Parameter-Efficient Fine-Tuning (PEFT)은 모델의 일부분만 학습시키는 방법이다. 최근 거대 모델들이 많이 발달하면서 학습 시간과 비용이 많이 증가했고, 이를 PEFT 등을 통해 효율적으로 학습하고자 하는 시도가 늘고 있다. 이전 LLM 포스팅에서도 PEFT를 다뤘었는데, 여기서는 더 자세히 공부해보자.
전이 학습(transfer learning)이란, 이미 학습이 완료된 모델을 새로운 작업의 시작점으로 모델을 재사용하는 기계학습 방법론이다. 전이 학습은 크게 Pre-training과 Fine-tuning의 두 가지 패러다임으로 나뉘는데, 전자는 방대한 양의 데이터로 모델을 사전 학습 시키는 것이고, 후자는 새로운 작업을 위한 특정 데이터로 모델을 재학습시키는 것을 말한다.
그 중에서도 Fine-Tuning은 보통의 사전 학습 모델은 문제 해결능력이 없기 때문에, 새로운 작업에서의 문제 해결 능력을 얻기 위해 새로운 데이터로 사전 학습 모델을 재학습하는 것이다.
방법론
아래의 두 방법은 독립적이기 때문에 결합하여 사용할 수 있다.
Prompt tuning 방식
모델의 원래 파라미터를 변경하지 않고도 모델의 출력을 원하는 방향으로 유도하는 방식이다. Prompt Tuning, Prefix Tuning, P-Tuning 등이 예시이다.
파라미터 삽입 방식
모델의 특정 위치에 추가적인 학습 가능한 파라미터를 삽입하여 모델을 미세 조정하는 방식이다. Adapter, LoRA, Compacter 등이 예시이다.
Adapter
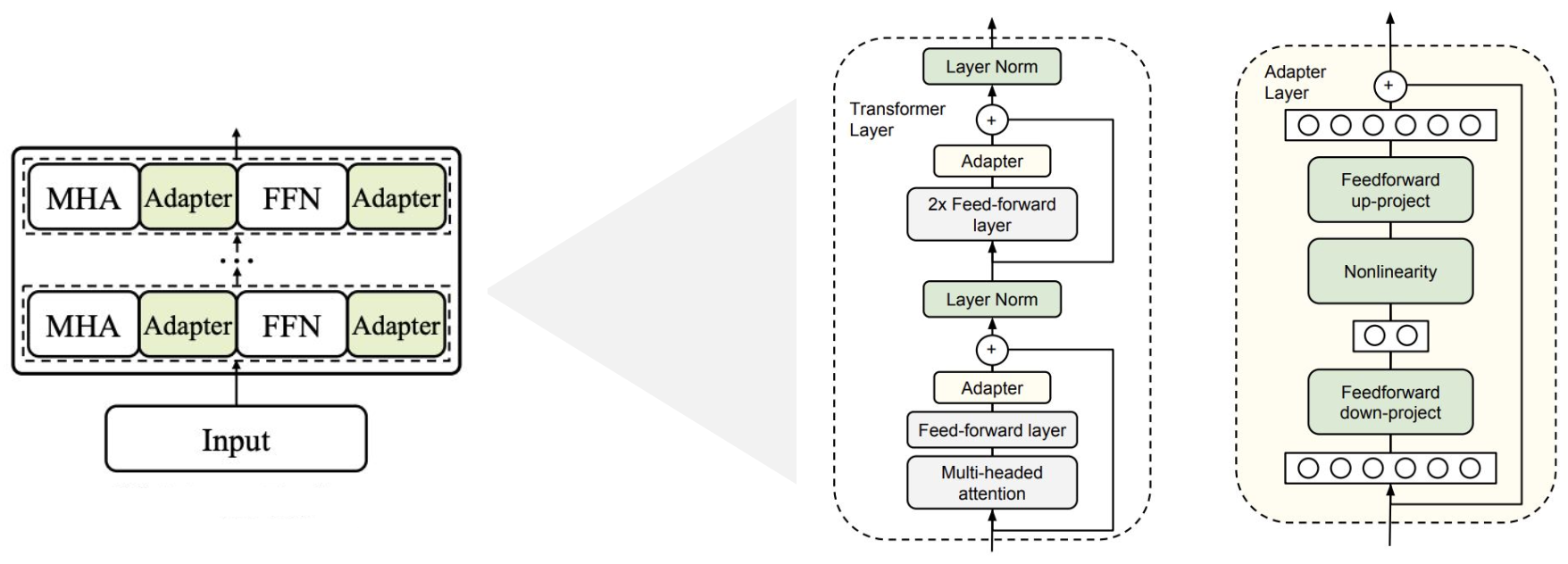
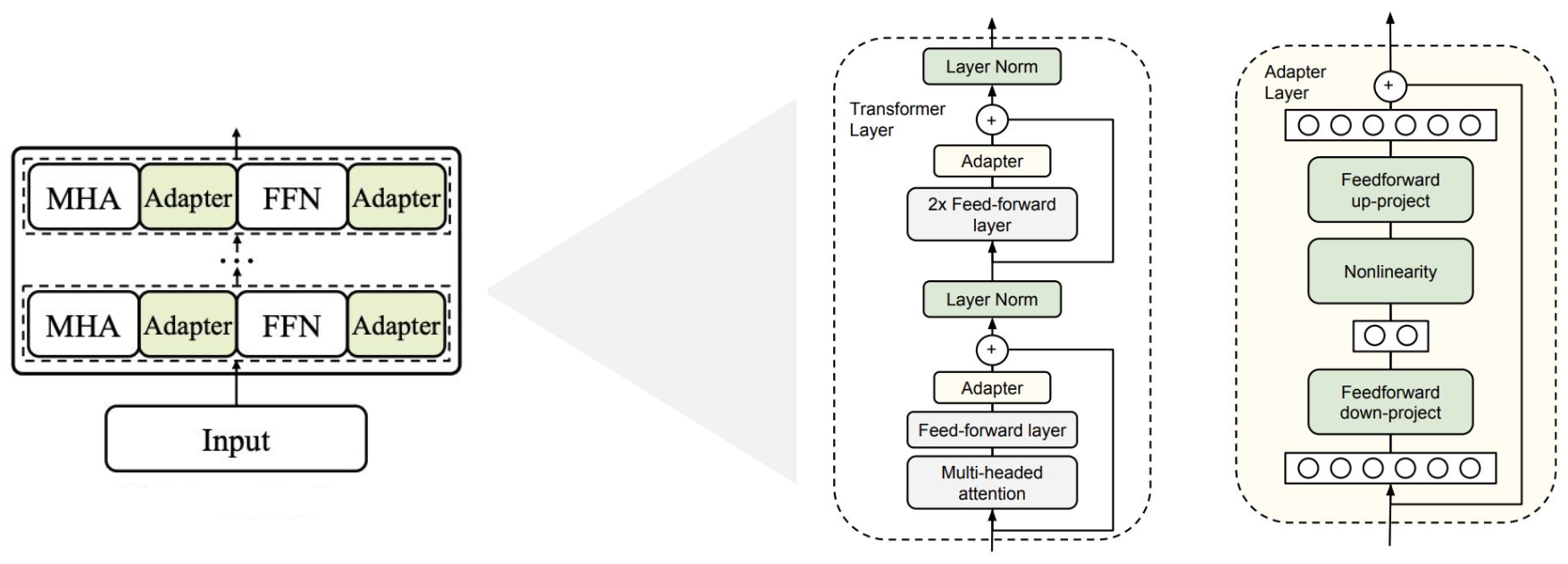
