선형 판별 분석(Linear Discriminant Analysis; LDA)는 차원을 축소하여 분류를 하는 데 사용되는 기법이다.
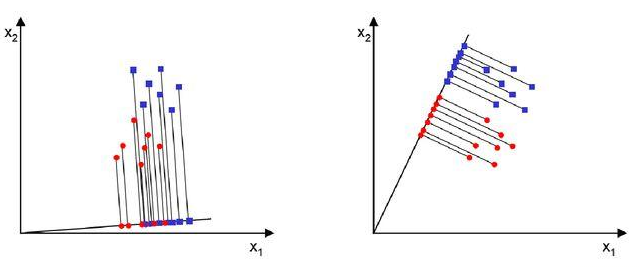
LDA는 데이터를 저차원 공간으로 투영하여 클래스끼리 최대한 분리할 수 있는 축을 찾는다. 위의 그림 예시를 보면 잘 이해가 될 것이다. 왼쪽이 PCA인데, 데이터의 변동성이 최대가 되는 축을 찾아 주성분으로 정하는 방법이라 서로 다른 클래스(빨간색, 파란색)가 겹쳐서 구분이 되지 않는다. 반면에 오른쪽 LDA는 클래스 간의 분산은 최대한 키우고 클래스 내부의 분산은 최대한 작게 하는 축을 찾기 때문에 같은 클래스끼리는 오밀조밀 뭉치고 다른 클래스와는 명확히 구분할 수 있게 된다.
여기에 Iris dataset을 사용하여 LDA를 사용하는 구체적인 예시를 살펴보자. 우선 4차원 (petal width, petal length, sepal width, sepal length) 데이터를 시각화 해보자.
from sklearn.datasets import load_iris
import pandas as pd
from matplotlib import pyplot as plt
iris = load_iris()
# iris 데이터를 data frame 형식으로 변환
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['target'] = iris.target
# 4D visualization
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, projection='3d')
# 3개의 특성 선택
x = iris_df['sepal length (cm)'] # 꽃받침 길이
y = iris_df['sepal width (cm)'] # 꽃받침 너비
z = iris_df['petal length (cm)'] # 꽃잎 길이
# 4번째 차원(꽃잎 너비)은 색상으로 표현
c = iris_df['petal width (cm)']
# 클래스별로 다른 마커 사용
markers = ['o', '^', 's']
colors = ['blue', 'red', 'green']
for i, species in enumerate(iris.target_names):
idx = iris.target == i
ax.scatter(x[idx], y[idx], z[idx], c=c[idx], marker=markers[i], label=species, cmap='viridis', s=50, alpha=0.7)
ax.set_xlabel('sepal length (cm)')
ax.set_ylabel('sepal width (cm)')
ax.set_zlabel('petal length (cm)')
