ABSTRACT
1. INTRODUCTION
2. RELATED WORK
3. EXPERIMENTAL SETUP
3.1. RECURRENT NEURAL NETWORK MODELS
3.2. CHARACTER-LEVEL LANGUAGE MODELING
3.3. OPTIMIZATION
4. EXPERIMENTS
4.1. COMPARING RECURRENT NETWORKS
4.2. INTERNAL MECHANISMS OF AN LSTM
4.3. UNDERSTANDING LONG-RANGE INTERACTIONS
4.4. ERROR ANALYSIS: BREAKING DOWN THE FAILURE CASES
5. CONCLUSION
Self Q&A
Opinion
ABSTRACT
- Recurrent Neural Networks(RNNs), Long Short-Term Memory(LSTM)는 sequential data를 포함하는 다양한 머신러닝 문제에 성공적으로 적용되면서 다시금 관심을 받고 있다(2015년).
- LSTM은 실제로 뛰어난 결과(exceptional result)를 제공하지만, 그 성능의 출처(source)과 한계에 대해서는 아직 잘 알려져 있지 않다.
- character-level language models을 해석 가능한(interpretable) testbed로 사용하여 representations, predictions, error type에 대한 분석을 제공함으로써 이러한 격차를 해소하고자 한다.
- 특히, 실험을 통해 line lengths(줄 길이), 따옴표(quotes), 괄호(brackets) 등 long-range dependencies을 추적하는 해석 가능한 cells의 존재를 밝혀냈다.
- 또한, finite horizon(확률 프로세스를 H 스텝까지만 진행하는 모델) n-gram models 모델과의 비교 분석을 통해, LSTM이 어떻게 long-range structural dependencies을 개선했는지까지 추적했다.
1. INTRODUCTION
- Recurrent Neural Networks(RNNs), Long Short-Term Memory(LSTM)는 sequential data를 포함하는 다양한 머신러닝 문제에 성공적으로 적용되면서 다시금 관심을 받고 있다.
- sequential data를 포함하는 다양한 머신러닝 문제로는 language modeling, handwriting recognition and generation, machine translation, speech recognition, video analysis, image captioning 등이 있다.
- 그러나 인상적인 performance의 원천과 shortcoming(결점)에 대해서는 아직 제대로 이해되지 않고 있다(왜 잘 되는지 이유를 정확하게 알 수 없다는 의미).
- 이는 해석 가능성 부족에 대한 우려를 불러일으키고, 더 나은 architectures를 설계하는 능력에 대한 한계이다.
- 논문의 저자들이 아는 한, 본 연구는 real-world data에 대한 LSTM의 예측과 학습된 표현(learned representations)에 대한 최초의 실증적 탐구(empirical exploration)를 제공한다.
- 구체적으로는, character-level language models을 해석 가능한 testbed로 사용하여 LSTM이 학습한 long-range dependencies을 조명한다.
- 분석결과, line lengths(줄 길이), 괄호(brackets), 따옴표(quotes) 등 해석 가능한 고급 패턴을 강력하게 식별하는 cells의 존재를 밝혀냈다.
- 또한 n-gram models과의 종합적인 비교를 통해 LSTM의 예측을 정량화(quantify)했으며, 이를 통해 long-range reasoning이 필요한 characters에 대해 LSTM이 훨씬 더 나은 성능을 보인다는 사실을 발견했다.
- 마지막으로, 본 논문은 '양파 껍질을 벗기듯' oracles의 sequence를 사용하여 errors를 분석했다.
- 이러한 결과를 통해 여러 categories에 남아있는 errors의 정도를 정량화하고, 추후 연구를 위한 specific areas을 제안한다.
2. RELATED WORK
Recurrent Networks
- Recurrent Neural Networks(RNNs)은 다양한 sequence learning tasks에 오랫동안 적용되어 왔다.
- 초기 성공에도 불구하고, 단순 반복 네트워크(simple recurrent networks) 구조를 훈련시키는 것에 대한 어려움으로 인해 기본 아키텍처를 개선하기 위한 다양한 제안이 있었다.
- 가장 성공적인 변형은 Long Short Term Memory networks(LSTM)으로,
explicit gating mechanisms(명시적인 게이팅 메커니즘)과 built-in(내장된) constant error carousel을 통해 원칙적으로 장기간에 걸쳐 정보(information)를 저장(store)하고 검색(retrieve)할 수 있다.
