Segmentation
segmentation이란, 이미지 속 각 픽셀이 어떤 객체에 속하는지 구분해주는 작업이다. segmentation은 크게 semantic segmentation, instance segmentation, panoptic segmentation의 3가지로 구분할 수 있다.
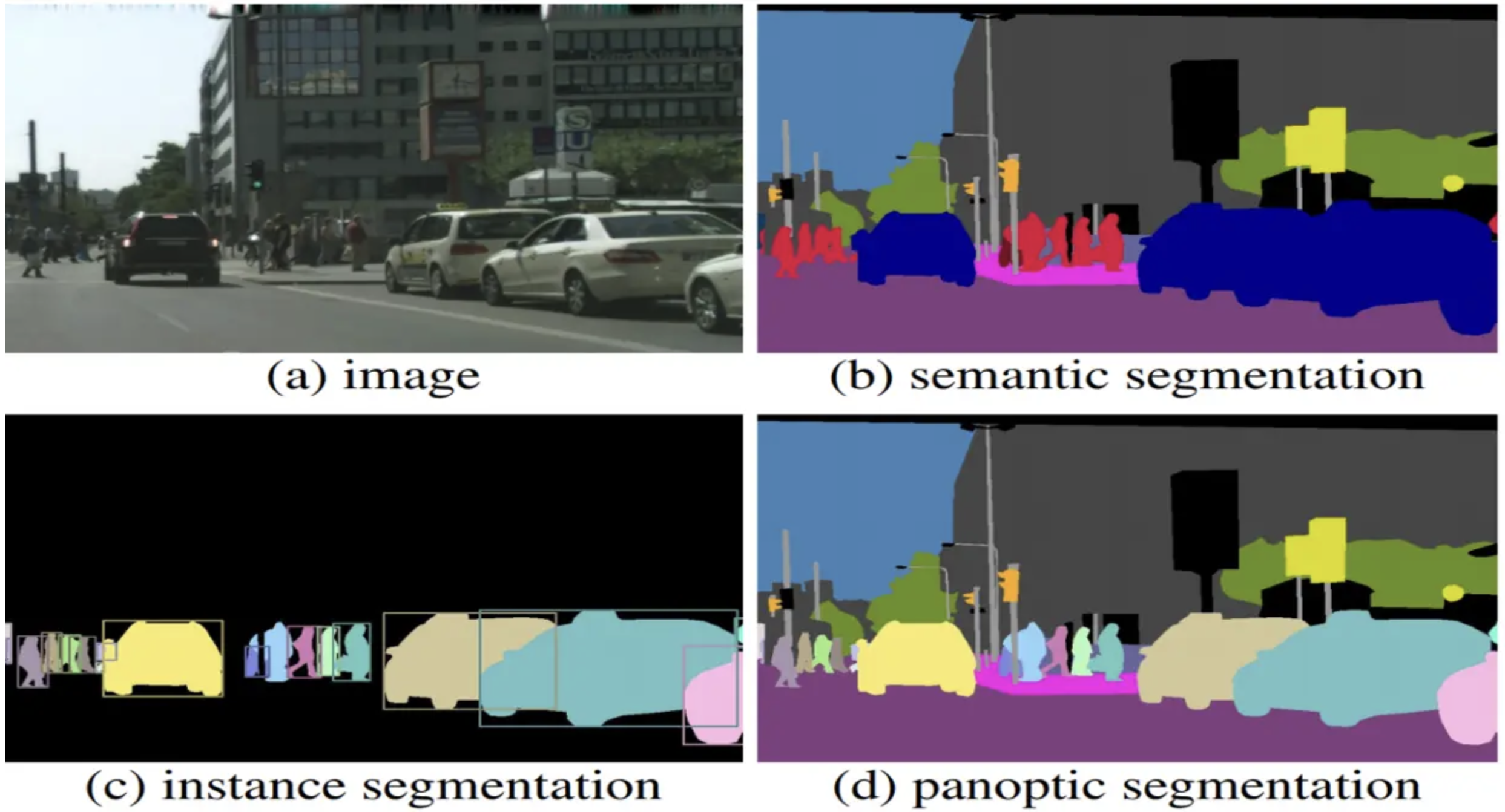
- semantic segmentation : 각 픽셀을 객체의 종류로 구분
- instance segmentation : 각 픽셀을 객체의 종류 뿐만 아니라 인스턴스까지 구분. 즉, 여러 대의 자동차가 있다면 각 자동차를 구분하여 개별 인스턴스로 인식한다.
