머신 러닝으로 데이터 분류를 했을 때, 분류가 정확히 이루어졌는지 판단할 수 있는 성능 평가 지표들 중에는 정밀도(Precision)와 민감도(Sensitivity)가 있다.
이들에 대해 이해하기 위해서는 우선 Type I error와 Type II error을 알아야 한다.
Type I and Type II errors
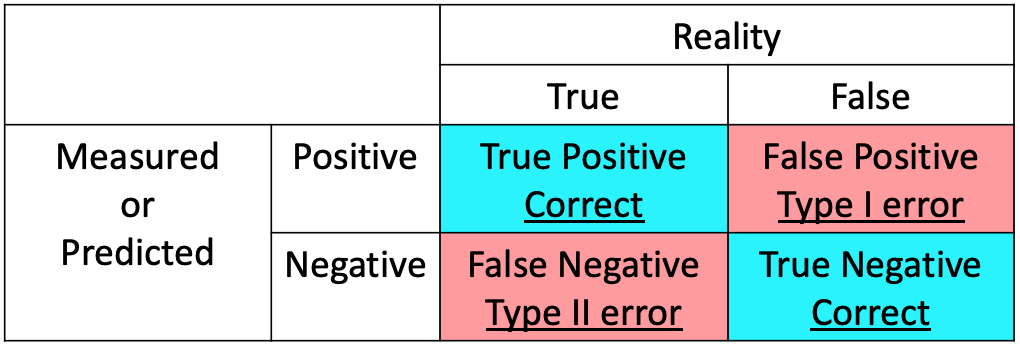
Type I error, Type II error는 통계학에서 가설 검증을 할 때 나오는 개념이다.
위의 표에 직관적으로 정리가 되어있는데, Reality는 현실에서 참인지 거짓인지 여부이고, Measured or Predicted는 측정 혹은 예측을 했을 때 참으로 판정되는지 거짓으로 판정되는지를 보는 것이다.
- True Positive (TP) : 현실에서 참인 일이 측정했을 때에도 참으로 나오는 경우이다. 예를 들어 코로나19 진단 키트를 생각해보자. 실제로 코로나19에 걸린 환자가 진단 키트를 사용해서 양성 판정이 나오는 경우가 이에 해당한다.
- False Positive (FP) : 현실에서는 거짓인 일이 측정했을 때에는 참으로 나오는 경우이다. 코로나19에 걸리지 않았는데도 불구하고 진단 키트에서 양성 판정이 나오는 상황이다. 즉, 이는 오류에 해당하고, 이 오류를 Type I error라고 한다.
- False Negative (FN) : 현실에서는 참인 일이 측정했을 때에 거짓으로 나오는 경우이다. 코로나19에 걸렸음에도 불구하고 진단 키트에서 음성으로 나오는 상황이다. 이것도 오류에 해당하고, Type II error라고 한다.
- True Negative (TN) : 현실에서는 거짓인 일이 측정했을 때에도 거짓으로 나오는 경우이다. 코로나19에 걸리지 않았고 진단 키트에서도 음성으로 나오는 상황이다.
** Reality에서의 True와 False는 TP, FP, FN, TN에서의 True/False와 의미가 다름에 유의한다.
경우에 따라 달라질 수 있지만, 보통은 Type II error가 Type I error보다 상대적으로 위험하게 여겨진다.
정밀도 (Precision)
정밀도는 측정 혹은 예측을 해서 참으로 판정되었을 때, 그 측정 혹은 예측이 현실과 일치하는 확률(즉 현실도 참일 확률)을 보는 것이다. 예시로 든 코로나19 진단 키트의 경우로 얘기하면, 진단 키트로 양성 판정을 받았을 때 실제로 그 환자가 코로나19에 걸려있을 확률을 의미하는 것이다.
민감도 (Sensitivity) a.k.a. True Positive Rate (TPR)
민감도는 현실에서 참일 때, 측정 혹은 예측을 해서 현실과 일치하는 확률 (즉 측정 혹은 예측에서도 참으로 나올 확률)을 보는 것이다. 코로나19 진단 키트의 예시로 보면, 실제로 코로나19에 확진된 환자가 진단 키트를 이용했을 때 양성으로 판정될 확률을 의미한다. 재현율 (Recall) 이라고도 한다.
특이도 (Specificity) a.k.a. True Negative Rate (TNR)
특이도는 현실에서 거짓일 때, 측정 혹은 예측을 해서도 거짓으로 나오는 확률이다. 코로나19 진단 키트의 예시로는, 코로나19에 확진되지 않은 환자가 진단 키트를 이용해서 음성 판정될 확률을 의미한다.
False Positive Rate (FPR)
FPR은 현실에서 거짓임에도 불구하고 측정 혹은 예측을 해서 참으로 나올 확률이다. 코로나19 진단키트 예시로는, 코로나19에 확진되지 않은 환자가 진단 키트를 이용해서 양성 판정될 확률을 의미한다.
정리
정밀도와 민감도라는 개념을 이용해서 분류기의 성능을 판단할 수 있다.
다만 어떤 지표를 이용해서 성능을 평가할 것인지는 경우에 따라 잘 판단해야 할 것이다.
References
https://en.wikipedia.org/wiki/Type_I_and_type_II_errors
https://ko.wikipedia.org/wiki/지도_학습
