Distributed Training이란, 모델/데이터를 여러 개의 GPU로 분산시켜 학습 과정을 병렬화하는 기법이다. 특히 LLM과 같이 엄청난 수의 파라미터를 가진 모델은 단일 GPU로 학습시키는 것이 불가능하기 때문에, 여러 GPU로 분산시켜 학습하는 것이 중요하다.
Data parallelism
Data parallelism은 큰 데이터를 여러 GPU에 분할하여 동시에 처리함으로써 학습 속도를 높이는 기법이다. GPU 간의 출력들을 바탕으로 복제된 모델들을 동일하게 업데이트하는 과정이 필요하다. 모든 GPU로 모델을 복제하는 특성 때문에 메모리 사용량은 증가한다.
Data parallelism은 GPU 간의 출력값들을 바탕으로 복제된 모델을 업데이트하는 방식에 따라 Data Parallel (DP), Distributed Data Parallel (DDP)와 같은 라이브러리가 존재한다.
DP mechanism
- Initialization : 모델을 모든 GPU에 복제하고 데이터셋을 미니 배치 단위로 나누어 각각 할당한다.
- Forward process : 각 GPU들은 할당받은 데이터에 대한 각 연산을 병렬적으로 수행한다. 각 GPU들은 전달받은 데이터의 logit 값을 계산하고, 마스터 GPU가 모든 logit 값을 취합하여 전체에 대한 loss값을 계산한다.
- Backward process : 각 GPU에서 계산된 gradient를 하나의 최종 gradient로 합치고, 마스터 GPU가 병합하여 모델 파라미터를 업데이트한다.
그러나 DP 방식은 마스터 GPU가 logit, gradient를 취합, 전체 loss 계산, 파라미터 업데이트, 업데이트된 파라미터 전송을 혼자 다 하기 때문에 부하가 발생할 수 있다.
DDP mechanism
DDP는 DP에서 발생하는 마스터 GPU의 부하 문제를 해결하기 위해 병목의 원인인 마스터 GPU 개념을 없애고 각 GPU가 알아서 모델을 업데이트하도록 바꾼 방식이다. 대신 모델 업데이트에 필요한 값은 공유되어야 하므로, AllReduce 등의 알고리즘을 도입하였다.
AllReduce는 여러 디바이스에 흩어져 있는 데이터를 서로 동시에 주고받기 위한 Collective Operation 중 하나로, 여러 디바이스에 있는 데이터를 모두 모아 하나의 값(sum, max, min, average 등)으로 줄인 다음 그 결과를 모든 디바이스에 전송한다.
- Initialization : 모델을 모든 GPU에 복제하고 데이터셋을 미니 배치 단위로 나누어 각각 할당한다.
- Forward process : 각 GPU가 데이터와 복제된 모델을 통해 독립적으로 logit을 계산하고 그 logit으로 loss를 계산한다.
- Backward process : 각 GPU가 backpropagation을 통해
gradients들을 계산한다. 그리고 AllReduce 연산을 통해 local gradient들을 모아 averaged gradient 값을 계산한다. 그리고 이 gradient가 동기화되어 모든 GPU가 같은 gradient 값을 가지게 되고 이 값으로 각 GPU가 모델 파라미터를 업데이트한다.
DDP를 구현하는 코드는 다음과 같다.
import os
import torch
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
def ddp_setup(rank, world_size, gpu_list): # rank = GPU 구분 변수 / world_size = GPU 총 개수
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
torch.cuda.set_device(gpu_list[rank])
init_process_group(backend="nccl", rank=rank, world_size=world_size)
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True if torch.cuda.is_available() else Fasle,
shuffle=False,
sampler=DistributedSampler(dataset)
)
class Trainer:
def __init__(self, model, train_data, optimizer, gpu_id, gpu_list):
self.model = DDP(model, device_ids=[gpu_id]
def _run_epoch(self, epoch, max_epochs):
self.train_data.sampler.set_epoch(epoch)
def main(rank, world_size, total_epochs, batch_size, selected_gpus):
actual_gpu_id = selected_gpus[rank]
ddp_set(rank, world_size, selected_gpus)
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, actual_gpu_id, selected_gpus)
trainer.train(total_epochs)
destroy_process_group()
if __name__=="__main__":
# determine which GPUs to use
if args.gpus is not None
# use specified GPUs
available_gpus = torch.cuda.device_count()
for gpu in args.gpus:
if gpu >= available_gpus:
raise ValueError(f"GPU {gpu} is not available. Only {available_gpus} GPUs are present.")
