복잡한 문제를 더 작은 하위 문제로 나누어 해결하는 알고리즘 설계 기법
Assembly-line scheduling
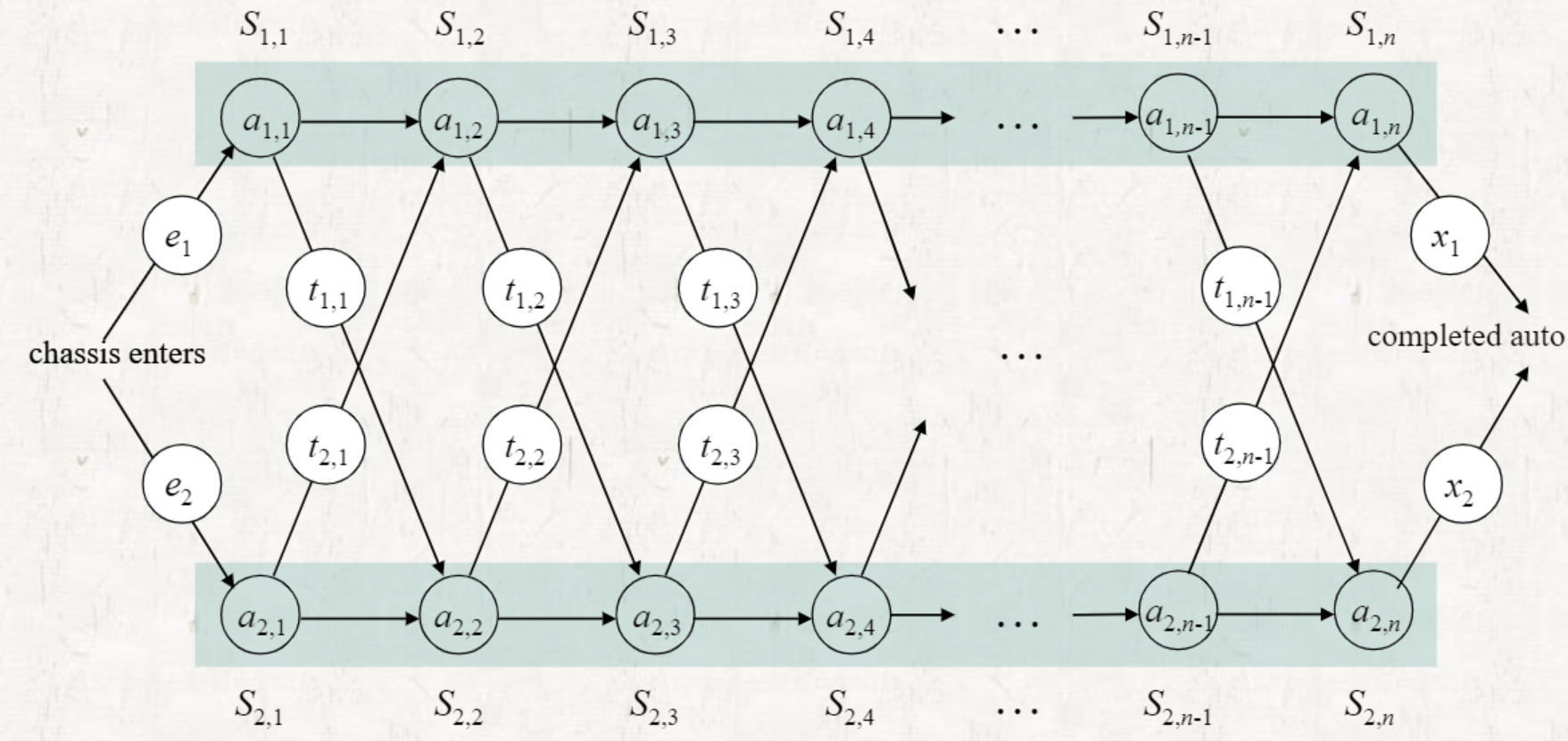 : stations, : assembly time in the ith station, Entry time: e, Exit time: x, Transfer time:
: stations, : assembly time in the ith station, Entry time: e, Exit time: x, Transfer time:
가장 빠른 assembly time을 찾자
Solving assembly-line scheduling
1. Brute-force approach
- 모든 경우의 수를 찾고 가장 빠른 경우를 선택한다.
