머신 러닝의 다양한 기법에 대해 알아보겠다.
K-Nearest Neighbor (KNN)
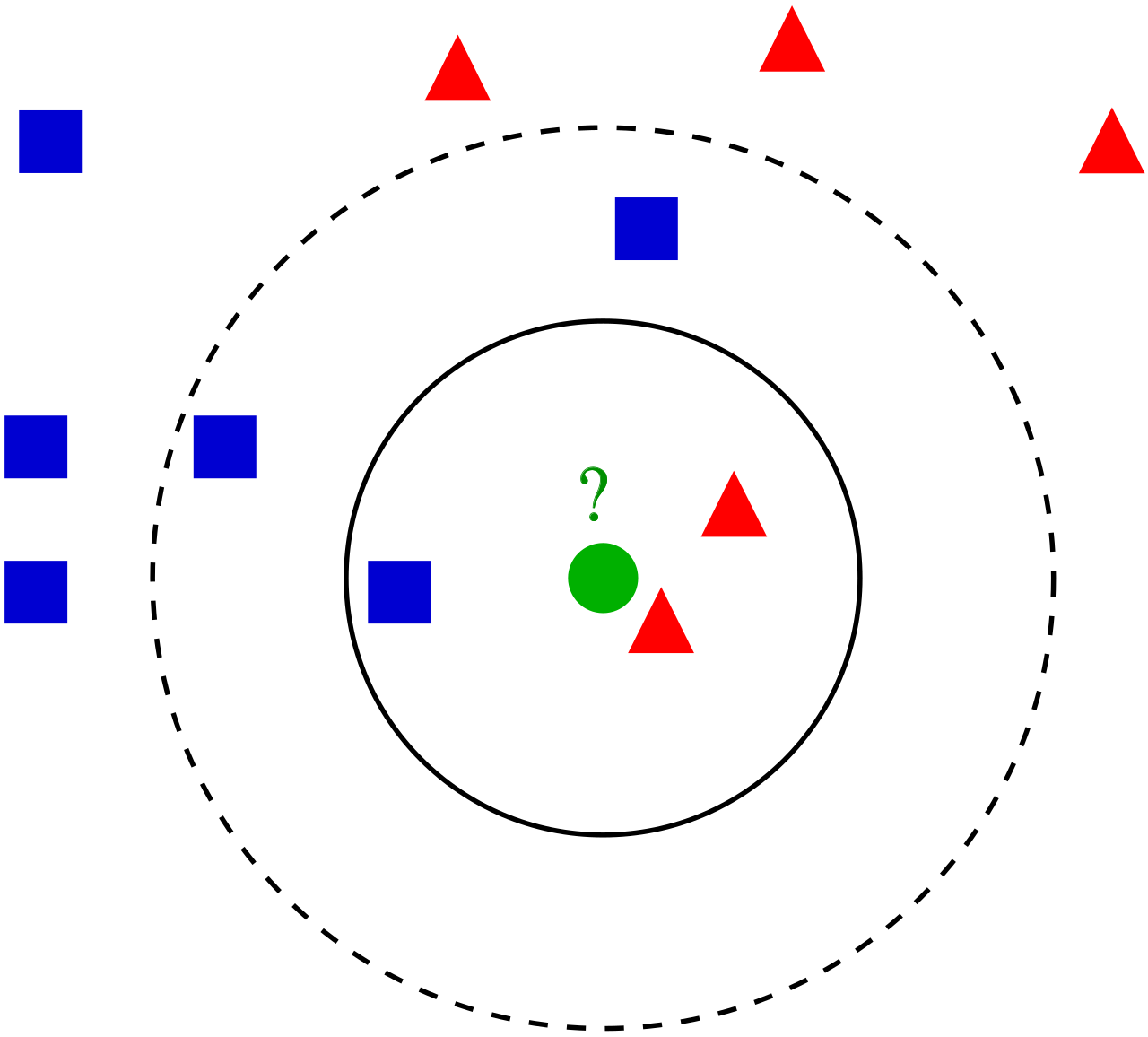
- 2차원 평면 위에 두 그룹(빨간 삼각형, 파란 사각형)의 특성을 나타냈더니 위 그림과 같은 분포가 나타났다. 그리고 이제 test set (초록 원)의 위치를 같은 평면에 나타내고 test set이 어느 그룹에 속하는지 판단하려고 한다. 이 때 test set을 중심으로 k라는 반경을 설정하여, 반경 k 내에 들어오는 데이터들 중 어느 그룹에 속한 것이 더 많은지를 판단하여 test set을 분류하는 알고리즘이다.
- 위 그림의 예에서 보면 k를 작게 설정하여 실선으로 그려진 원에서 판단하면 test set을 빨간 삼각형 그룹으로 분류할 수 있을 것이고, k를 크게 설정하여 점선으로 그려진 원에서 판단하면 test set을 파란 사각형 그룹으로 분류할 수 있을 것이다.