world_size = len(args.gpus)
gpu_list = args.gpus
else:
gpu_list = list(range(torch.cuda.device_count()))
world_size = len(gpu_list)
# multiprocessing spawn
mp.spawn(
main,
args = (world_size, args.total_epochs, args.batch_size, gpu_list),
nprocs=world_size
join=True
)
parser.add_argument('--gpus', nargs="+", type=int, default=None, help='Specific GPU IDs to ues. If not specified, uses all available GPUs.')Model parallelism
큰 모델을 여러 GPU들에 분할하여 학습시키는 기법이다.
Data parallelism vs Model parallelism
| Data parallelism | Model parallelism | |
|---|---|---|
| 병렬 처리 대상 | 데이터 샘플 | 모델 파라미터 |
| 목표 | 학습 속도 가속화 | 거대모델 분할 적재 (초거대 모델 학습) |
| 학습 속도 | GPU 개수에 비례 | 병목으로 인해 속도 저하 |
| 구현 난이도 | 비교적 쉬움 | 구현 및 관리가 어려움 |
모델을 어떻게 나눌 것이냐에 따라 tensor parallelims, pipeline parallelism으로 나눌 수 있다.
Tensor parallelism
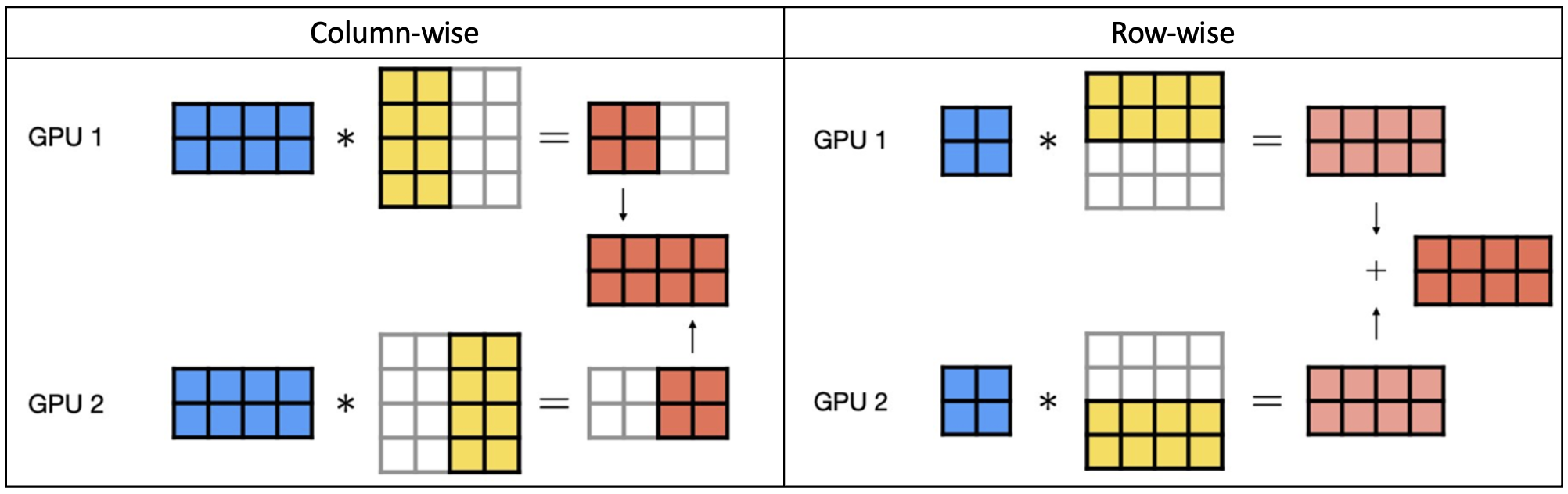
모델을 텐서 연산 단위로 여러 GPU에 나누어 계산하는 방식이다. 텐서 연산은 input weights = outputs과 같은 방식인데 주로 weights 행렬을 나누어 연산한다. 이는 다시 텐서를 어느 방향으로 나눌 것인지에 따라 column-wise (열 방향으로 쪼개기), row-wise (행 방향으로 쪼개기)로 나뉜다. row-wise 연산을 하려면 input도 함께 쪼개줘야 한다.
