기존의 neural network가 input에서 output으로 가장 잘 매핑되는 weight를 찾는 것이었다면, transformer model은 input을 통해 output을 예측할 때 그 주변과의 connection을 고려하는 것이다.
기본 가정
input x가 서로 유기적으로 관련된 여러 요소들로 분할될 수 있다.
하나의 element는 sequence에 있는 다른 element들의 weighted sum이다.
main idea
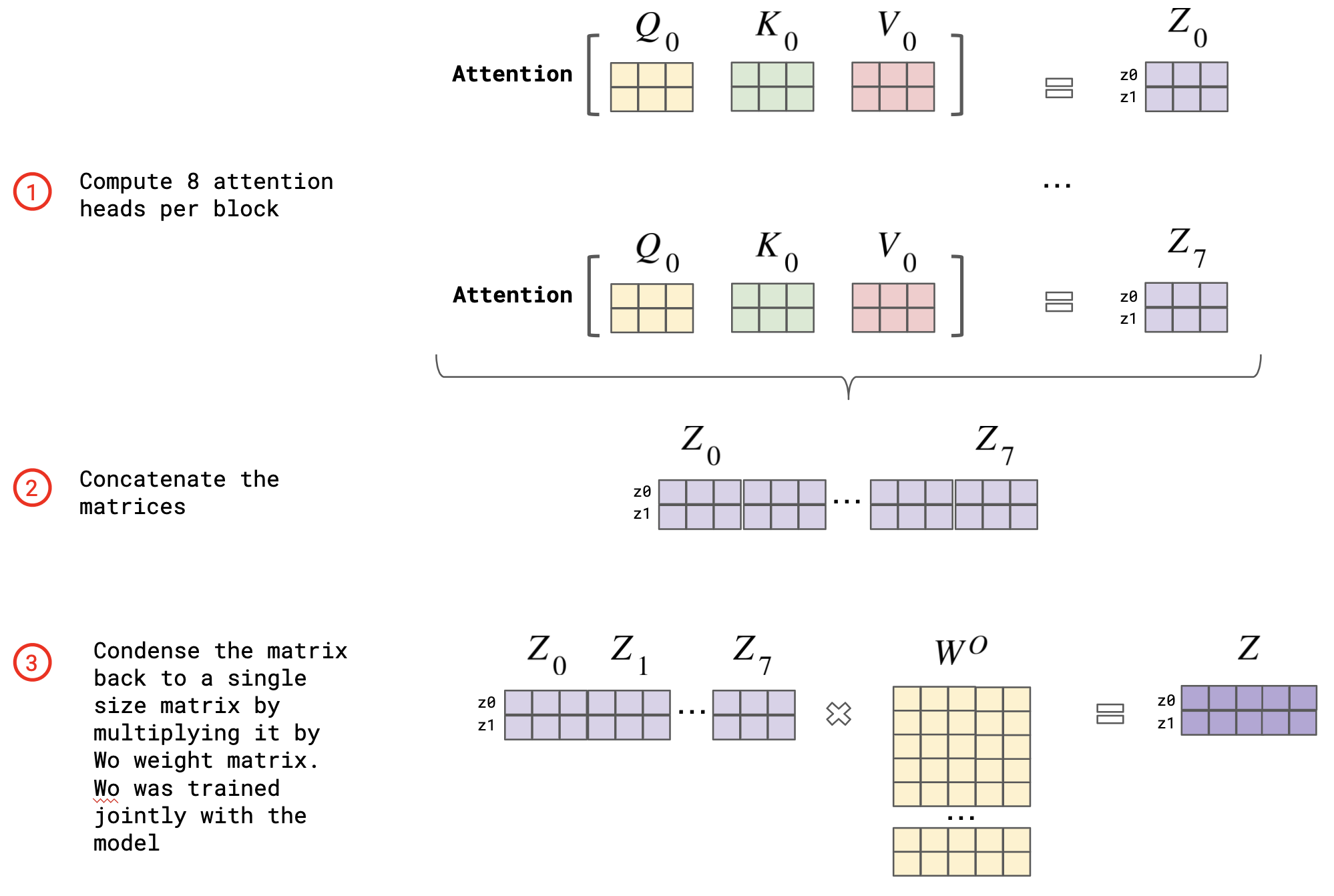
결국 transformer model은 앞에서 배운 attention model의 확장판이다. 기존의 attention model이 query, key, value를 통해 유사도를 계산해서 어떤 요소에 더 집중해야하는지 알아낸다면, transformer model은 거기에서 weight까지 추가(, , )한다. 이런 과정을 contextualize라고 한다. 여기에 attention value를 원래 공간에 다시 매핑하는 가 더 필요하다.
