG는 복잡한 visual tasks에 LLM의 추론 능력을 활용할 수 있는 간단하고 효과적인 방법으로 visual programming을 제안한다.
VISPROG는 상호 해석 가능한 visual rationales를 생성하는 동시에 강력한 성능을 입증했다.
더 나은 프롬프트 전략을 연구하고 사용자 피드백을 통합하는 새로운 방법을 모색하여 VISPROG와 같은 neuro-symbolic 시스템의 성능을 개선하는 것은 차세대 범용 vision 시스템을 구축하는 데 있어 매우 흥미로운 방향이 될 것이다.
Self Q&A
Opinion
- GPT API를 사용한 것 같은데, LLM크기를 바꿔가며 실험했을 때의 결과도 함께 있었으면 좋았을 것이라는 아쉬움
- fine-tuning의 가장 큰 이유 중 하나는(성능 제외), LLM의 메모리/연산량을 Serving시 적용하기 어렵기 때문인데, 그 부분에 대한 언급이 없어서 아쉬웠다.