Pipeline parallelism
모델을 층 단위로 여러 GPU에 할당하여 순차적으로 처리하는 방식이다. 각 GPU가 서로 다른 레이어를 처리하므로 계산 효율성을 높이고 메모리 사용량을 분산할 수 있다. 그러나 스테이지 간 연산량에 차이가 클 경우 대기 시간(latency)이 길어질 수 있다.
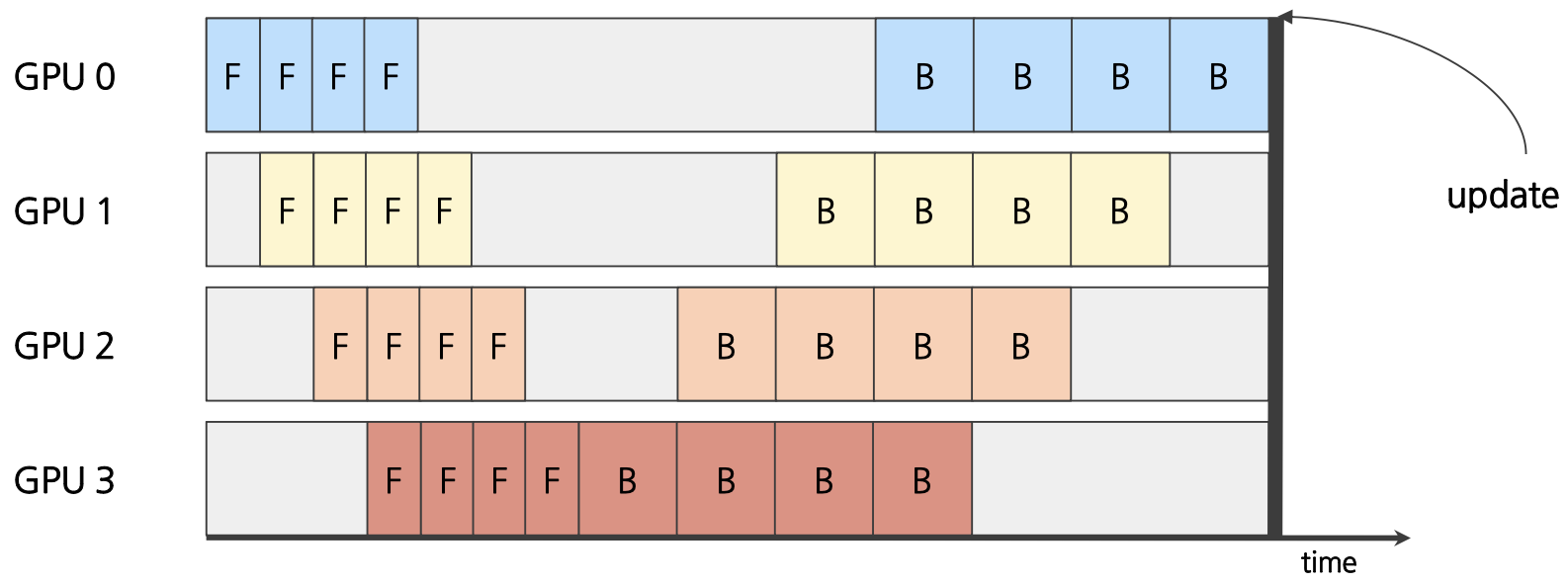
우선 모델을 연속적인 여러 스테이지로 나누어 각 스테이지들을 GPU에 할당한다. 그리도 데이터 batch를 micro-batch 단위로 작게 쪼갠 뒤 데이터를 순차적으로 주입한다. 이 때 batch를 잘게 쪼개서 연산을 일찍 끝낼수록 뒤에 있는 layer 사이의 bubble (아래 참조)이 적게 발생하지만, 너무 작게 분해할 경우 스테이지 간 통신이 너무 빈번해져서 더 오래 걸릴 수 있다. backward process에서는 micro-batch들이 스테이지에 들어간 역순으로 gradient가 계산되고 모델이 업데이트 된다.
각 GPU에서 Forward Pass, Backward Pass의 순서를 지켜 데이터를 처리하는지에 따라 Synchronous와 Asynchronous 방식으로 나뉜다.
