Confusion matrix
confusion matrix는 분류 모델의 성능을 평가할 때 사용하는 행렬 형태의 도구이다. 모델이 예측한 결과와 실제 라벨을 비교하여 분류 성능을 직관적으로 파악할 수 있게 해준다. 자세한 것은 이 포스팅에 잘 정리되어 있다. 포스팅에서 볼 수 있듯이 confusion matrix는 TP, TN, FP, FN으로 구성되어 있다.
confusion matrix를 통해 알 수 있는 성능 지표에는 accuracy, precision, recall, F1-score 등이 있다.
- accuracy (정확도) : 전체 예측 중에서 맞춘 비율
-
precision (정밀도) : 긍정으로 예측한 것 중에서 실제로 긍정인 비율
-
recall (재현율) : 실제 긍정인 것 중에서 모델이 긍정으로 예측한 비율
-
F1-score : precision과 recall의 조화 평균
그러나 어떤 문제에 어떤 성능 지표를 사용해야 할지 헷갈릴 수 있다. 그럴 때는 문제의 정의를 다시 들여다보자. 예를 들어 도둑을 잡는 방법 시스템에서 도둑과 도둑이 아님으로 분류하는 경우를 생각해보자. 같은 방범 시스템이라도 상황에 따라 중요시하는 것이 다를 수 있다. 쓰레기 처리장에는 절도 사건이 일어나더라도 심각한 재산 피해가 없으므로, 도둑이 아닌 사람을 도둑으로 예측하는 경우가 더 치명적일 것이다. 따라서 쓰레기 처리장에서는 precision을 기준으로 시스템을 평가해야 한다.
반면에 금은방에서는, 한 번이라도 절도가 일어나면 큰 재산 피해가 일어나므로, 도둑이 아닌 사람을 도둑으로 예측하는 경우를 신경쓰기 보다는 실제로 도둑을 잡는 (예측하는) 것이 더 중요하다. 따라서 금은방에서는 recall을 기준으로 시스템을 평가하는 것이 중요하다.
하나의 성능 평가 지표를 선택할 때, 다른 것을 선택하지 않아서 생기는 비용은 당연히 있을 수 밖에 없다. 그럼에도 불구하고 비용을 최소화할 수 있는 Threshold를 적절히 선택하는 것이 중요하다.
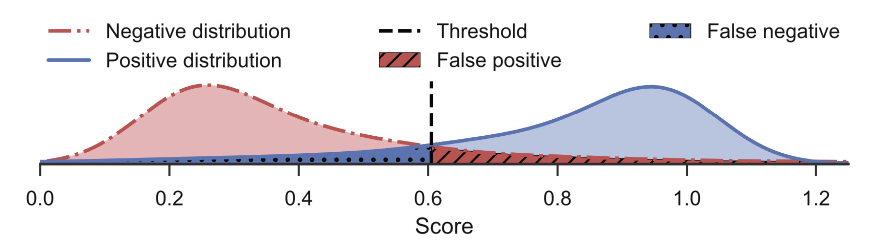
Image credit : https://link.springer.com/chapter/10.1007/978-3-030-10925-7_17
Ensemble
동일한 task의 여러 가지 모델의 결과를 혼합하여 성능을 높이는 기법을 ensemble이라고 한다.
- voting
- weighted ensemble : 성능이 좋은 모델에 더 많은 가중치를 부여해서 전체 결과를 합산할 때 성능 좋은 모델의 영향이 더 크도록 계산하는 것이다.
Cross-validation
Test-Time Augmentation
test data를 N번 augmentation 한 후 N개의 결과를 ensemble하는 것이다.