Understanding Recurrent Networks
- 기본 LSTM 아키텍처를 수정하거나 확장하는 작업은 많았지만, 그 표현과 예측의 속성을 이해하는 데는 상대적으로 적은 관심을 기울여 왔다.
- 본 논문과 가장 관련이 있는 연구는 'Hermans & Schrawewn'의 'Training and analysing deep recurrent neural net-works. InAdvances in Neural Information Processing Systems, pp. 190–198, 2013'이다.
- 'Hermans & Schrawewn' 연구도 character-level language models, 특히 parenthesis closing(괄호 닫기) 및 time-scales analysis(시간척도 분석)의 context에서 recurrent networks가 학습한 long-term interactions(장기 상호작용)에 관한 내용이다.
- 본 논문의 연구는 'Hermans & Schrawewn'의 연구를 보완하고 추가적인 분석 유형을 제공한다.
3. EXPERIMENTAL SETUP
- 먼저 일반적으로 사용되는 세 가지 recurrent network architectures (RNN, LSTM, GRU)를 설명한 다음, sequence learning에 사용되는 아키텍처를 설명하고 마지막으로 최적화에 대해 논의한다.
3.1. RECURRENT NEURAL NETWORK MODELS
- 3.1은 RNN, LSTM, GRU의 구조에 대한 설명이므로 생략하겠다.
Vanilla Recurrent Neural Network (RNN)
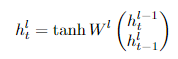
Long Short-Term Memory (LSTM)

Gated Recurrent Unit (GRU)
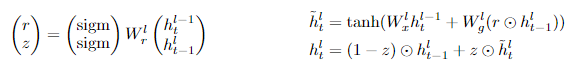
3.2. CHARACTER-LEVEL LANGUAGE MODELING
- 본 논문은 sequence learning을 위한 해석 가능한 testbed로 character-level language modeling을 사용한다.
- 이 설정에서, 네트워크에 대한 input은 sequence of characters이며, 네트워크는 각 time step에서 Softmax 분류기를 사용하여 시퀀스의 다음 문자를 예측하도록 훈련된다.
- loss fuction은 average cross-entropy loss를 최소화하는 것을 목표로 한다.
3.3. OPTIMIZATION
- batch size 100, RMSProp으로 mini-batch stochastic gradient descent을 사용한다.
- 네트워크는 100 time steps으로 풀어서 정의할 수 있다(unrolled).
- 각 모델을 먼저 50epoch 동안 학습시킨 뒤, 이후 10epoch마다 학습률에 0.95의 계수를 곱하여 감쇠시킨다(최대 100epoch).
- validation performance에 따라 early stopping를 사용하고, 각 모델에 대해 개별적으로 dropout의 양을 cross-validate한다.
4. EXPERIMENTS
- 이전에 character-level language models의 context에서 사용되던 두 가지 datasets은 'Penn Treebank dataset'과 'Hutter Prize 100MB of Wikipedia dataset'였지만, 두 dataset 모두 common language와 special markup이 혼합되어 있다.
- 본 논문의 목표는 이전 연구와 경쟁하는 것이 아니라, 통제된 환경에서 순환 신경망을 연구하고, common language와 markup language를 극단에서부터 연구하는 것이다(both ends on the spectrum of degree of structure).
- 따라서 markup language가 거의 없는 대부분이 영어 텍스트로 구성된 3,258,246자의 'Leo Tolstoy’s War and Peace (WP)' 소설과( train80/val10/test10), 대부분이 markup language인 리눅스 커널(Linux Kernel)의 소스 코드(train95/val5/test5)를 사용하기로 했다.
- vocablary의 총 character 수는 WP의 경우 87, LK의 경우 101이다.
4.1. COMPARING RECURRENT NETWORKS
- 먼저, 통제된 환경에서 성능을 비교하기 위해 몇 가지 recurrent network 모델을 훈련시킨다.
- LSTM/RNN/GRU의 유형에 따라, 레이어 수(1/2/3), 파라미터 개수(1-layer 기준 hidden state vector를 64/128/256/512로 설정함에 따라 파라미터 개수는 50K, 130K, 400K, 1.3M), 두 데이터 세트(WP/KL)의 cross product로 모델을 훈련시켰다.