- Synchronous pipeline : 각 GPU가 Forward Pass, Backward Pass의 순서를 지켜 처리하여 micro-batch의 gradients를 동기적으로 계산한다. Forward 연산을 마치기 전까지 Backward 연산을 실행하지 않고, 모든 backward 연산을 마치면 한꺼번에 모델 업데이트를 진행한다. 각 GPU는 이전의 스테이지가 끝나야지만 연산을 시작할 수 있기 때문에, GPU가 연산을 하지 못하는 bubble이 생기게 된다. (각 연산과 연산 사이의 회색 빈 칸)
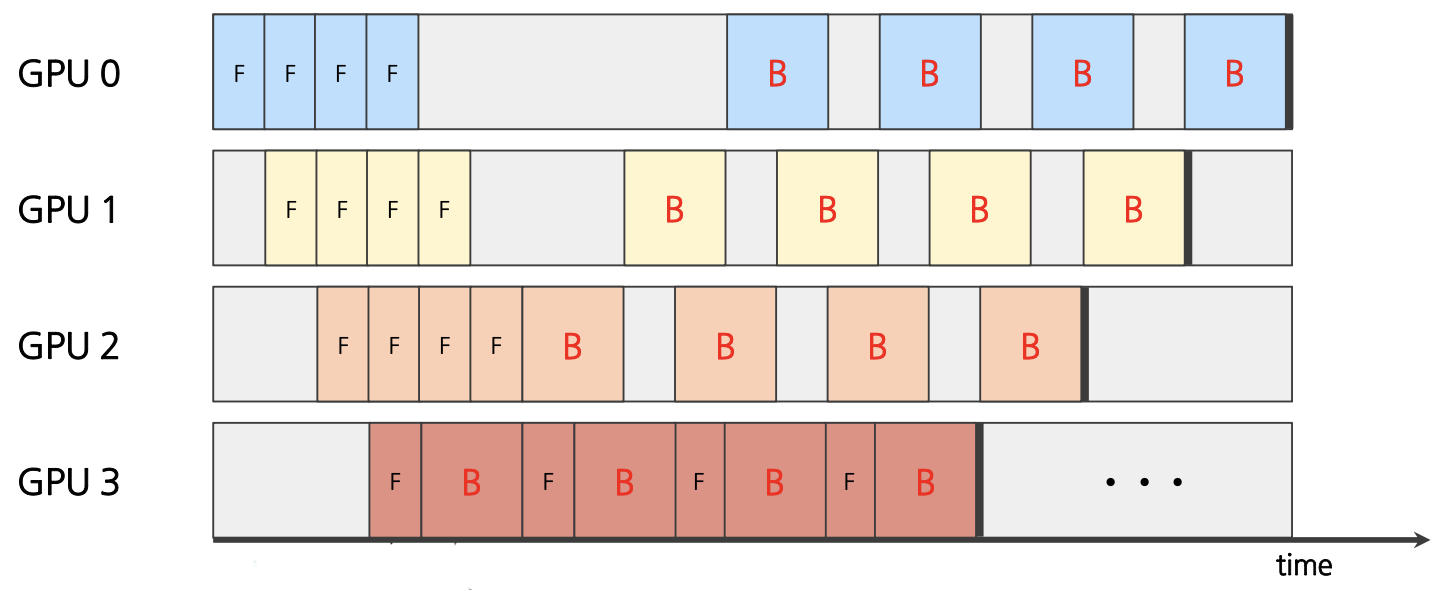
- Asynchronous : 각 GPU가 Forward Pass, Backward Pass를 번갈아 처리함으로써 gradients가 각 GPU에 따라 비동기적으로 계산되는 방식이다. 각 파이프라인 단계가 다른 GPU 연산 완료 여부와 상관없이 독립적으로 작동하여 더욱 빠르게 다음 micro-batch를 처리하게 되고, 이 덕분에 bubble을 줄일 수 있다.
| Synchronous pipeline | Asynchronous pipeline | |
|---|---|---|
| 학습 속도 | 학습 속도가 크게 증가 (but 동기화 과정에서 병목 현상이 발생할 수 있음) | 동기화 과정이 없으므로 학습 속도 크게 증가 |
| 메모리 효율성 | ↓ | ↑ |
| 수렴도 | 안정적, 모델의 정확도 높음 | 불안정, 정확도 낮음 |
| 장점 | 구현이 쉬움 | 학습 속도, 메모리 효울성 증가 |
| 단점 | gradient 동기화 과정으로 인한 bubble | 구현이 매우 복잡 |
| 사용 전략 | 동일한 GPU를 여러 개 사용하고 안정적으로 수렴해야 할 때 | GPU 환경이 각각 다르고 메모리 효율성을 최대화할 떄 |