기존의 모델 각 레이어 사이에 학습 가능한 adapter 모듈을 삽입하는 방식이다. adapter 모듈은 bottleneck 구조의 Feed-forward Neural Network와 skip-connection으로 구성되어 있다.
feedfoward down-project에서 차원을 축소한 후에 nonlinearity를 적용한 후 feedforward up-project에서 차원을 확장하여 원래대로 복구한다. (→ bottleneck)
skip-connection은 bottleneck 구조 이전의 input을 차원이 복구된 이후에 다시 더해주며 적용된다.
Low-rank decomposition
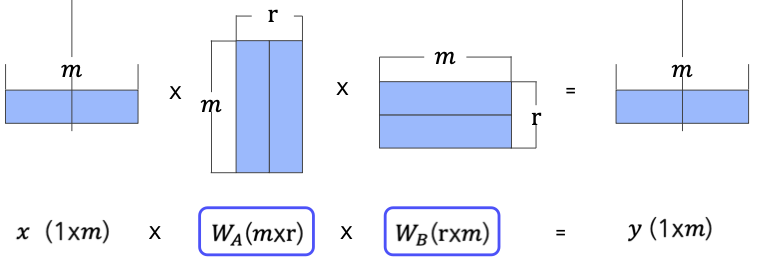
Low-rank decomposition은 고차원 행렬을 저차원 행렬의 곱으로 분해하는 기법이다. 이 방법을 사용하면 큰 행렬을 작은 크기의 행렬로 근사할 수 있기 때문에, 적은 수의 파라미터만을 학습할 수 있다.
위의 그림에서, Feed-forward network의 weight matrix가 기존에는 mm 차원이었지만, 두 개의 작은 matrix mr, rm ( < ) 의 곱으로 쪼갠다. 예를 들어 m = 300인 weight matrix가 있었고 rank = 10이라면, 300 300이었던 matrix가 300 10으로 변환된다. (→ down-projection) 이렇게 압축된 적은 수의 파라미터를 효율적으로 학습한 후, 나머지 weight matrix인 10 300를 곱함으로써 up-projection을 수행한다. 이러한 과정에 의해 bottleneck 구조가 형성된다.