- panoptica segmentation = semantic segmentation + instance segmentation. 배경은 semantic segmentation으로, 객체는 instance segmentation으로.
Fully Convolutional Networks (FCN)
참고 문헌 : Fully Convolutional Networks for Semantic Segmentation
핵심 요약
- Backbone = VGGNet
- VGG Network의 FC layer를 convolution으로 대체
- transposed convolution을 이용해 pixel-wise prediction 수행
VGGNet
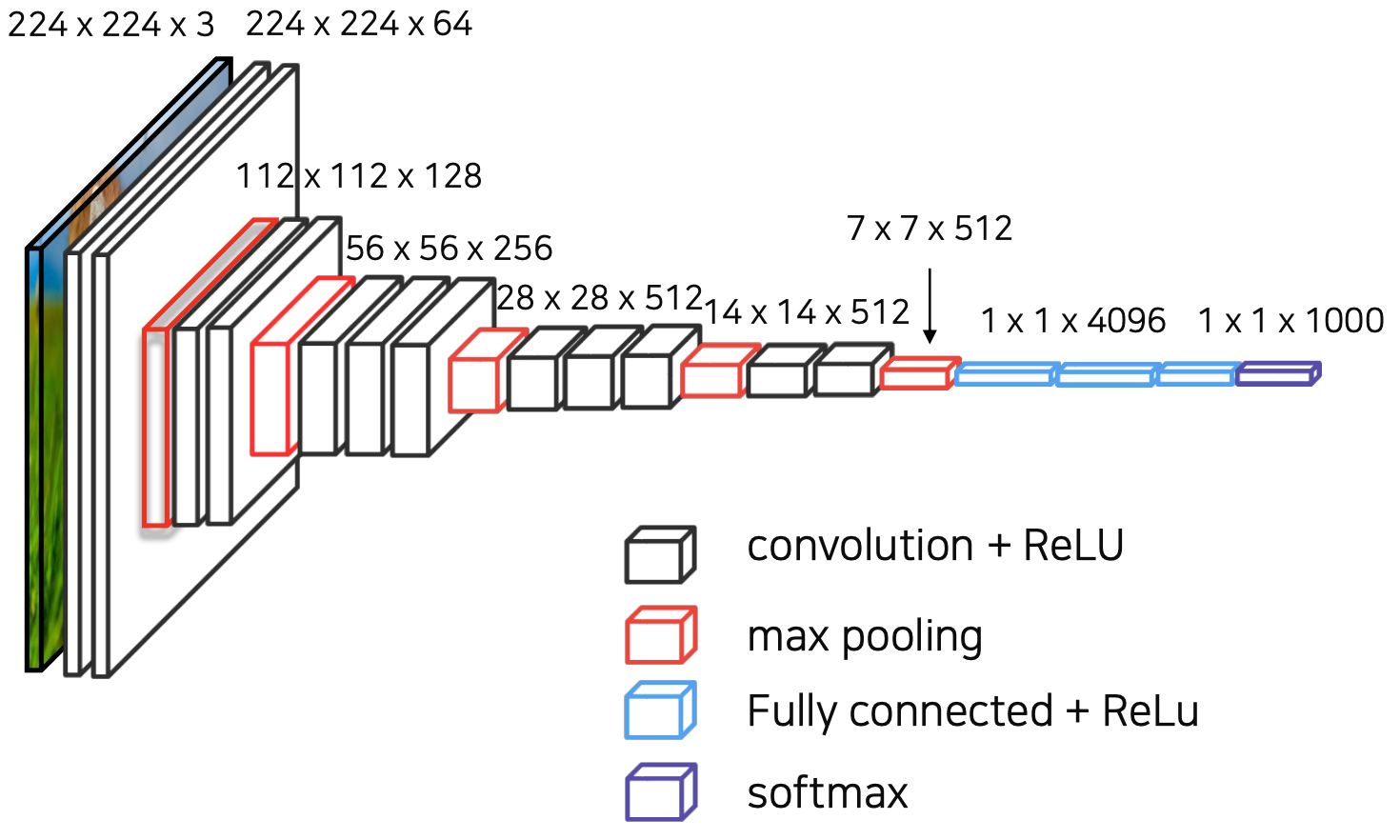
FCN은 VGGNet을 backbone으로 이용해 이미지의 feature extraction을 수행했다.
