기존의 neural network는 시간에 따라 변하지 않는 input to output 예측을 하는 모델이다. 그러나 시간에 따라 달라지거나 순서가 있는 데이터를 다룰 때가 있고, 그러한 sequenced data를 다루기 위해 RNN이 고안되었다.
Recurrent Neural Network (RNN)
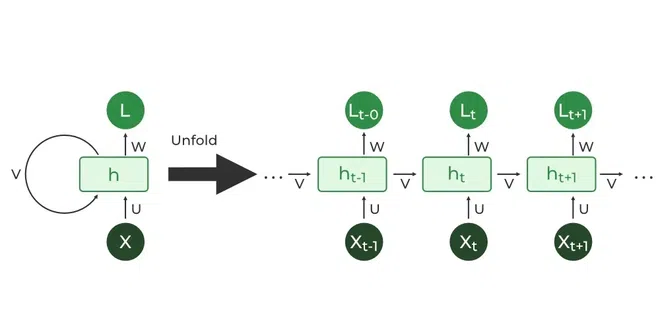
RNN은 위의 그림에서 볼 수 있듯이 output이 다시 자신의 input으로 되는 (recurrent) 흐름을 가지는 구조이다.
-
장점
- 가변적인 길이의 input sequence를 처리할 수 있다.
- 입력이 많아져도 모델의 크기는 증가하지 않는다.
- t 시점에서 수행된 계산은 여러 단계의 이전 정보를 사용할 수 있다.
- 모든 단계에서 동일한 가중치가 적용된다.
-
단점
- Recurrent computation이 느리다.
- 병렬화가 어렵다.
- vanilla RNN은 훈련 중 기울기 소실 (vanishing gradient) 혹은 기울기 폭발 (exploding gradient) 문제를 겪는다.
- vanilla RNN은 장거리 의존성을 모델링하는데 실패한다.
- 여러 단계 이전의 정보에 접근하기 어렵다.
- input의 크기와 output의 크기가 같아야 한다.
* vanilla OO는 기본 OO을 의미한다. 즉 위는 다른 응용 등이 없는 기본 RNN을 의미.
gradient clipping
vanilla RNN에서 생기는 기울기 폭발 문제를 해결하기 위해 대책으로 나온 것이 gradient clipping이다. 계산된 graident가 특정 threshold를 넘기면 최대값으로 클리핑하는 방법이다.
Long Short Term Memory (LSTM)
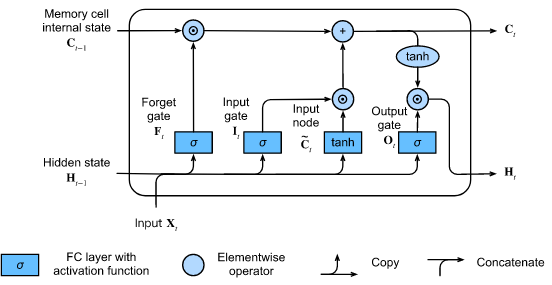
LSTM은 vanishing/exploding gradient 문제를 해결하면서도 이전 단계의 정보에 접근하기 위해 고안된 모델이다.
gradient가 사라지거나 폭발하는 문제를 해결하기 위해서 cell state라 불리는 새로운 hidden state와 weight를 곱하고 더하는 단계를 우회하는 highway를 도입했다.
cell state는 장기 기억을 담당한다. cell state에는 forget gate, input gate, output gate라는 것이 도입되어 있다. forget gate는 input 및 계산을 거친 정보를 얼마나 버릴지(cell로 넘기지 않을지)를 결정한다. 이와 반대로 input gate는 현재 정보가 얼마나 장기 기억 장치로 저장될지 조절한다. output gate는 현재 정보가 장기 기억 장치에 있는 정보들과 결합해서 얼마나 weight parameter를 곱해서 output으로 내보낼지 결정한다.
따라서 long-range information도 잘 보존된다.
Gated Recurrent Units (GRU)
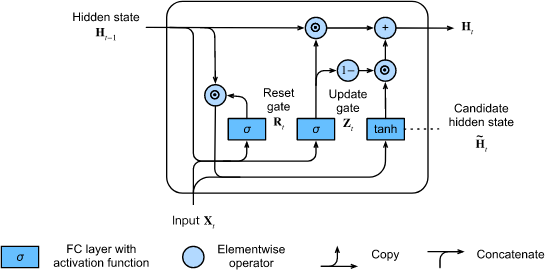
GRU는 LSTM의 변형 형태인데, LSTM의 구조가 너무 복잡하기 때문에 추가적인 cell state를 만들지 않으면서 input을 두 갈래로 나누어 한 갈래를 cell state처럼 사용하는 구조이다.
References
https://d2l.ai/chapter_recurrent-modern/lstm.html
https://codingnomads.com/create-gated-recurrent-unit-from-scratch#summary-create-a-grated-recurrent-unit-from-scratch