- 이와 같이 KNN은 적절한 k를 설정하는 것이 중요한데 적절한 k를 설정하는 것이 어렵고, 데이터가 많아지면 예측 시간이 비교적 오래 걸리게 된다.
- KNN은 기본적으로 분류하는데 쓰이지만 군집화(clustering)에서 더 많이 쓰이는 알고리즘이다.
- scikit-learn에 구현된 KNN model
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=10) # k=10인 경우의 KNN model로지스틱 회귀 (Logistic regression)
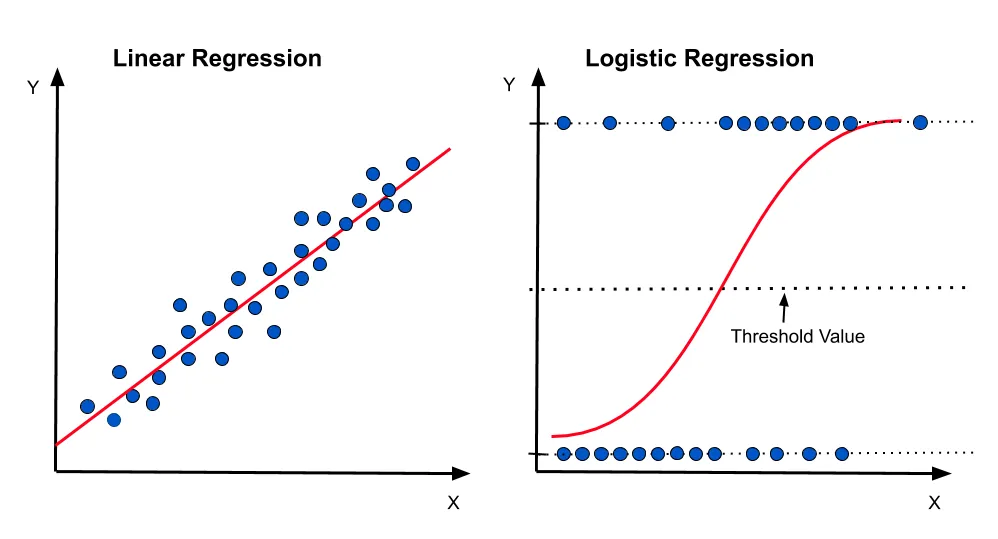
- 2차원 평면 위에 데이터들의 분포를 나타냈을 때, 서로 다른 두 그룹을 분류할 수 있는 경계선(함수)을 찾는 것이 regression이다. 이 경계선이 직선일 경우 linear regression이고, sigmoid function을 이용할 경우 logistic regression이다.
- 분류 예측 결과를 0과 1 사이의 값으로 조정하여 반환하며, 0에 가까울수록 그룹 1, 1에 가까울수록 그룹 2와 같이 분류된다고 할 수 있다.
- scikit-learn에 구현된 logistic regression
from sklearn.linear_model import LogisticRegression
logreg_model = LogisticRegression()Support Vector Machine (SVM)
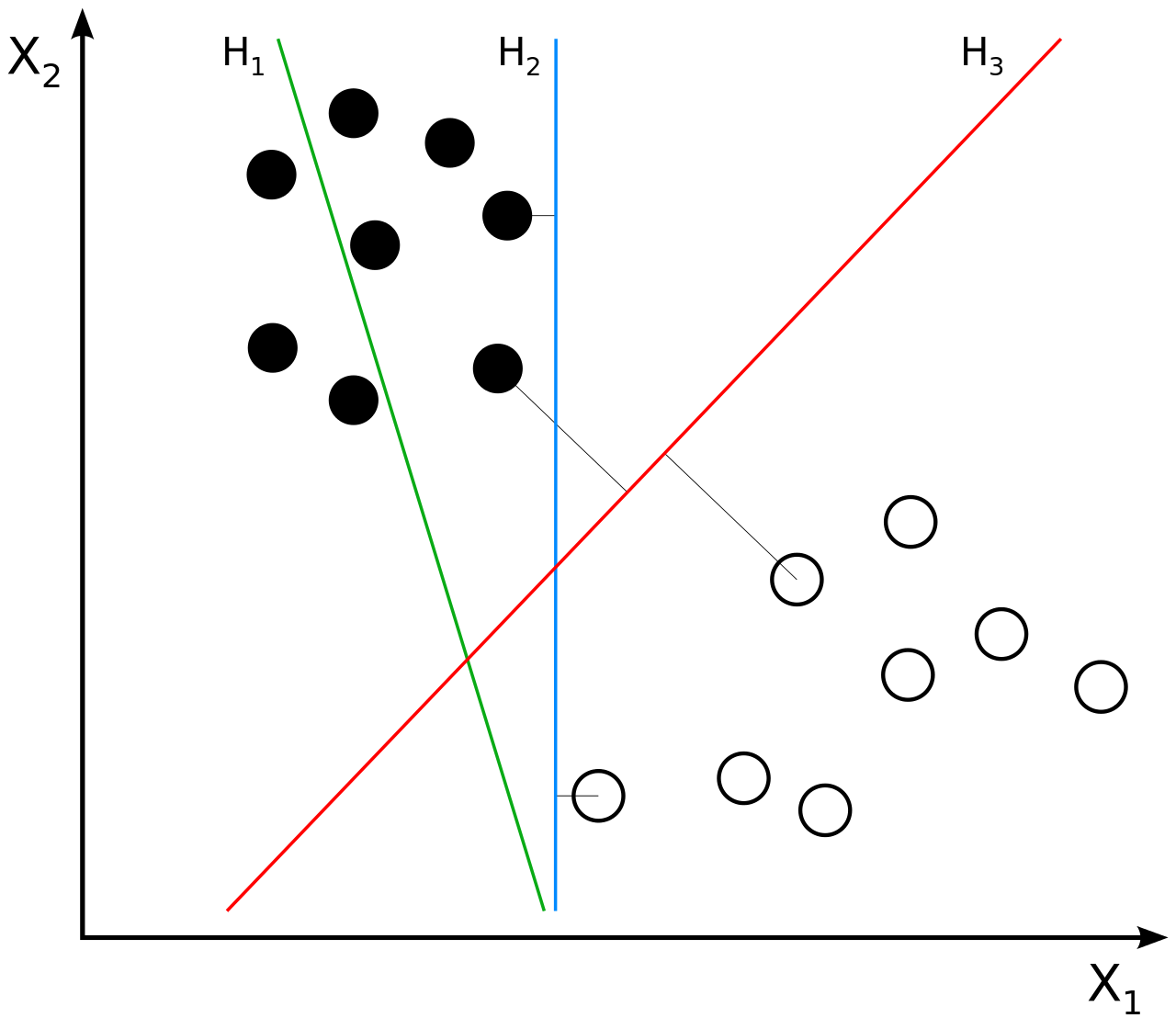
- SVM은 regression과 유사하게 2차원 평면 상에 데이터 분포를 나타냈을 때 서로 다른 두 그룹을 분류하는 경계선을 찾는 것이다. 여기서 경계선과 가장 가까운 데이터를 support vector라고 하고, support vector와 경계선까지의 거리를 margin이라고 한다. 이 때 margin을 가장 크게 할 수 있는 경계선을 찾는 것이 SVM의 알고리즘이다.
- 위 그림의 예에서 보면, 초록색 직선은 검은 원과 흰 원 그룹을 제대로 분류하지 못하고 있다. 파란색 직선은 검은 원과 흰 원을 분류하기는 했지만, margin이 작다. 빨간색 직선은 검은 원과 흰 원을 분류하면서 margin이 가장 큰 경우이다. SVM은 이와 같이 빨간색 직선을 찾아내어 데이터를 분류하는 알고리즘이다.
- scikit-learn에 구현된 SVM
from sklearn.svm import SVC
svc_model = SVC()Decision tree learning