그러나 기존의 VGGNet의 Fully-Connected layer를 convolution layer로 대체했는데, 이는 픽셀의 위치 정보를 해치지 않은 채로 특징을 추출할 수 있게 해준다.
특히 1 1 convolution을 사용할 경우, 임의의 이미지 크기에서도 상관없이 잘 작동한다. (단 kernel parameter의 영향을 받음)
nn.Conv2d(input_chanel, output_channel, kernel size, ...) → 이미지 가로, 세로 크기에 상관 X
nn.Linear(input_channel*height*width, output_size) → 이미지 가로, 세로 크기에 상관 O
Transposed Convolution
위의 VGGNet 아키텍쳐를 보면, convolutional layer와 max pooling layer를 거치면서 크기가 계속 반으로 줄어드는 것을 알 수 있다. 그러나 output은 input image와 크기가 같은 segmentation map이어야 한다. 따라서 upsampling이 필요한데, upsampling을 위한 과정이 바로 transposed convolution이다.
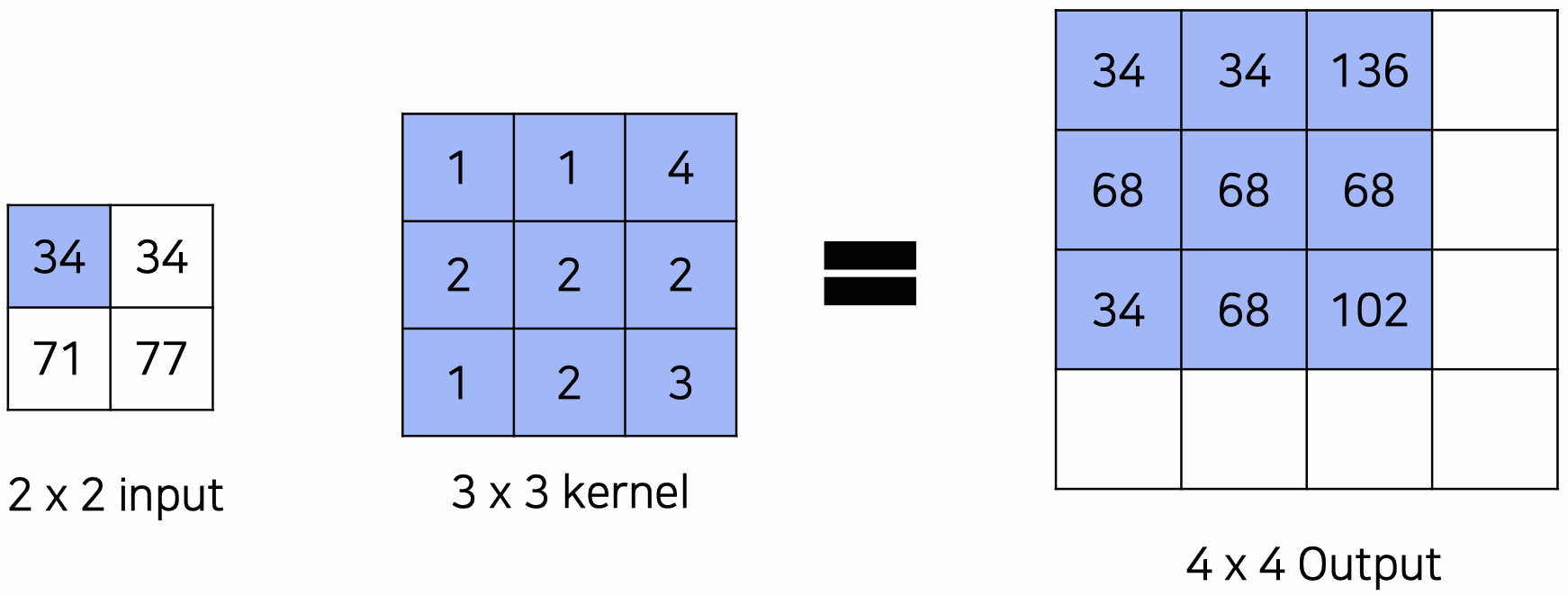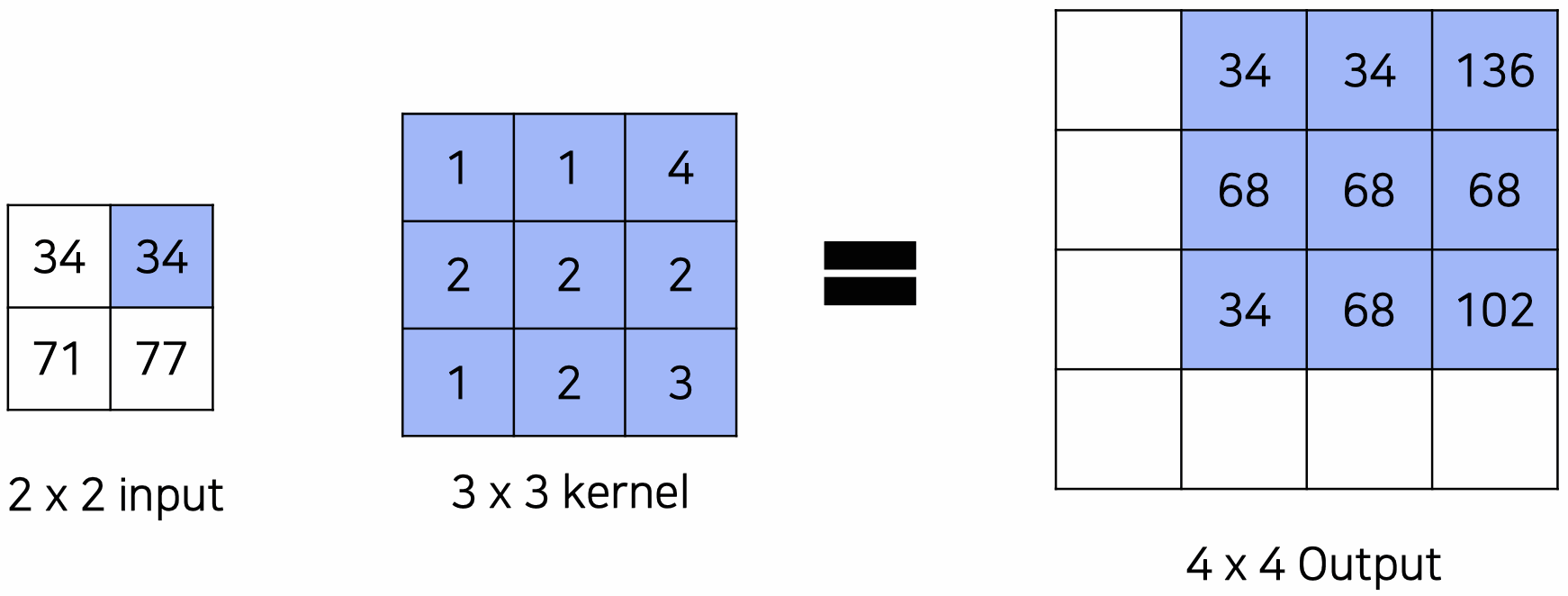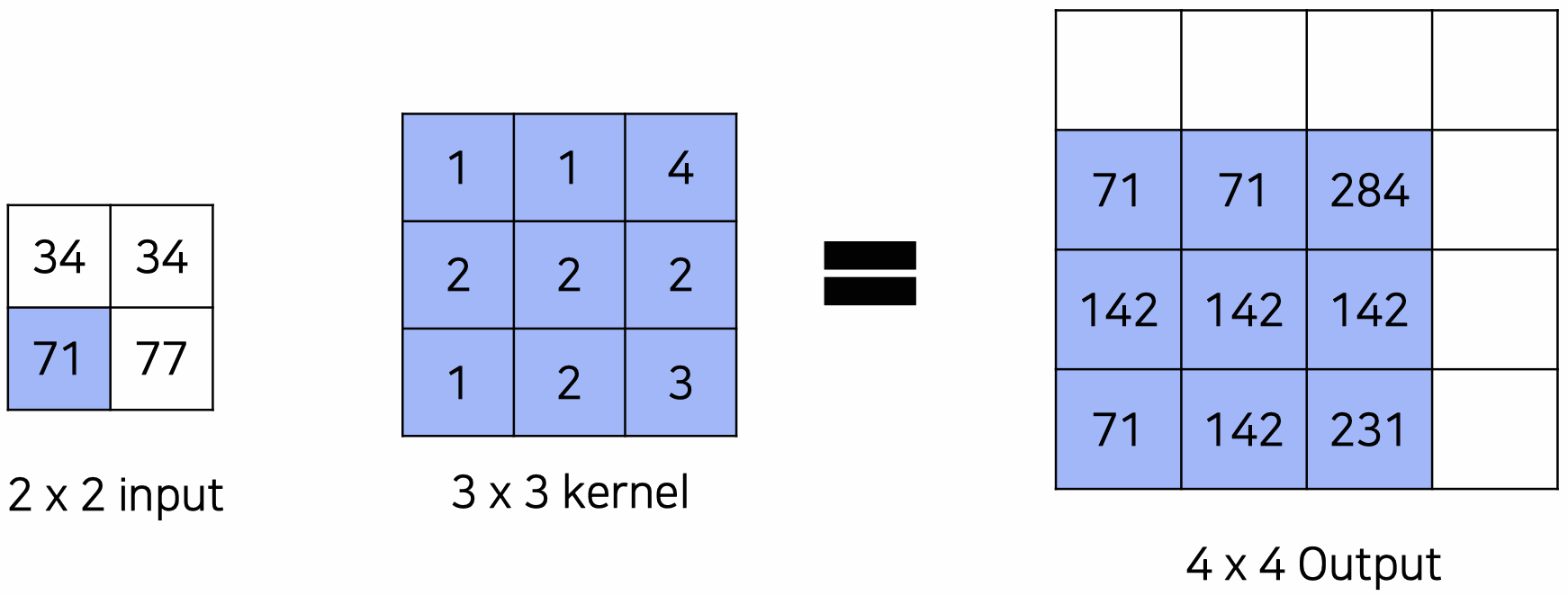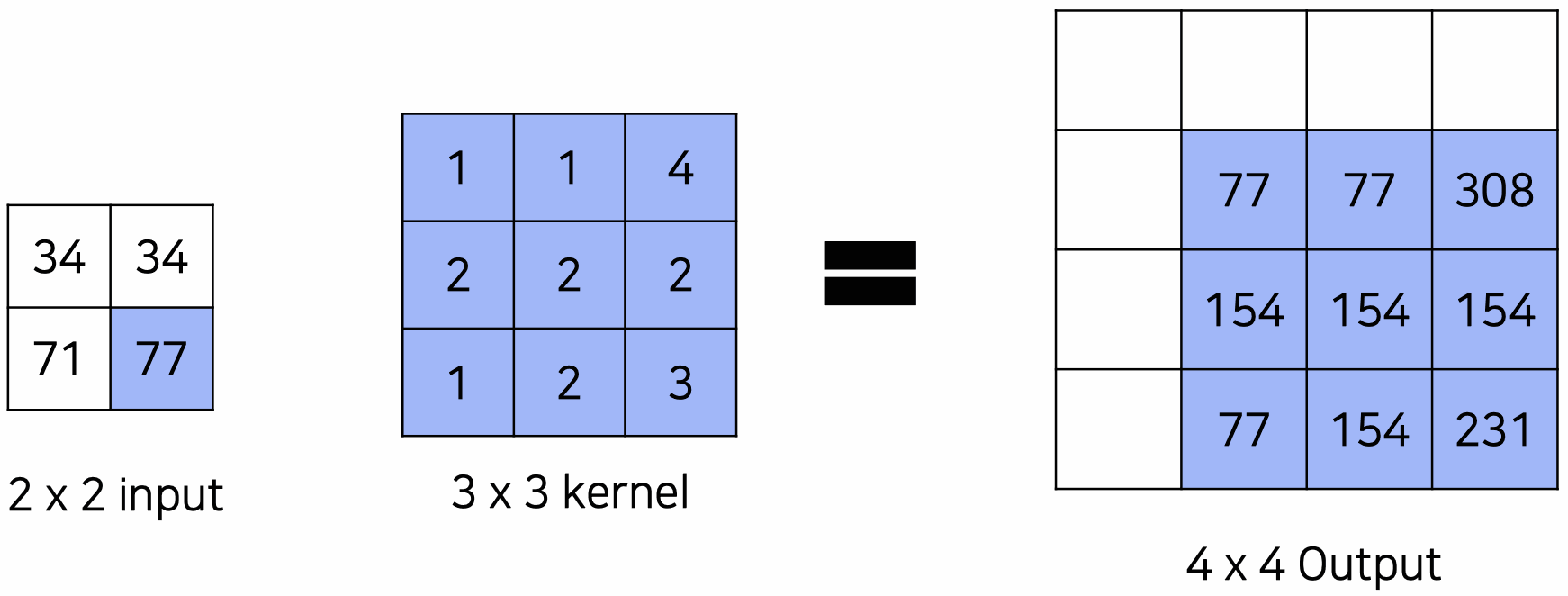
위와 같이 input image에 kernel을 convolution 연산해서 upsampling을 하는 것이 transposed convolution이다. 3 3 커널의 경우 4번의 convolution 연산 값을 pixel-wise로 더해서 4 4 output을 낸다.