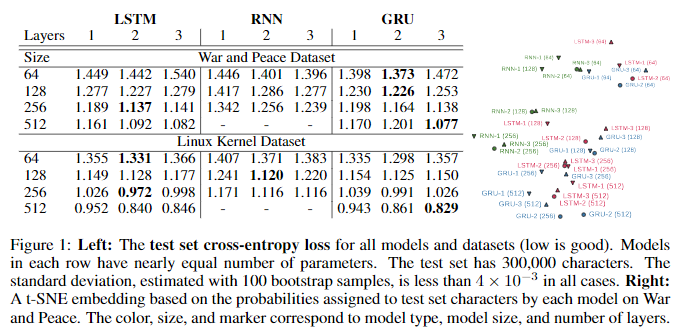
- 일관된 연구 결과는 최소 2-layer 이상의 층이 유익하다는 것이다(1-layer의 loss가 높음. 그러나 2~3-layer의 결과는 엇갈림).
- 또한, LSTM과 GRU의 결과가 엇갈리지만, 둘 다 RNN보다는 성능이 훨씬 좋다.
- 각 모델 쌍이 가장 가능성이 높은 캐릭터에 일치하는 비율을 계산하여 t-SNE embedding를 렌더링하는 데 사용한 결과, RNN은 독자적인 군집을 형성하는 반면, LSTM과 GPU는 유사한 예측을 하였다(새롭게 주장하는 내용은 아니고, 기존 주장에 대한 뒷받침 근거정도).
4.2. INTERNAL MECHANISMS OF AN LSTM
Interpretable, long-range LSTM cells
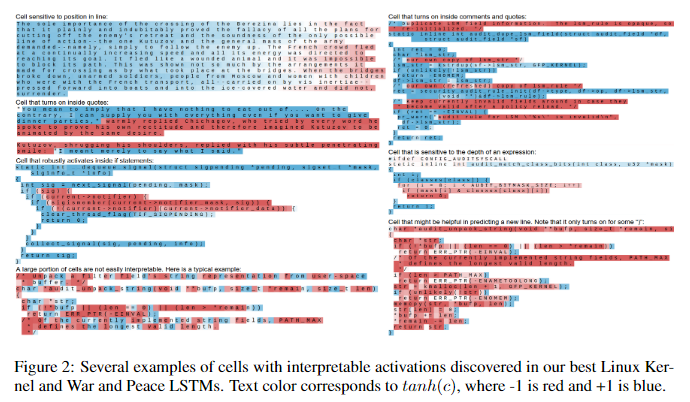
- LSTM은 원칙적으로 memory cells을 사용하여 long-range information를 기억하고 현재 처리 중인 텍스트의 다양한 속성을 추적할 수 있지만, 이러한 셀의 존재는 실제 데이터에서 실험적으로 입증된 적 없다.
- 본 실험에서는 네트워크에 해석 가능한 여러 개의 셀이 실제로 존재한다는 것을 확인했다.
- 예를 들어, 한 셀은 높은 값으로 시작하여 다음 줄 바꿈까지 서서히 줄어드는 line length counter 역할을 합니다(값이 줄어들면 다음줄로 넘어가라는 신호).
- 다른 셀은 따옴표 안쪽, if문 뒤의 괄호, 문자열 또는 코드 블록의 들여쓰기가 증가함에 따라 점점 더 강도가 높아집니다(따움표가 열린 상황, 들여 쓴 상황을 기억한다는 의미).
- 주목할 점은, 하이퍼파라미터를 사용한 truncated backpropagation(기울기 소실 문제를 예방하기 위해 일정 sequence로 자른 뒤 붙인 형태)는 구조적으로 gradient signal이 100자를 초과하는 종속성을 제대로 인식하지 못해야하지만(직접적으로 전달되지 않기 때문에), 100자를 훨씬 초과하는 따옴표나 주석 블록을 안정적으로 추적하는 cells을 여전히 관찰할 수 있다(예: Figure 2의 따옴표 감지 셀 예시에서 230자).
- 연구자들은 이러한 cells이 처음에는 100자보다 짧은 패턴에서 발달하지만, 이후에는 더 긴 시퀀스로도 적절히 일반화된다는 가설을 세웠다.
