hyperparameter란, 머신 러닝에서 모델을 생성할 때 사용자가 직접 입력하는 변수이다. hyperparameter는 학습 프로세스의 세부 사항을 지정하는데, 이는 모델 자체를 결정하는 매개변수와는 다른 개념이다.
hyperparameter tuning은 머신 러닝의 성능을 최적화하기 위한 hyperparameter의 값을 찾는 작업이다. 예를 들어, K-Nearest Neighbor 모델에서 데이터의 분류를 가장 잘 해내는 k값이 무엇인지 찾는 것이다.
hyperparameter tuning에는 Grid search, Random Search, Bayesian optimization 등의 다양한 기법이 있다.
Grid search
사용자가 가장 적절하다고 생각하는 hyperparameter 값들의 리스트를 입력하면, 그 값들을 테스트해서 가장 높은 성능을 내는 값을 알려주는 기법이다.

위 그림은 두 hyperparameter x1, x2의 가장 최적화된 값을 찾기 위해 x1과 x2를 각각 0과 1 사이의 후보값 10개씩 입력하여 설정된 grid에서 성능을 평가한 결과를 보여주고 있다. 파란색 윤곽선은 성능이 좋은 것을 의미하고, 빨간색 윤곽선은 성능이 나쁜 것이다. 따라서 파란색 윤곽선 내에 있는 x1과 x2의 값을 채택하면 가장 좋은 성능을 낼 수 있다.
scikit-learn에서 구현된 grid search는 아래와 같이 사용할 수 있다.
from sklearn.model_selection import GridSearchCV
gird = GridSearchCV(estimator, param_grid, verbose, cv, scoring, n_jobs)Random search
random search는 grid search와 기본적인 개념은 같지만, hyperparameter의 특정한 값을 입력하는 것이 아니라 가장 적절한 hyperparameter 값이 있을 법한 범위를 입력한다. 그러면 해당 범위 내에서 랜덤하게 값을 추출해서 가장 높은 성능을 내는 값이 무엇인지 찾아준다.

위 그림에서 그 의미를 확인할 수 있는데, 0과 1 사이라는 범위를 지정해주었을 때 보다 더 무작위하게 x1과 x2값이 설정되어 성능이 계산된 것을 확인할 수 있다. 다만 랜덤하게 값을 선택하기 때문에 반복 실행을 많이 해야만 더 확실한 최적의 값을 찾아낼 수 있다.
scikit-learn에서 구현된 random search는 아래와 같이 사용할 수 있다.
from sklearn.model_selection import RandomizedSearchCV
random = RandomizedSearchCV(estimator, param_distributions, n_iter, cv, scoring, random_state, n_jobs)Bayesian optimization
Bayesian optimization은 hyperparameter 값과 그 hyperparameter 값을 사용했을 때 나오는 성능 사이의 관계를 연결짓는 확률 모델을 만든다. 이전의 hyperparameter 값과 그를 이용한 성능값을 사전지식으로 활용해서 확률 모델을 업데이트하고, 그를 바탕으로 다음에 어떤 hyperparameter 값을 넣어야 가장 적절할지를 결정한다.
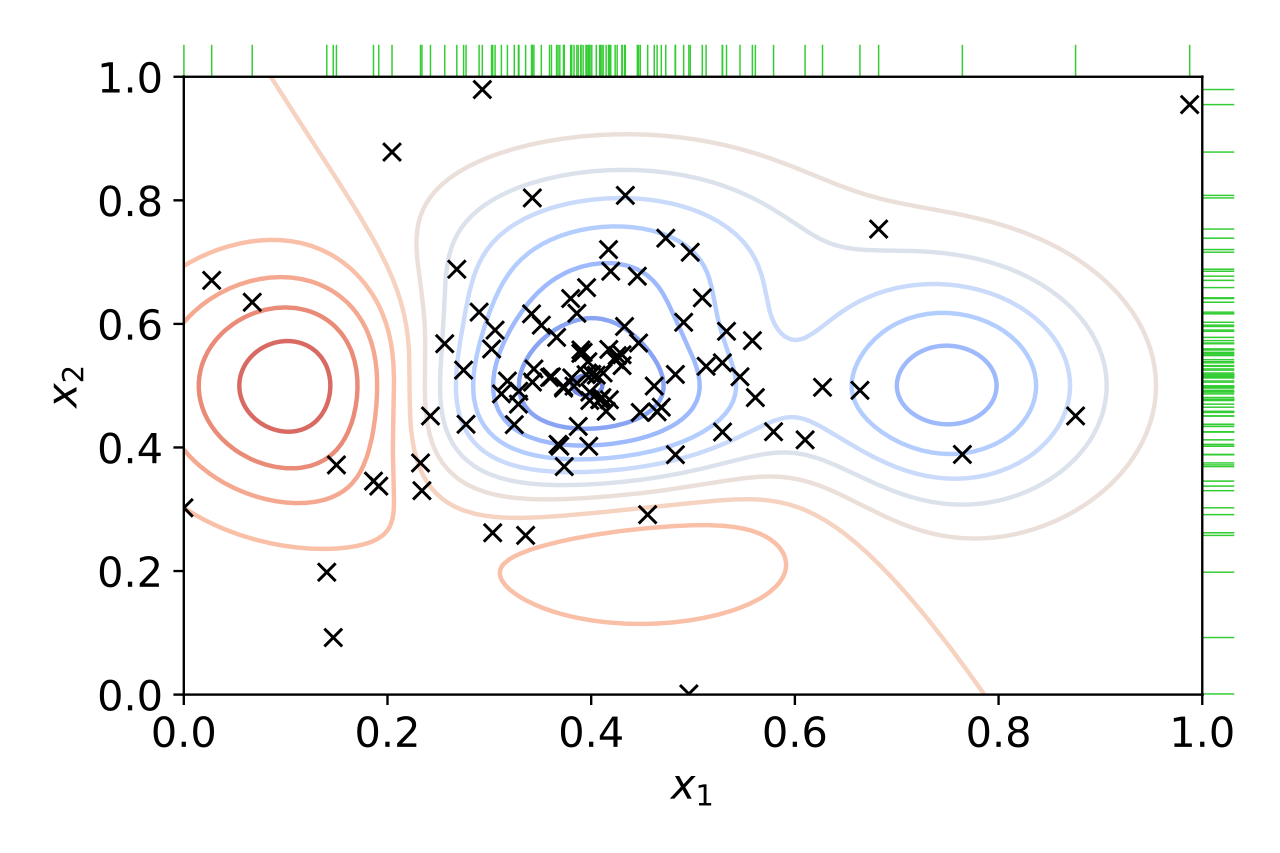
위 그림에서 그 모습을 확인할 수 있다. 이전의 x1, x2 값을 이용해 얻은 성능 값을 바탕으로 그 다음에 가장 적절한 x1, x2 값을 탐색하기 때문에, 점차 성능이 좋은 x1, x2 값을 향해 수렴하는 모습을 볼 수 있다.
Bayesian optimization은 파이썬 라이브러리를 별개로 설치해야 한다.
pip install bayesian-optimization설치하고 아래와 같이 사용할 수 있다.
from bayes_opt import BayesianOptimization
bayesian = BayesianOptimization(f, pbounds, random_state)References
https://en.wikipedia.org/wiki/Hyperparameter_(machine_learning)
https://en.wikipedia.org/wiki/Hyperparameter_optimization