cbar = plt.colorbar(plt.cm.ScalarMappable(cmap='viridis'), ax=ax, pad=0.1)
cbar.set_label('petal width (cm)')
plt.legend()
plt.title('Iris dataset 3D visualization(color = petal width)')
plt.tight_layout()
plt.show()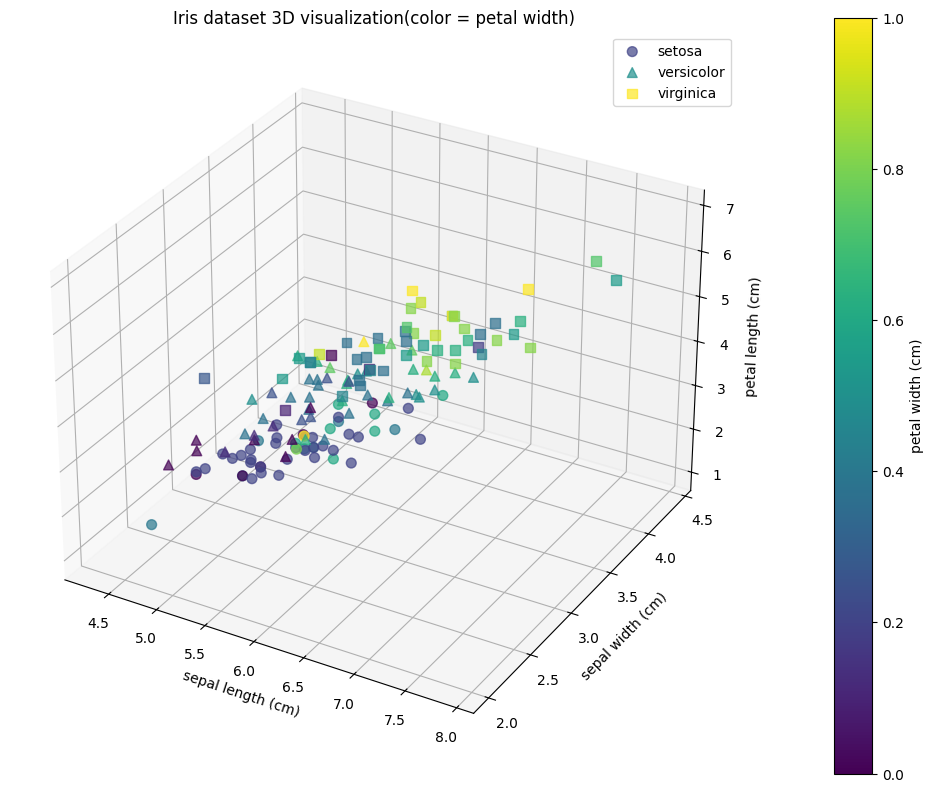
보다시피 굉장히 복잡하고 클래스끼리 겹쳐 있어서 명확히 구분하기 힘들다. 이럴 때 LDA를 활용하여 setosa는 setosa끼리 뭉치고, versicolor은 versicolor끼리 뭉치도록 하면서 setosa와 versicolor 사이의 분산은 커지는 축을 찾으면 차원을 축소하면서 명확히 구분할 수 있게 된다.
4개의 차원을 하나의 차원으로 줄여보자. scikit-learn에서 LDA를 불러올 수 있다.
아래와 같은 코드를 실행하여 LDA로 데이터를 축소하면 "LD1"이라고 이름 붙이는 하나의 값이 되고 이 값이 setosa, versicolor, virginica를 명확히 구분하는 것을 볼 수 있다.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import seaborn as sns
lda = LinearDiscriminantAnalysis(n_components=1)
X_lda = lda.fit_transform(iris.data, iris.target)
# data frame 형식으로 변환
df = pd.DataFrame(X_lda, columns=["LD1"])
df["target"] = iris.target
df["target"] = df["target"].map({0: "setosa", 1: "versicolor", 2: "virginica"})
# visualize
plt.figure(figsize=(8, 2))
sns.stripplot(data=df, x="LD1", y="target", palette="Set1", size=10, jitter=True, orient="h")
plt.title("LDA: 1D Projection of Iris Dataset")
plt.xlabel("Linear Discriminant 1")
plt.grid(True)
plt.show()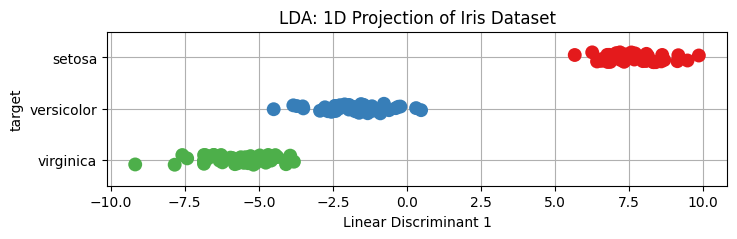
References
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-18-%EC%84%A0%ED%98%95%ED%8C%90%EB%B3%84%EB%B6%84%EC%84%9DLDA
https://slidesplayer.org/slide/16218884/
https://blog.naver.com/paragonyun/222465847517