- 각 statation마다 두 가지의 선택할 수 있기 때문에 의 가능한 경우의 수가 있다.
2. Dynamic programming
- 는 와 까지의 fastest way를 찾고 또는 를 더하고 더 작은 것을 선택해서 구한다.
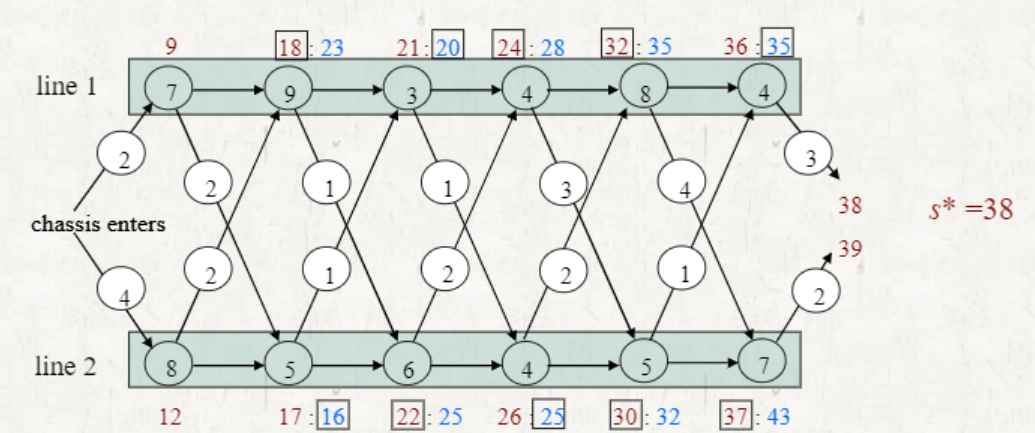 빨간색의 숫자는 line 1으로부터 온 것, 파란색의 숫자는 line 2로부터 온 것이다.
빨간색의 숫자는 line 1으로부터 온 것, 파란색의 숫자는 line 2로부터 온 것이다.
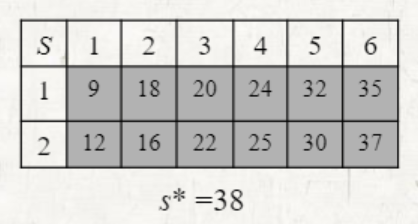 배열 S는 까지의 fastest way를 기록해놓은 것이다. (: line number, : station number)
배열 S는 까지의 fastest way를 기록해놓은 것이다. (: line number, : station number)
Back-tracking
해당 station에서 fastest way의 이전 단계가 어느 line이였는지를 알려주는 배열 L을 사용한다.
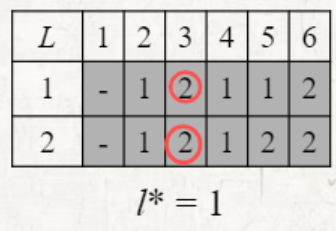 마지막 직전의 station의 line을 알려준다.
마지막 직전의 station의 line을 알려준다.