Gate activation statistics
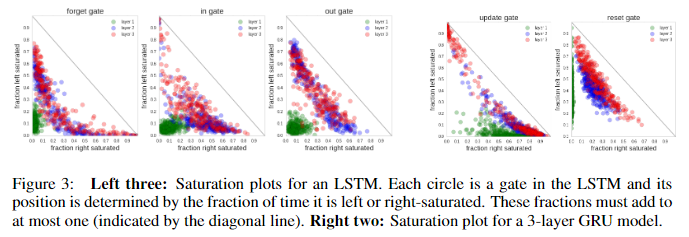
- test set data를 처리할 때 네트워크의 gate activations를 연구함으로써 LSTM의 내부 메커니즘에 대한 통찰력을 얻을 수 있다.
- 본 연구에서는 특히 네트워크의 포화 상태 분포(distributions of saturation regimes)를 살펴보는 데 관심이 있었다
- 즉, 서로 다른 regime(지정된 상태 또는 조건)에서 포화 정도가 어떻게 변하는지에 대한 패턴이나 변동성을 분석했으며, 게이트의 활성화가 각각 0.1 미만 또는 0.9 이상이면 왼쪽 또는 오른쪽 포화 상태로, 그렇지 않으면 불포화 상태로 설정했다.
- 그런 다음 각 LSTM 게이트가 왼쪽 또는 오른쪽 포화 상태에서 보내는 시간 비율을 계산하고 그 결과를 Figure 3에 표시했다.
- 예를 들어, 종종 오른쪽으로 포화되는 forget gates의 수는 매우 오랜 기간 동안 값을 기억하는 셀에 해당하기 때문에 특히 흥미롭다.
- 거의 항상 오른쪽 포화 상태(forget gates 산포도의 오른쪽 하단에 표시됨)로 거의 완벽한 통합기로 작동하는 cells이 여러 개 있다(즉, 정보를 잃어버리지 않고 잘 가지고 있다는 의미에서 통합기라는 표현 사용).
- (더 많다는 의미가 아니라, 이정도면 꽤 많다는 의미)
- 반대로, 순수하게 피드 포워드 방식(과거 정보를 활용하지 않고 직전 상태만을 활용)으로 작동하는 cells은 존재하지 않는다(즉, forget gates가 일관되게 왼쪽 포화 상태로 표시되지 않는다).
- output gate 통계에서도 hidden state에 지속적으로 드러나거나 차단되는 cells이 없음을 알 수 있다.
- 마지막 놀라운 발견은 binary regime(왼쪽 또는 오른쪽이 포화 상태)으로 작동하는 게이트를 포함하는 다른 두 레이어와 달리, 첫 번째 레이어의 활성화가 훨씬 더 확산되어 있다는 점이다(분산형 차트에서 원점 근처).
- 이 결과를 설명하기는 어렵지만, 모든 모델에서 이러한 현상이 나타난다.
- GRU 모델에서도 비슷한 효과가 나타나는데, 첫 번째 레이어의 reset gates 은 거의 오른쪽으로 포화되지 않고,
- update agte 는 거의 왼쪽으로 포화되지 않는데, 이는 이 레이어에서 이전 hidden state가 거의 사용되지 않는 순전히 피드 포워드 작동 모드(과거 정보를 활용하지 않고 직전 상태만을 활용)를 나타낸다.
4.3. UNDERSTANDING LONG-RANGE INTERACTIONS
-
LSTM의 우수한 성능은 long-range information를 저장할 수 있는 능력에 기인하는 경우가 많다.
-
이 section에서는, LSTM과 고정된 수의 이전 time step의 정보만 활용할 수 있는 2개의 baseline model을 비교한다(n-NN, n-gram).