어떻게 regression이나 classify를 하는가
Input ~ output sequence를 예측한 다음에 그 예측값을 평균내서 (→ token aggregation) 그것을 input으로 해서 다시 classifier나 regressor를 훈련시키면 된다.
그러나 sequence 길이가 길거나 요소들이 homogeneous하지 않은 경우 평균 내는 것이 좋은 방법이 아닐 수 있다. 그럴 때에는 classification token (CLS)를 입력 sequence에 추가하여 어떤 token에도 치우치지 않고 aggregation할 수 있도록 한다.
transformer 모델의 학습 방법
기본 아이디어 : 마지막 레이어의 output embedding에 classifier 또는 regressor 배치
Encoder
Step 1. input은 token들의 sequence로 주어지고, 그들을 vector로 embedding한다.
Step 2. Multi-head attention
각 단어에 대해 linear transformation을 사용해서 Q, K, V에 매핑되는 , , 를 학습한다. 그리고 변환된 Q, K, V에 대해 attention을 한다. 이를 여러번 해서 평균을 낸다.
이렇게 여러번 해야 하는 이유는 모델이 서로 다른 subspace에 있는 representation을 추출할 수 있어 성능 향상 측면에서 매우 유리하다. (ex) 번역에서 대명사가 가리키는 대상이 모호한 경우, 여러 대상에 대해 이 작업을 하면 그 대상이 명확해질 수 있다.)
그러면 여러 개의 attention value z가 나오는데 이들을 다 concatenate해서 linear transformation을 한다.
Step 3. Feed-forward layer
Feed-forward layer를 추가해서 contextualized embedding에 추가적인 learning operation을 해서, 더 representation을 잘 배우게 한다. 이것이 여러번 반복된다. (N self-attention blocks)
Step 4. Positional encoding
RNN과 달리 transformer model에서는 token에 순서가 없기 때문에, order information을 넣기 위해 positional encoding을 한다.
Decoder
Step 5. Encoder의 출력 z에서 output sequence를 auto-regressive하게 생성한다. (다음 symbol을 생성할 때 이전에 생성된 symbol을 추가 입력으로 사용한다.)
Step 6. 현재 시간 단계 이후의 정보는 알 수 없으므로 마스킹처리되고, 이 마스킹을 제외하고 step 2와 동일한 작용을 한다. 즉, 입력된 토큰이 contextualzie되어 변형된다.
Step 7. Encoder-decoder attention
Key, value는 encoder에서 나온 값이고, q는 decoder로부터 나온다. 그리고 multi-head self attention 작업이 이루어진다. Encoder에 있는 단어와 decoder에 있는 번역하고자 하는 단어들의 유사도를 예측해서 encoder 단어 중에 어떤 것에 집중해서 번역을 할지 결정한다.
Step 8. Feed-forward layer
encoder와 동일
Step 9. Linear layer
Output embedding을 class score로 매핑 → 원하는 output 형태로 만들어준다.
Step 10. Softmax layer
Class socre에 softmax를 취해서 확률로 변환한다.
이 decoding 단계는 다음 단어가 EOS (End of Sentence)로 예측될 때까지 반복된다.
Bidirectional Encoder Representations from Transformers (BERT)
transformer를 훈련시키는 테크닉에 대한 논문이다.
Transformer encoder를 사용한 대규모 word embedding pre-training이고, Self-supervised
Input sequence는 token embedding, segmentation embedding, positoin embedding을 합친 두 문장으로 구성된다.
token embedding은 pre-trained word로, 문장의 시작 부분에 위치하는 CLS(분류 토큰)과 문장의 끝을 표시하는 SEP(구분 토큰)이 있다.
segment embedding은 각 토큰이 속한 문장을 나타내는 학습된 embedding이다.
positional embedding은 시퀀스의 각 위치를 위한 학습된 embdding이다.
이 input sequence를 이용해 두 가지 과제로 훈련시켰다.
- Masked Language Modeling : 임의로 15%의 토큰을 마스킹하여, 문맥을 사용해 숨겨진 단어를 추측하도록 훈련
- Next Sentence Prediction : 입력된 두 문장이 연속적인지 아닌치 예측하도록 훈련
추후 연구를 통해 Masked Language Modeling 과제가 Next Sentence Prediction보다 훨씬 중요하는 것이 밝혀졌다.
Vision Transformer (ViT)
transformer model을 이미지 데이터에 적용한 것이 ViT이다.
이미지를 n x n 패치로 분할하여, 이 패치들의 linear embedding sequence를 transformer에 입력한다. 이 이미지 패치들은 단어 token과 동일한 방식으로 처리된다. 최종적으로, 이미지를 분류하는 작업을 한다면 CLS 토큰 위에 MLP가 추가된다.
Referneces