관측값과 목표값을 decision tree를 이용해서 연결시키는 예측 모델이다. 위의 그림은 titanic 문제를 decision tree를 이용하여 각 feature와 생존 여부 예측을 연결시킨 것이다.
decision tree 역시 scikit-learn으로 구현되어 있다.
from sklearn.tree import DecisionTreeClassifier
decision_model = DecisionTreeClassifier()Ensemble
여러 개의 간단한 모델을 생성한 후 그 모델들의 예측값을 종합하여 하나의 최종 모델 또는 예측값을 도출하는 기법이다. Ensemble 기법은 내용이 많으므로 별개의 포스팅에서 따로 다루도록 한다. (→ https://velog.io/@kupulau/Ensemble)
Naive Bayes
feature들이 독립적이라고 가정하여 각 feature에 대해 확률 계산을 한 후 이를 학습시켜 예측을 하는 기법이다. 독립적이라고 임의로 가정했기 때문에 예측 성능에 한계가 있을 수 있다. scikit-learn의 GaussianNB, BernoulliNB, MultinomialNB 등으로 구현할 수 있다. 보통 GaussianNB는 연속적인 데이터를 다룰 때 (웬만한 데이터는 거의 다 다룰 수 있다), BernoulliNB는 텍스트 데이터 또는 이진 데이터, MultinominalNB는 텍스트 데이터를 다룰 때 많이 사용한다. 자세한 것은 나이브 베이즈 포스팅 참조 (→ https://velog.io/@kupulau/%EB%82%98%EC%9D%B4%EB%B8%8C-%EB%B2%A0%EC%9D%B4%EC%A6%88-%EB%B6%84%EB%A5%98)
scikit-learn에서 GaussianNB 구현된 것을 사용할 수 있다.
from sklearn.naive_bayes import GaussianNB
nb_model = GaussianNB()References
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
https://ai.plainenglish.io/why-is-logistic-regression-called-regression-if-it-is-a-classification-algorithm-9c2a166e7b74 (regression image credit)
https://en.wikipedia.org/wiki/Support_vector_machine
https://en.wikipedia.org/wiki/Decision_tree_learning