- n-NN: 비선형 함수로 tanh 사용하는 하나의 hidden layer로 구성된 fully-connected neural network(정보에 제한을 두지 않는 모델). 네트워크의 input은 n개의 연속된 문자에 대한 one-of-K 인코딩을 연결(concatenate)한 것으로 이루어진 희소한 이진 벡터(대부분의 원소가 0이고 일부 원소만 1인 벡터) - n-gram: n개의 이전 sequence를 보고 language models을 수행하는 표준 smoothing method(n개의 고정된 이전 time step을 지정)
Performance comparisons
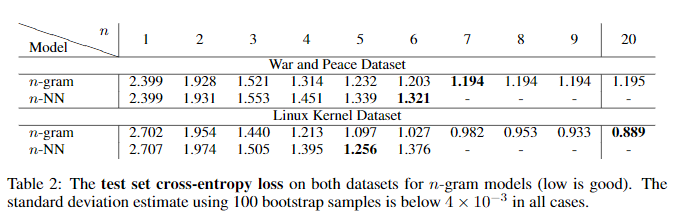
- n-NN과 n-gram을 비교한 결과, n이 작은 경우 성능이 비슷했지만 n이 커지면서 n-NN 모델이 과적합되기 시작하여, n-gram이 더 나은 성능을 보였다.
- LSTM의 best model(3-layer GRU)은 n을 20으로 설정했을 때보다 성능이 우수했는데, 이는 LSTM이 최소 20개의 sequence 이상을 기억한다는 것에 대한 weak evidence로 볼 수 있다(심지어 용량은 n-gram은 3GB LSTM은 11MB).
Error Analysis
- recurrent networks 와 n-gram 모델 모두에서 발생하는 오류에 대해 자세히 알아보는 것은 유익하다.
- 이전 time step에서 모델에 의해 할당된 확률이 0.5 미만인 문자를 오류로 정의했다.
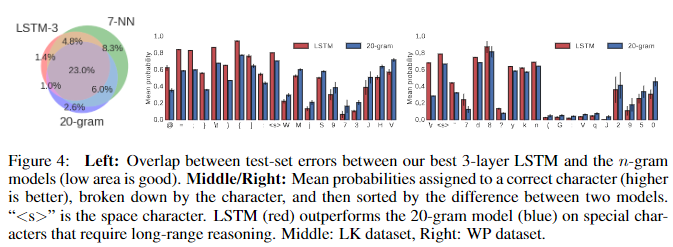
- Figure 4(left)는 3-layer LSTM의 test set 오류와 n-NN 및 n-gram 모델 간의 중첩을 보여준다.
- 대부분의 오류는 세 모델 모두에서 공유되지만 각 모델마다 고유한 오류도 있음을 알 수 있다.
- LSTM 또는 20-gram 모델에 고유한 오류에 대한 심층적인 인사이트를 얻기 위해 test set 전체에서 vocabulary의 각 문자에 할당된 평균 확률을 계산했.
- Figure 4(middle,right)는 각 모델이 다른 모델에 비해 가장 큰 이점이 있는 10개의 문자가 표시되어 있다.
- LSTM은 Linux Kernel dataset에서 공백과 대괄호를 포함한 C프로그램의 구조에 관한 강점을 가지고 있고,
- WP dataset에서는 약 70자마다 발생하는 carriage return(하나의 문단마다의 줄바꿈)에 대한 흥미로운 long-term dependency를 특징으로 합니다.
- 이는 LSTM이 long-range interactions를 추적하는데 특화되어 있다는 점에 대한 strong evidence이다.
Case study: closing brace

- Linux Kernel dataset에서의 "}(중괄호의 닫는 기호)"를 정확하게 예측하는 것은, 이전 정보를 얼마나 잘 저장하고 있는가에 대한 척도가 될 수 있다.
- Figure 5(left)에는 "{"와 "}"의 거리에 따라, "}"에 할당하는 평균 확률을 계산한 내용이다.
- 거리가 20자 이내인 경우 성능차이가 크게 없지만, 20-gram은 계속해서 일관된 성능을 보이는 반면, LSTM은 60자까지 증가하다가 점차 감소한다.
Training dynamics
- 테스트 세트의 예측 분포 사이의 (대칭) KL-divergence을 사용하여 훈련하는 동안 훈련된 n-NN 모델과 비교하여 LSTM의 훈련 역학을 조사하는 것도 유용하다.
- Figure 5에서 mean KL과 loss의 차이를 시각화했다.
- 특히, 처음 몇 번의 반복에서는 LSTM이 1-NN 모델처럼 작동하지만 곧 이 모델에서 벗어나, 2-NN, 3-NN, 4-NN 모델과 가장 유사하게 작동한다.
- 이 실험은 LSTM이 학습하는 동안 점점 더 긴 종속성을 통해 그 능력을 "grow(성장)"시킨다는 것을 시사한다.
