Abstract
1. Introduction
2. Related work
3. UniT: Unified Transformer across domains
3.1. Image encoder
3.2. Text encoder
3.3. Domain-agnostic UniT decoder
3.4. Task-specific output heads
3.5. Training
4. Experiments
4.1. Multitask learning on detection and VQA
4.2. A Unified Transformer for multiple domains
5. Conclusion
Self Q&A
Opinion
Abstract
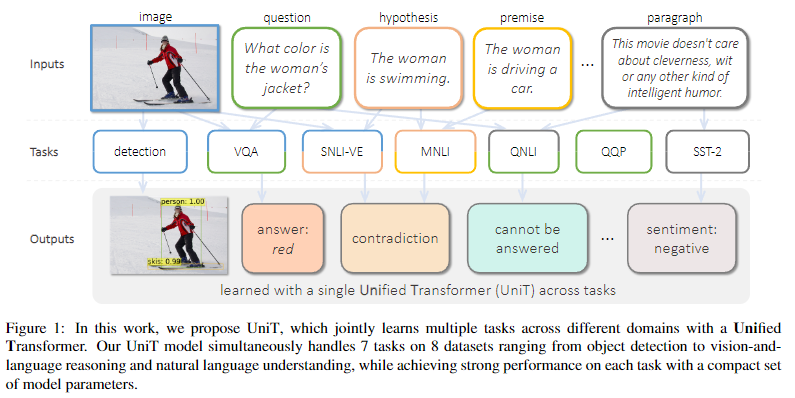
- 본 논문은 Object Detection(computer vision task)부터 Natural language, 멀티모달 추론에 이르기까지 다양한 영역에서 중요한 작업을 동시에 학습할 수 있는 통합 Transformer 모델인
UniT(Unified Transformer)를 제안한다. - Transformer 인코더-디코더 아키텍처를 기반으로 하는 UniT 모델은, 각각의 인코더로 각각 modality의 입력을 인코딩하고, 인코딩된 입력 표현에 대해 공유 디코더로 작업을 예측한 후 작업별 아웃풋 헤드를 생성한다.
- (즉, 인코더는 modality 별로 나누어 사용하지만, 디코더는 공유한다는 의미이다.)
- 전체 모델은 각 task의 loss로, end-to-end로 공동 학습됩니다(각 task별 loss를 한번의 계산으로 산출하여 backpropagation을 진행).
- 트랜스포머를 사용한 이전 multi-task learning 연구들과 다르게, UniT는 task별 모델을 개별적으로 fine-tuning하는 대신 모든 task에서 동일한 모델 파라미터를 공유하고 다양한 도메인에 걸쳐 다양한 tasks을 처리한다.
- 실험에서는 8개의 데이터 세트를 이용해 7개의 task를 공동으로 학습하여 훨씬 적은 수의 파라미터로 각 task에서 강력한 성능을 달성했다.
1. Introduction
- Transformer는 자연어처리에서만 국한되지 않고, 이미지, 비디오, 오디오를 포함한 다양한 도메인에서 큰 성공을 거두었다.
- 이전 연구에서는 대규모 말뭉치로 훈련된 트랜스포머(LLM)가 광범위한 다운스트림 언어 task에 대해 강력한 representations을 학습한다는 사실을 입증한 바 있다.
- Vision 도메인에서는 transformers 기반 모델은 image classification, object detection, panoptic segmentation에서 유망한 결과를 얻었다.
- transformer 모델은 단일 modality을 모델링하는 것 외에도 VQA(visual question answering)와 같은 vision-and-language reasoning tasks에서도 강력한 성능을 발휘합니다.
- 그러나 위와 같은 성과에도 불구하고, specific domains에 transformer를 적용하는데 있어, 여러 도메인에 걸친 다양한 업무를 transformer로 연결하려는 노력은 그다지 많지 않았다.
- 트랜스포머의 성공을 목격하고 나면 자연스럽게 다양한 의문이 생깁니다: 텍스트 입력에 대한 자연어 추론을 위해 훈련된 transformer 모델이 image object detection을 수행할 수 있을까, transformer 기반 image classifier가 textual entailment도 확인할 수 있을까?
- 즉, 전반적으로 general intelligence를 향한 다양한 영역의 작업을 동시에 처리하는 단일 모델을 구축할 수 있을까?
- 이전 연구에서는 이러한 질문 중 일부를 해결하려고 시도했지만 제한된 범위에서만 이루어졌다.
- single domain 또는 specific multimodal domains에서만 적용했다().