LoRA
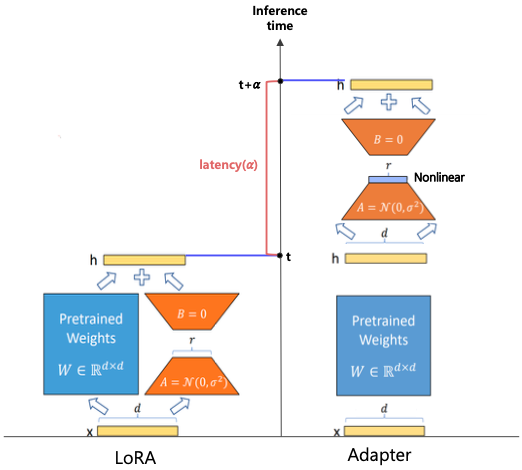
LoRA(Low-Rank Adaptation)는 사전 학습 모델 가중치는 고정한 채로 각 층에 랭크 분해 학습 가능한 rank decomposition 행렬을 병렬적으로 삽입하는 방식이다. 비선형 함수를 사용하지 않고, bias 파라미터를 학습하지 않기 때문에 Adapter보다 속도 측면에서 효율적이다. Adapter와 비슷하게 low-rank decomposition이 사용되지만 병렬적으로 계산하는 구조로 되어있다.
Adapter vs LoRA
| Adapter | LoRA | |
|---|---|---|
| 모듈 연산 방법 | sequential | parallel |
| 추가 비선형 함수 | O | X |
| 학습 파라미터 | weight, bias | weight |
| 연산 지연 | 모듈에 비례하여 발생 | 거의 발생하지 않음 |
AdapterFusion
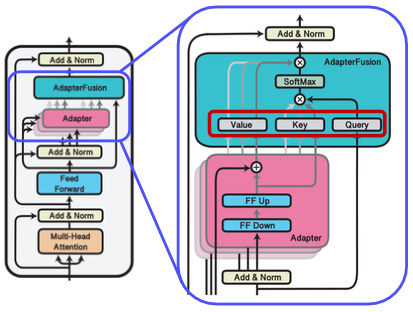
기존에는 태스크 별로 adapter를 적용하여 해당 태스크에 적합한 모델을 만들었지만, AdapterFusion은 여러 개의 adapter 모듈을 결합해서 다양한 태스크를 수행할 수 있도록 하는 기법이다. 사전 학습된 모델의 파라미터는 공유하는 상태에서 adapter만 바꾸어서 특정 태스크를 수행하도록 빠르게 전환할 수 있다. knowledge extraction과 knowledge composition의 2-stages algorithm으로 동작한다.
Knowledge extraction
n개의 specific task에 대한 n개의 adapter parameter를 개별적으로 학습한다.
Knowledge composition
입력에 따른 적절한 adapter 결과를 선택해서 합친다. 우선 병렬적으로 각 adapter 값의 출력을 계산하고, attention을 이용해 각 출력을 취합하여 weighted sum으로 최적의 출력을 만들어낸다. 이 때 사용자 입력에 맞는 adapter의 가중치를 측정하는 attention 모듈만 재학습시킨다.
QLoRA
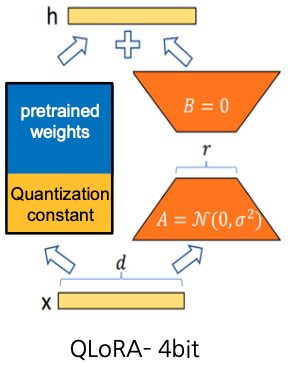
QLoRA는 LoRA에 Quantization 기법을 추가로 활용해서 더 효율적으로 작동하게 하는 기법이다. 사전 학습 모델의 가중치에 대해 2가지 quantization 기법을 적용한다.
- 16 bit으로 이루어진 가중치에 대해 4-bit Normal-Float Quantization을 적용
이 때 생기는 양자화 상수는 따로 저장되는데, scale과 zero-point는 높은 pecision으로 저장된다. - 양자화 상수도 quantization (Double quantization)
in Practice
LoRA
LoRA를 BERT_base 모델에 적용해보자. 데이터는 SQuAD dataset을 이용해본다. (위키피디아 기반 질문-답변으로 이루어진 데이터 셋)
# 기존 모델 파라미터 고정
for param in model.parameters():
param.requires_grad = False
# LoRA
lora_config = LoraConfig(
r=2, # low-rank factor (google colab에서는 1-4 정도가 적당)
lora_alpha=16, # 학습된 low-rank matrix에 곱해지는 값. 모델의 수렴을 도움 (값은 실험적으로 정함)
target_modules=["query", "value"],
lora_dropout=0.1 # dropout으로 overfitting 방지
)
model_with_lora = get_peft_model(model, lora_config)실습 강의 보고 보충하기
References
https://arxiv.org/abs/1902.00751
https://arxiv.org/abs/2106.09685
https://arxiv.org/abs/2005.00247