pseudocode of assembly-line scheduling
FASTEST-WAY (a, t, e, x, n)
s[1][1] = e[1] + a[1][1]
s[2][1] = e[2] + a[2][1]
for j= 2 to n
if s[1][j−1] ≤ s[2][j−1] + t[2][j−1]
s[1][j] = s[1][j−1] + a[1][j]
l[1][j] = 1
else
s[1][j] = s[2][j−1] +t[2][j−1] + a[1][j]
l[1][j] = 2
if s[2][j−1] ≤ s[1][j−1] + t[1][j−1]
s[2][j] = s[2][j−1] + a[2][j]
l[2][j] = 2
else s[2][j] = s[1][j−1] + t[1][j−1] + a[2][j]13l[2][j] = 1
if s[1][n] + x[1] ≤ s[2][n] + x[2]
s* = s[1][n] + x[1]
l* = 1
else s* = s[2][n] + x[2]
l* = 2a[i][j]: time for
t[i][j]: transfer time from or
e[i]: entry time
x[i]: exit time
PRINT-STATIONS (l, l*, n)
i = l*
print "line " i", station" n
for j = n downto 2
i = l[i][j]
print "line " i", station" j − 1Running time:
Space consumption of Assembly-line scheduling using dynaic programming
- Table s: 2n
- Table l: 2n
- elements in total
Running time of Assembly-line scheduling using dynaic programming
- 각 element를 계산하는 것:
- time in total
- =
만약 다른 정보없이 fastest time 만 구한다면?
-
space consumption
- Table 은 필요없다.
- Table 는 4개의 element만 저장하면 된다.
- S[1][j]와 S[2][j] 계산 시, S[1][j-1]와 S[1][j-1] 값만 이용하면 되고, S[1][j]와 S[2][j]를 저장할 공간만 있으면 된다.
- 따라서 이다.
Rod cutting
n 길이의 Rod(막대)가 주어졌을 때, 가장 이익이 많이 남도록 막대를 나누는 방법을 구하는 문제
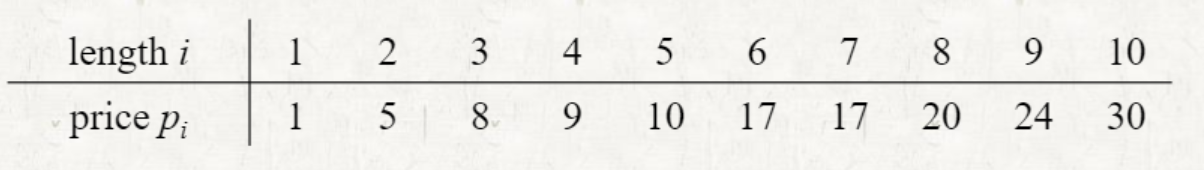 를 i 길이일 때, 최대 이익이라고 할 때, 를 이용하면 각 길이에 대한 를 구할 수 있다.
를 i 길이일 때, 최대 이익이라고 할 때, 를 이용하면 각 길이에 대한 를 구할 수 있다.
back-tracking
두 조각으로 나눌 때, 사용한 i를 저장할 배열 S를 이용하여 구현할 수 있다.
pseudocode of Rod cutting
EXTENDED-BOTTOM-UP-CUT-ROD (p, n)
let r[0 .. n] and s[0 .. n] be new arrays
r[0] = 0
for j = 1 to n
q= −∞
for i = 1 to j
if q < p[i] + r[j − i]
q = p[i] + r[j − i]
s[j] = i
r[j] = q
return r and sr[i] = i 길이의 최대 이익
s[i] = i 길이에서, 세분화한 부분의 길이
PRINT-CUT-ROD-SOLUTION(p, n)
(r, s) = EXTENDED-BOTTOM-UP-CUT-ROD (p, n)
while n > 0
print s[n]
n = n – s[n]space consumption of Rod cutting
running time of Rod cutting
- 1 + 2 + 3 + ... + n =
Assembly-line scheduling 과 같이 space consumption을 줄이는 것이 가능한가?
- Assembly-line scheduling 과 다르게 기존 계산 결과를 모두 이용해야하기 때문에 불가능하다.
Longest common subsequence
두 문자열아 주어졌을 때, 가장 긴 common subseqeunce를 구하는 문제
Definition
- Character: 문자
- String / Seqeunce: 문자의 집합
- Substring: 부분 문자열
- 모든 문자는 연결되있어야한다.
- Subsequence
- 순서만 보존되면 된다.