4.4. ERROR ANALYSIS: BREAKING DOWN THE FAILURE CASES
- 이 section에서는 LSTM의 error를 카테고리별로 분류하여 앞으로 해결해야할 제약사항과, 각 error type의 상대적 심각도를 연구하고 추가 연구가 필요한 영역을 제안하고자 한다.
- WD dataset은 error를 카테고리화하기 좋다.
- 본 연구의 접근 방법은 “peel the onion(양파를 까듯이)” 일련의 구조화된 oracle로 오류를 반복적(하나씩)으로 제거하는 방식이다.
- 이전 time step에서 모델에 의해 할당된 확률이 0.5 미만인 경우 문자를 오류로 간주했다.
- 오라클을 적용하는 순서가 결과에 영향을 미치지만, 각 오류 범주의 제거 난이도가 높아지는 순서대로 오라클을 적용하려고 노력했으며, 이러한 단점에도 불구하고 최종 결과는 유익하다고 생각한다.
n-gram oracle
- 먼저, short dependencies을 더 잘 모델링하여 수정할 수 있는 오류를 제거하는 optimistic n-gram 오라클을 구축한다.
- n-gram(n=1~9) 모델을 평가하고 이러한 9개의 모델 중 하나 이상에 의해 올바르게 분류된 경우(해당 문자에 할당된 확률이 0.5보다 큰 경우) 문자 오류를 제거한다.
- (즉, n의 길이를 늘리는 것만으로 해결되는 오류를 제거하는 작업)
Dynamic n-long memory oracle
- “Jon yelled at Mary but Mary couldn’t hear him" 이라는 문자열이 있을 때,
- 예측에서 발견한 흥미롭고 일관된 실패 모드 중 하나는 LSTM이 'Mary'의 첫 번째 문자(M)를 예측하지 못하면 거의 항상 두 번째 문자(a~)에 대해서도 거의 동일한 패턴의 오류로 예측하지 못한다는 점이다(특정 단어에 대해서 1번째 문자를 잘못 예측할 경우, 다른 단어를 예측하는 과정이기 때문에 당연히 2~문자는 틀린 문자).
- 그러나 원칙적으로 첫 번째 언급이 있으면(예측값이 정확하면) 두 번째 언급(정답)의 가능성이 훨씬 더 높아진다(문장 등의 첫 시작뿐만 아니라, 단어의 첫 시작을 의미).
- 마지막 n∈{100,500,1000,5000}개의 character에서 substring으로 발견될 수 있는 모든 단어(두 번째 character부터 시작)의 오류를 제거한다.
- (즉, 단어의 첫 시작이 잘못된 경우에 대한 오류 제거)
Rare words oracle
- 다음으로, 훈련 데이터에서 n번(n=1~5)만 나타나는 희귀 단어에 대한 오류를 제거하는 오라클을 구축한다.
Word model oracle
- 오류의 상당 부분이 각 단어의 첫 글자에서 발생한다는 사실을 발견했다(Dynamic n-long memory oracle).
- 시퀀스에서 다음 단어를 선택하는 작업은 알려진 단어(첫글자를 맞춘 상황)의 마지막 몇 글자를 완성하는 것보다 더 어렵다.
- 이러한 관찰에 착안하여 우리는 공백(space), 따옴표(quote), 줄바꿈(newline) 뒤에 오는 모든 오류(all errors. 전부 다 틀린 경우를 의미하는 것으로 보임)를 제거하는 오라클을 만들었다.
Punctuation oracle
- 모든 구두점(.) 오류를 제거하는 오라클을 구축했다.
Boost oracles
- 눈에 띄는 구조나 패턴을 보이지 않는 나머지 오류는 정답 확률을 일정량 높여주는 오라클에 의해 제거된다(예측 확률이 0.5 이하에 대해 오류로 했지만, 확률값에 0.1~0.5를 더해주는 것).
- 이러한 오라클을 통해 나머지 오류의 난이도 분포를 파악할 수 있다(0.1씩 더했을 때 0.5 이하의 값들의 개수를 보며 난이도 분포를 확인한다는 의미).
