Ensemble은 머신 러닝의 다양한 기법들 중 하나로, 여러 개의 간단한 모델(weak learner이라 부른다.)을 생성한 후 그 모델들의 예측값을 종합하여 하나의 최종 모델 또는 예측값을 도출하는 것이다. 아래의 그림이 ensemble 기법을 잘 보여주고 있다.
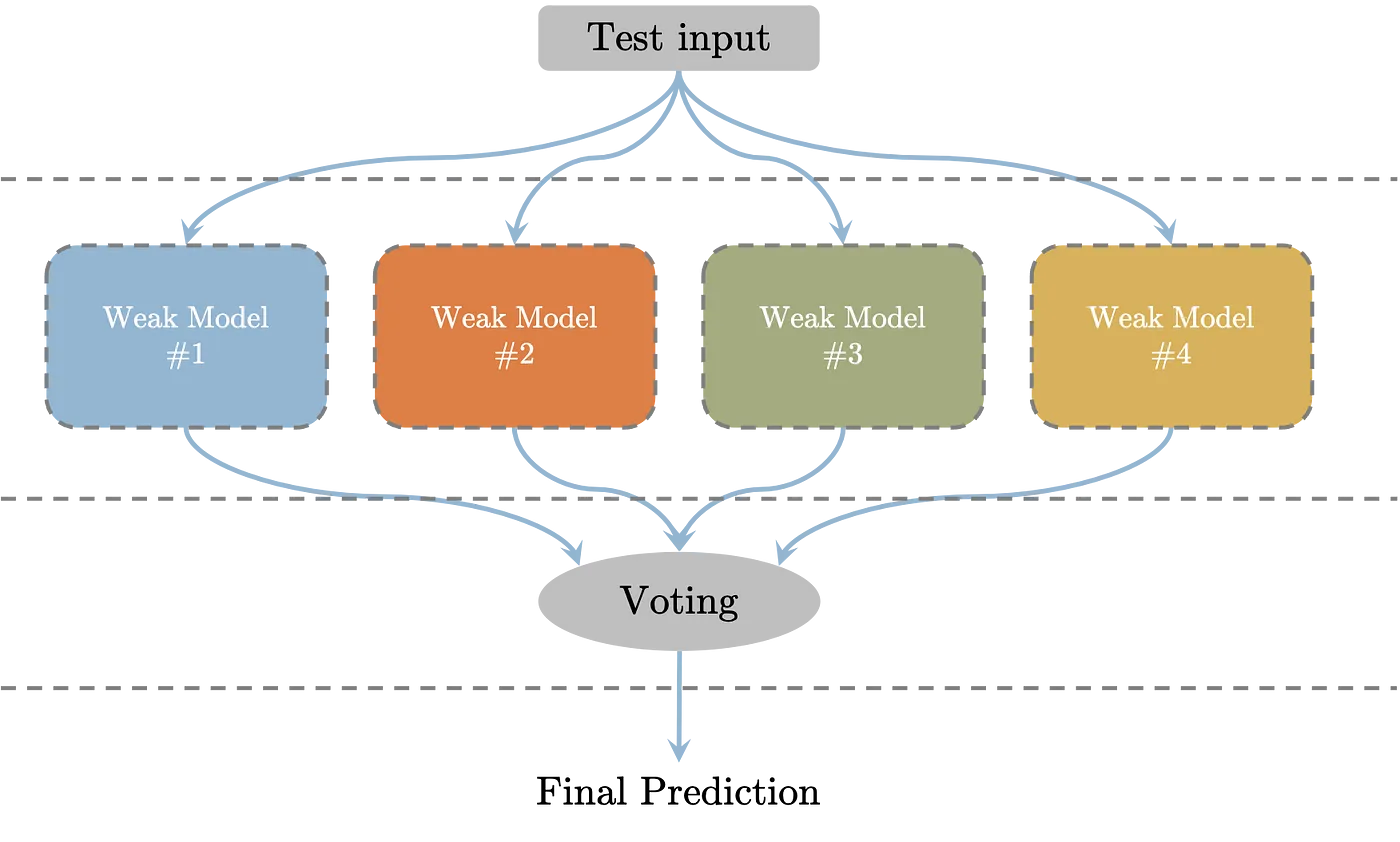
Ensemble 기법은 크게 bagging, boosting, stacking의 3가지로 나눌 수 있다.
Bagging
Bagging은 Bootstrap Aggregating 을 줄인 말이다.