- 각 task에 대한 task-specific fine-tuning을 사용하거나, 전체에 대한 전반적인 shared parameters를 활용하지 않고, 일반적으로 N개의 작업에 대해 N개의 매개변수를 사용했다.- 단일 domain에서 관련되거나 유사한 task에 대해서만 multi-tasking을 수행한다.
- 본 논문에서는
Unified Transformer(UniT)라는 모델을 구축했다. - UniT는 images and/or text를 입력으로 받아, 시각적 인식과 자연어 이해부터, vision-and-language reasoning에 이르는 multiple tasks을 공동으로 훈련한다(한번에 훈련한다는 의미).
- UniT는 각 입력 modality를 hidden states(feature vectors)의 sequence로 인코딩하는 transformer 인코더와, 인코딩된 입력 modality에 대한 transformer 디코더로 구성되며, decoder hidden states에 적용되는 task-specific 출력 헤드로 각 작업에 대한 최종 예측을 수행한다.
- 이전에 트랜스포머를 사용한 multi-task learning 연구와 다르게, 본 논문은 UniT만을 훈련하여 훨씬 더 다양한 작업에서 (task-specific하게)잘 확립된 이전 작업과 비슷한 성능을 달성했다(하나의 모델을 훈련시킴으로써, 여러 task에서 각각 task-specific하게 훈련한 모델들과 비슷한 점수를 얻었다는 의미).
- 시각적 질문에 답하는 것과 같은 vision-and-language task뿐만 아니라 vision-only task과 language-only도 가능하다.
2. Related work
Transformers on language, vision, and multimodal tasks
- Transformers 모델에 대한 설명
Multi-task learning with transformers
- encoder-decoder architecture based on transformer’s multi-head attention mechanism 덕분에, input과 output이 다른 domain에서 Multi-task learning이 가능하다.
Contrast to multimodal pretraining
- 이미지 캡션과 같은 multimodal 데이터에 대한 pretraining은 다운스트림의 비전, 언어 또는 멀티모달 task에 도움이 된다.
- 그동안의 연구에서는, pretraining model에 각 다운스트림 작업에서 미세 조정을 통해 특화된 모드 모델을 구축하여 달성하는 경우가 많다.
- 이러한 접근 방식과 달리 본 연구에서는 shared model에서 모든 task를 처리하며, 특정 다운스트림 작업의 fine-tuning으로 인해 도메인 전반의 일반 지식이 손실되지 않는다(여러 영역에서 서로 다른 작업을 공동으로 해결하는 능력은 일반 지능을 향한 중요한 단계라고 생각).
- 의문: 이 모델에서 다시 fine-tuning하면 성능이 더 올라가지않을까?
3. UniT: Unified Transformer across domains
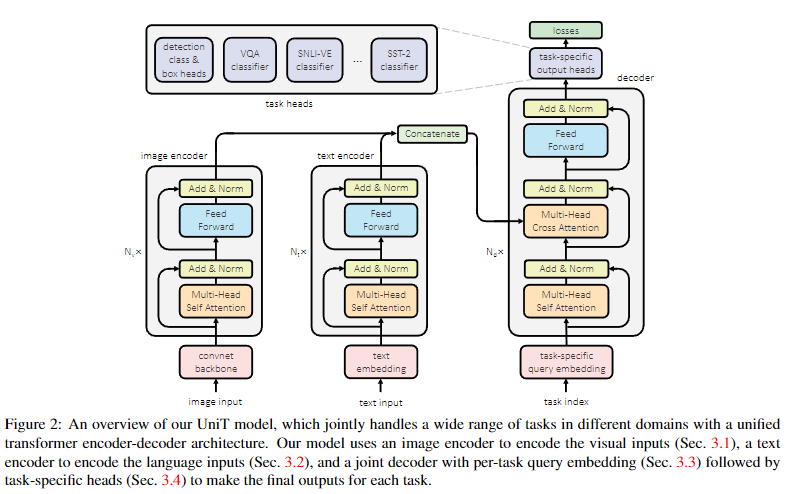
- 유니티의 모델인 UniT는 트랜스포머 인코더-디코더 아키텍처를 기반으로 구축되었으며, 각 입력 modality type에 대한 개별 인코더와, 간단한 task-specific 헤드를 갖춘 디코더(task별 또는 공유)로 구성된다.
- (modality type은 text, image를 구분하는 것이므로, task와 혼동하지 않을 것)
- 본 논문에서는 2개의 modality를 input으로 한다(image, text).
- image input에 대해서는 먼저 convolutional neural network backbone을 적용하여 시각적 feature map을 추출하고, 이를 트랜스포머 인코더를 이용해 hidden states으로 인코딩하여 global contextual 정보를 포함하도록한다.