Error Analysis
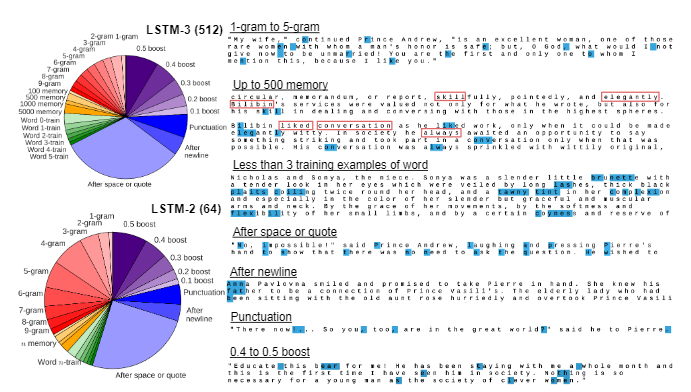
- 2개의 LSTM 모델을 통해 error 분석을 진행해보겠다.
- 첫번째는 best LSTM model(LSTM-3 512)이고, 두번째는 가장 작은 모델 category(50K 개의 파라미터)에서 best LSTM 모델(LSTM-2 64)이다.
- 두 모델에 각 오라클을 적용한 후의 오류 분석은 Figure 6에서 확인할 수 있다.
The error breakdown
- best LSTM model은 테스트 세트 character 33만 개 중 42%에 해당하는 총 14만 개의 오류를 발생시켰다.
- 이 중 n-gram oracle은 18%를 제거하였고, Dynamic n-long memory oracle은 6%의 오류를 제거했다.
- 마지막으로, Rare words oracle이 오류의 9%를 차지했다. 이 오류 유형은 비지도 사전 학습을 사용하거나 학습 집합의 크기를 늘리면 완화될 수 있습니다(Dai & Le, 2015).
- 나머지 오류의 대부분(37%)은 공백, 따옴표 또는 줄 바꿈 뒤에 발생하며, 모델이 word-level prediction(어떤 단어인지 예측하는 것)에 어려움을 겪고 있음을 나타낸다(단어의 첫 글자만 잘 맞추면 그 단어는 잘 맞춤).
- 이는 시간을 통한 역전파의 시간 범위가 길어지거나 possibly hierarchical context 모델(문맥을 적절히 이해하도록 설계된 모델)을 구현할 경우 개선될 수 있음을 시사한다(실제로 추후 possibly hierarchical context 모델 Transformer를 통해 개선).
Errors eliminated by scaling up
- 반면, smaller LSTM model(LSTM-2 64)은 총 18만 4천 개의 오류(테스트 세트의 56%)를 발생시켰으며, 이는 large model(LSTM-3 512)보다 4만 4천 개 늘어난 수치이다.
- 놀랍게도 이 오류 중 3만 6천 개(81%)가 n-gram 오류이고, 5천 개는 Boost category에서 발생하며, 나머지 3천 개는 다른 category에 비교적 고르게 분포되어 있다.
- 즉, 매개변수 수를 26배로 늘리는 것만으로도 local n-gram 오류율은 거의 전적으로 개선되었고, 다른 오류 범주는 거의 영향을 받지 않았다.
- 이 분석은 단순히 기본 모델을 확장하는 대신, 새로운 개선된 아키텍처를 개발할 필요가 있다는 몇 가지 증거를 제공한다(즉, 기존 모델의 개선만으로는 n-gram오류를 제외한 다른 오류를 해결할 수 없어보인다).
5. CONCLUSION
- 본 논문은 Recurrent Neural Networks에 존재하는 predictions, representations training dynamics, error types present 을 분석하기 위해, character-level language models을 해석 가능한 testbed로 사용했다.
- 특히, qualitative visualization experiments(정성적 시각화 실험), cell activation statistics(세포 활성화 통계), comparisons to finite horizon n-gram models과의 비교를 통해, 네트워크가 real-world data에서 강력하고 종종 해석 가능한 long-range interactions을 학습한다는 사실을 입증했다.
- error analysis을 통해 cross entropy loss을 해석 가능한 여러 categories로 세분화하여, 남아있는 제한 사항의 원인(source)을 밝히고 추가 연구 분야를 제안할 수 있었다.
- 특히, 모델을 scaling up하면 n-gram category의 오류가 거의 완전히 제거된다는 사실을 발견했으며, 이는 나머지 오류를 해결하기 위해 추가적인 구조적 혁신(architectural innovations)이 필요하다는 증거를 제공한다.