output =
⭐️ transposed convolution 값은 학습 가능한 파라미터이다. backpropagation 과정에서 업데이트된다.
⭐️ 이 과정은 convolution의 역연산이 아니기 때문에 deconvolution은 엄밀히 따지면 틀린 용어이지만, 자주 transposed convolution = deconvolution으로 지칭된다.
⭐️ input할 때의 이미지와 upsampling을 통해 나온 output image의 결과는 같지 않다!!!
(1.4 FCN에서 성능을 향상시키기 위한 방법 p.64부터 다시 보충)
FCN의 성능을 향상시키기 위한 방법

위는 FCN의 architecture를 나타내는 그림이다. (원래 논문에서는 FC6에서 7 7 convolutional layer를 사용하지만 여기에는 복잡한 이슈가 있기 때문에 편의상 여기서는 1 1 convolutional layer의 경우로 두고 보겠다.) 5번의 max pooling을 거치면서 input 이미지의 크기는 = 로 줄어들게 된다. 그리고 deconvolution을 통해 upsampling을 하는데, 32배를 한꺼번에 키우는 과정에서 디테일한 feature가 소실되는 문제점이 생긴다.
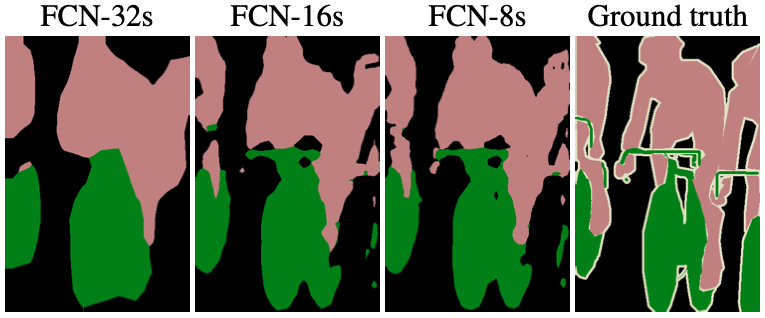
위의 그림 중 FCN-32s가 그 경우에 해당한다. (s는 stride를 의미)
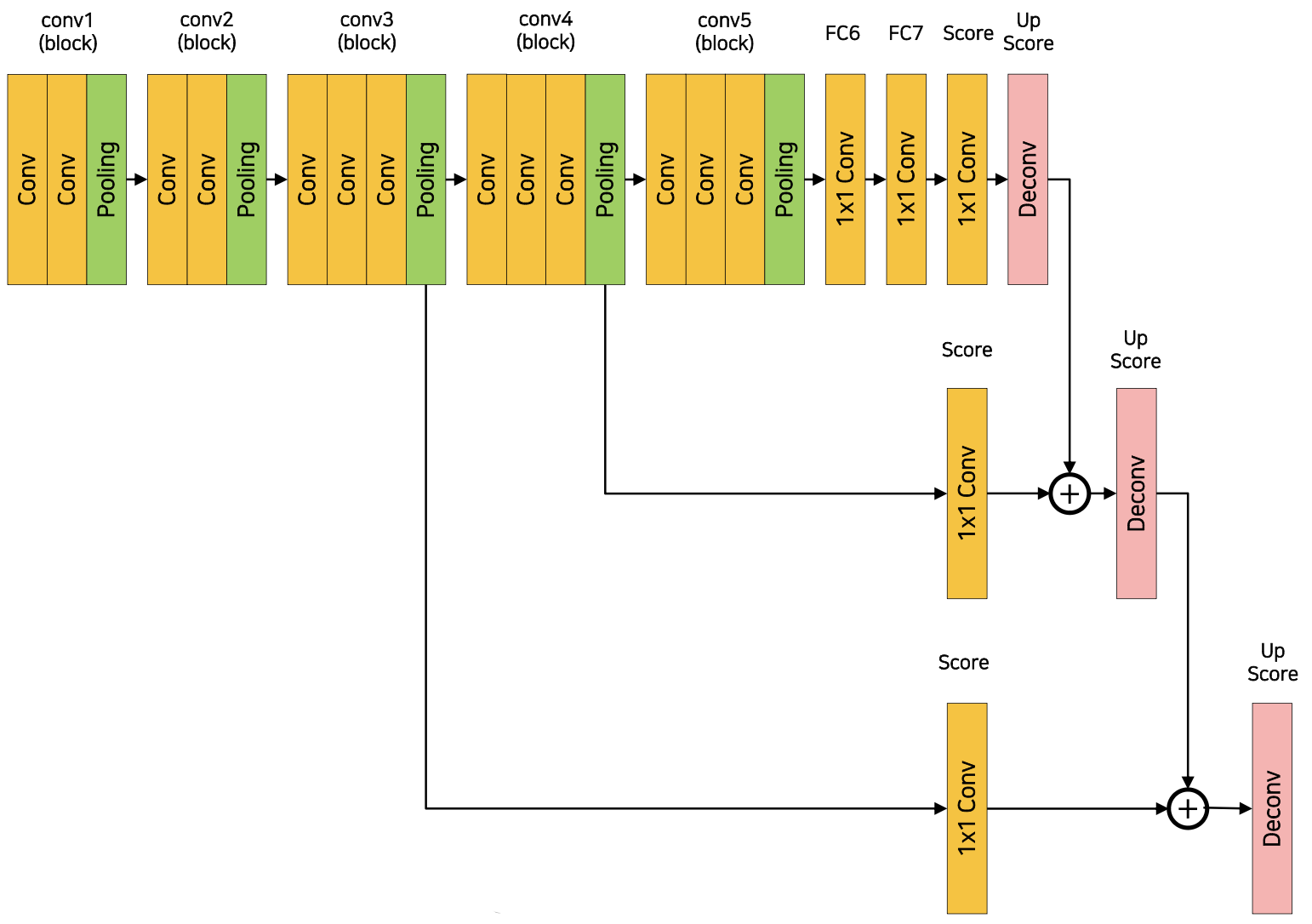