- language input에 대해서는 12-layer uncased(대소문자 구분 없는 버전) BERT를 이용해 입력 단어(예: 질문)를 BERT의 마지막 layer의 hidden states의 sequence로 인코딩한다.
- 입력 모달리티를 hidden states sequence로 인코딩한 후, 작업이 단일 모달리티(예: 시각 전용 또는 언어 전용)인지, 다중 모달리티인지에 따라 인코딩된 단일 모달리티 또는 두 인코딩된 모달리티를 concat하여 하나의 시퀀스로 트랜스포머 디코더에 적용한다(즉, input modal이 1개면 hidden state를 그대로 전달, image와 text가 모두 있다면 concat해서 전달).
- 마지막으로, 트랜스포머 디코더의 representation은 task-specific head로 전달된다(각 task에 맞는 head를 적용한다는 의미).
- UniT는 8개의 데이터 세트에서 7개의 서로 다른 task을 공동으로 학습할 수 있음을 실증적으로 보여준다.
3.1. Image encoder
- vision-only tasks, vision-and-language task에는 imput 이미지 가 필요하다.
- 이미지 를 convolutional neural network를 통과시킨 다음, transformer encoder를 통과시켜 encoder hidden state 를 얻는다(encoder block의 개수에 따라 N개 생성).
- convolutional neural network의 backbone()으로 ResNet-50을 사용했다.
- feature map 의 크기는 로 아래와 같이 표현한다.
- 이미지 domain의 경우, 마지막 feature map의 개수 L개를 설정하는 것이 중요하다(3.4에서 사용).

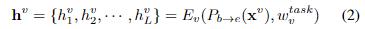
3.2. Text encoder
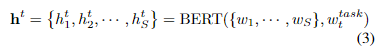
- textual input의 encoder로는 BERT를 사용했다.
- BERT의 input으로 task embedding vector 를 함께 입력한다.
- 실제로는 디코더에 대한 입력으로 의 CLS에 해당하는 hidden vector만 입력하더라도 거의 동일하게 작동하는 것을 확인했다.
- (BERT는 앞서 12-layer uncased version을 사용한다고 언급)
3.3. Domain-agnostic UniT decoder
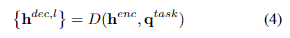
- 입력 모달리티를 인코딩한 후, 각 작업에 대한 예측을 수행하기 위해 hidden size 와 레이어 수 를 가진 transformer 디코더 를 적용하여 디코딩된 hidden state 시퀀스 를 출력한다.
- 각 모달리티에 대해 specific 아키텍처 설계가 적용된 이미지 및 텍스트 인코더와 달리(기존 연구), UniT의 디코더는 모든 task에서 동일한 domain-agnostic(모든 domain이 가능한) 트랜스포머 디코더 아키텍처를 기반으로 구축되었다.
- single domain이라면 encoded hidden state를 그대로, vision-and-language task라면 두 도메인의 encoded hidden state를 concat해서 decoder에 입력한다().
- 이때, decoder 는 input sequence 와 함께 task-specific query embedding sequence 를 입력받는다.
- 각 l번째 decoder layer에서 output으로 decoded hidden states sequence 를 출력한다.
3.4. Task-specific output heads
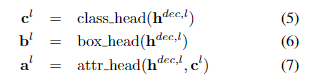
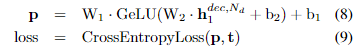
- decoder hidden states 에 대해 task-specific prediction head가 적용된다(이미지는 L마다 적용).
- object detection을 예로 들면, feature map의 개수 L개에 대해 각각 class head, box head, attriute head(근거)가 적용되어 각각 output(class, box, attribute)을 생성한다.
- 다른 task도 비슷하게 작동하며, NLP classification에서는 GeLu를 활성화함수로 하는 2-layer MLP classifier를 적용하며, loss 함수로 cross-entropy를 사용한다.