** bootstrap : 주어진 샘플에서 중복을 허용하여 무작위로 임의의 샘플 set을 여러 개 만들고 이를 통해 모집단 혹은 주어진 샘플보다 큰 데이터에 대한 분포를 추정하는 기법
Bagging은 training set에서 샘플을 bootstrap으로 추출한 후 여러 모델들로 학습시키고 그 결과를 합쳐서 최종 예측값을 도출하는 방식이다. 일반적으로 Bagging은 여러 모델들을 하나로 합치면서 variance가 감소되는 효과가 있다. 즉, overfitting을 완화할 수 있다.
Bagging에도 다양한 기법들이 있는데 그 중에서도 random forest와 extra tree를 보도록 하자.
Random forest
random forest의 주요 흐름은 다음과 같다.
- training set에서 다수의 샘플 set을 bootstrap으로 추출한다.
- 전체 feature 중 일부 feature만 랜덤하게 선택하여 여러 개의 decision tree를 만든다.
- 각 decision tree를 샘플 set으로 학습시킨다.
- test set으로 각 decision tree별 예측값을 구하고 투표를 통해 다수결로 최종 예측값을 결정한다.
scikit-learn에 random forest 기법이 구현되어 있다.
from sklearn.ensemble import RandomForestClassifier
random_model = RandomForestClassifier()Extra tree
extra tree는 전체적인 흐름은 random forest와 유사하지만 샘플 set의 수도 랜덤하게 결정하고 분류 조건도 랜덤하게 분할하여 무작위성이 더 크다.
extra tree도 scikit-learn에 구현된 것을 이용할 수 있다.
from sklearn.ensemble import ExtraTreesClassifier
extra_model = ExtraTreesClassifier()Boosting
boosting은 training set을 여러 개로 나누어 병렬적으로 weak learner들의 결과를 합치는 bagging과는 다르게, training set 전체에 여러 개의 weak learner를 연속적으로 학습시키는 것이다. 이 과정에서 이전 weak learner가 예측한 결과 중 예측이 잘못된 데이터에 가중치를 두어 다음 weak learner에서 예측을 수행한다. 모든 weak learner에 대해 예측이 완료되면 weak learner별 가중치와 예측이 잘못된 데이터의 수 등을 고려하여 최종 예측값이 결정된다. 이러한 기본적인 boosting 기법을 adaptive boosting이라고 한다. 일반적으로 boosting 기법은 bias를 감소시킨다.
boosting에는 여러 가지 기법이 있는데 Gradient Boosting Machine, XGBoost, LightGBM 등이 있다.
- Gradient Boosting Machine
Gradient Boosting Machine (GBM) 은 이전 weak learner에서 예측이 잘못된 데이터를 바탕으로 모델을 보정할 때, gradient descent (경사하강법) 함수를 사용하는 기법이다. residual (실제값과 예측 값의 차이)을 줄이는 데에 gradient descent를 사용한다. GBM은 scikit-learn에 구현된 것을 아래와 같이 사용할 수 있다.
from sklearn.ensemble import GradientBoostingClassifier
gbm_model = GradientBoostingClassifier()- XGBoost
GBM은 training set에 overfitting될 가능성이 높다. 이를 개선하기 위해 수학식을 추가하는 regularization을 이용하고, 병렬적으로 연산할 수 있도록 성능을 개선시킨 것이 XGBoost이다. scikit-learn에서 구현된 XGBoost는 아래와 같다.
from xgboost import XGBClassifier
xgb_model = XGBClassifier(eval_metric='logloss') # 평가식을 logloss로 설정- LightGBM
XGBoost는 GBM에 비해 overfitting 문제가 개선되고 병렬적으로 연산할 수 있게 되었지만, 여전히 학습 시간이 느린 편이다. LightGBM은 대용량 처리가 가능하고, GPU를 지원하여 더 작은 메모리를 이용하는 모델이다. lightBGM은 scikit-learn에서 구현된 것을 사용할 수 있다.
from lightgbm import LGBMClassifier
lgbm_model = LGBMClassifier()Stacking
stacking은 개개의 weak learner로 학습한 후 예측한 데이터를 쌓아서 또 다른 training set을 만들고, 이를 바탕으로 예측하는 기법이다.
References
https://towardsdatascience.com/what-are-ensemble-methods-in-machine-learning-cac1d17ed349
https://velog.io/@sset2323/04-10.-%EC%8A%A4%ED%83%9C%ED%82%B9-%EC%95%99%EC%83%81%EB%B8%94#2-%EA%B8%B0%EB%B3%B8-%EC%8A%A4%ED%83%9C%ED%82%B9-%EB%AA%A8%EB%8D%B8
https://dacon.io/codeshare/4651