이렇게 소실된 디테일한 정보를 복원하기 위해서, skip connection 방식을 이용한다. 4번째 max pooling 결과와 2배 upsampling 결과를 더하고, (→ FCN-16s), 거기에 3번째 max pooling 결과와 4배 upsampling 결과를 더하여 (→ FCN-8s) 디테일한 feature를 살린 segmentation 작업이 가능해진다. 그 결과는 위의 FCN-32s, FCN-16s, FCN-8s, ground truth segmentation을 비교하는 그림에서 확인할 수 있다.
7 7 conv issue
아까 언급했듯 논문에서는 FCN의 architecture는 FC6에서 7 7 convolutional layer를 사용한다고 했는데, 이렇게 되면 input 이미지와 output 이미지의 resolution이 달라지는 문제가 생긴다. 이를 위해 zero padding, crop 등의 여러 테크닉을 이용하는데 너무 복잡하므로 이 정도로만 정리해두겠다.
한계점
- 큰 객체의 경우 local 정보로 예측
- 같은 객체여도 다르게 labeling
- 작은 객체 무시
- 객체의 디테일한 feature가 사라짐 ( deconvolution 절차가 간단해서 경계를 학습하기 어렵기 때문)
References
https://www.labellerr.com/blog/semantic-vs-instance-vs-panoptic-which-image-segmentation-technique-to-choose/ (segmentation image credit)
https://arxiv.org/abs/1411.4038