3.5. Training
4. Experiments
4.1. Multitask learning on detection and VQA
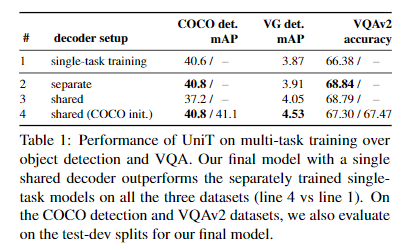
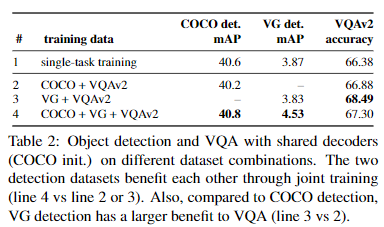
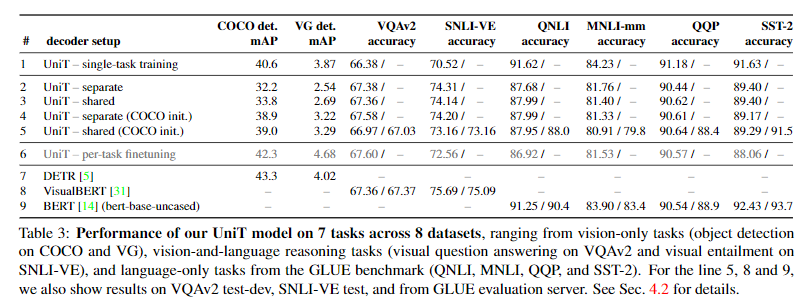
4.2. A Unified Transformer for multiple domains

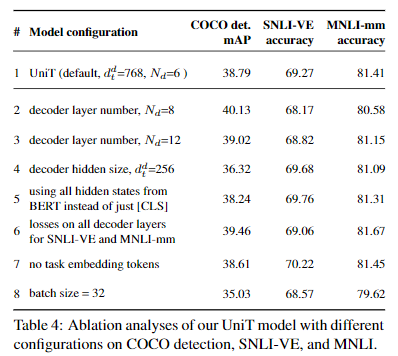
- 디코더 숨겨진 크기(라인 4)가 작을수록 디텍션 mAP가 떨어지지만 SNLI-VE나 MNLI-mm에는 영향을 미치지 않습니다. 이는 COCO가 150만 개의 오브젝트 인스턴스가 있는 더 큰 데이터 세트이고 더 큰 모델의 이점을 활용하기 때문일 수 있습니다. 디코더 레이어 수 Nd(라인 2와 3)에 대한 분석은 Nd = 8이 더 나은 감지 mAP를 제공하므로 이러한 직관을 확증합니다. 한편, 디코더 레이어를 두 배로 늘려 Nd = 12로 설정해도 탐지 성능이 크게 향상되지 않는데, 이는 매우 큰 모델에 과적합하기 때문일 수 있습니다. 또한 디코더 숨겨진 크기가 너무 크면(d d t = 1536) 탐지 훈련에서 편차가 발생할 수 있습니다.
- 모든 BERT 출력을 디코더의 입력으로 사용하면 (3.2절에서와 같이 [CLS] 토큰만 사용하는 대신) 성능에 상대적으로 미미한 (그리고 혼합된) 영향을 미치지만 계산 비용은 증가하므로 (5행), 대부분의 다운스트림 작업에는 BERT의 풀링된 벡터로 충분할 것입니다.
- 중간 계층 출력의 손실은 객체 감지에는 도움이 되지만([5] 참조), SNLI-VE나 MNLI에는 도움이 되지 않는데, 이는 이러한 작업이 고밀도 감지 출력과 달리 단일 레이블만 출력하면 되기 때문일 수 있습니다(6번 라인).
- 인코더에서 태스크 임베딩을 제거해도(라인 7) 성능이 저하되지 않는다는 것을 발견했습니다. 이는 이미지 인코더가 COCO와 SNLI-VE 모두에 적용 가능한 일반적인(작업별이 아닌) 시각적 표현을 추출할 수 있고 언어 인코더도 마찬가지이기 때문인 것으로 추정됩니다.
- 배치 크기(라인 8)가 작을수록 성능이 저하되는 것을 발견했습니다. 또한, 학습률이 클수록(DETR [5]의 1e-4, BERT [14]의 MLM과 같이) 공동 훈련에서 편차가 발생하는 반면, 학습률이 작을수록 안정적인 훈련이 가능하다는 사실도 발견했습니다.
5. Conclusion
- 이 작업에서는 transformer 프레임워크를 다양한 도메인에 적용하여 single unified encoder-decoder 모델 내에서 multiple tasks을 공동으로 처리할 수 있음을 보여준다.
- UniT 모델은 8개 데이터 세트에 걸쳐 7개 task을 동시에 처리하며, single training step으로 학습하고 간결한 shared parameters 세트로 각 task에서 강력한 성능을 달성했다.
- 유니티의 모델은 domain-agnostic(도메인에 구애받지 않는) 트랜스포머 아키텍처를 통해 visual perception, natural language understanding, reasoning over multiple modalities 등 다양한 영역의 광범위한 애플리케이션을 처리할 수 있는 general-purpose intelligence 에이전트를 구축하는 데 한 걸음 더 나아가고 있다.