- BCDB is a subsequence of ABCBDAB
- Common Subsequence
- BCA is a common subsequence of X = ABCBDAB and Y = BDCABA
- The ith prefix of X
- =
- = Null string
Solving Longest common subseqeunce
1. Brute force approach
- X와 Y의 모든 subsequence를 구하고 일치하는 것 중 가장 긴 것을 고르는 방법
- X의 길이를 n, Y의 길이를 m 이라고 하면 의 subsequence가 존재하기 때문에 실행불가능하다.
- 하나의 문자가 선택되거나 선택되지 않는 두 가지 경우가 있기 때문에 개의 subseqeunce가 생긴다.
2. Dynamic programming
X의 길이를 m, Y의 길이를 n이라고 할 때, 는 X, Y의 한 문자라고 하자
- 이라면, 이고, 은 과 의 LCS이다.
- 이라면, 또는 이다.
 c[i][j]: sequences 와 에서의 LCS의 길이
c[i][j]: sequences 와 에서의 LCS의 길이
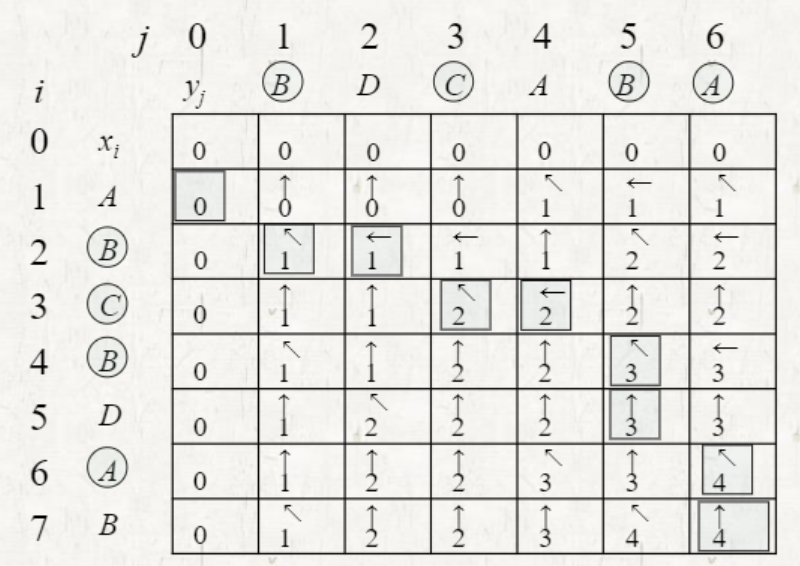 화살표는 Back tracking을 위해 사용한다.
화살표는 Back tracking을 위해 사용한다.
(i, j) 입장에서는 (i-1, j-1), (i-1, j), (i, j-1) 3개의 경우만 고려하면 된다.
pseudocode of longest common subsequence
LCS-LENGTH (X, Y)
m= X.length
n= Y.length
let b[1 .. m][1 .. n] and c[0 .. m][0 .. n] be new tables
for i = 1 to m
c[i][0] = 0
for j= 0 to n
c[0][j] = 0
for i = 1 to m
for j = 1 to n
if x_i == y_j
c[i][j] = c[i−1][j−1] +1
b[i][j] = "↖"
else if
c[i−1][j] ≥ c[i][j−1]
c[i][j] = c[i−1][j]
b[i][j] = "↑"
else
c[i][j] = c[i][j−1]
b[i][j] = "←"
return c and bb[i][j]: Back-tracking을 위한 화살표를 저장하기 위한 배열
c[i][j]: 와 의 Longest common subsequence의 길이를 저장하는 배열
PRINT-LCS (b, X, i,j)
if i==0 or j==0
return
if b[i][j] =="↖"
PRINT-LCS (b, X, i−1, j−1)
print x_i
else if b[i][j] =="↑"
PRINT-LCS (b, X, i−1, j)
else
PRINT-LCS (b, X, i, j−1)화살표가 "↖"인 지점을 잘 살펴야한다.
Multiple LCSs
2개 이상의 LCS가 존재하는 경우
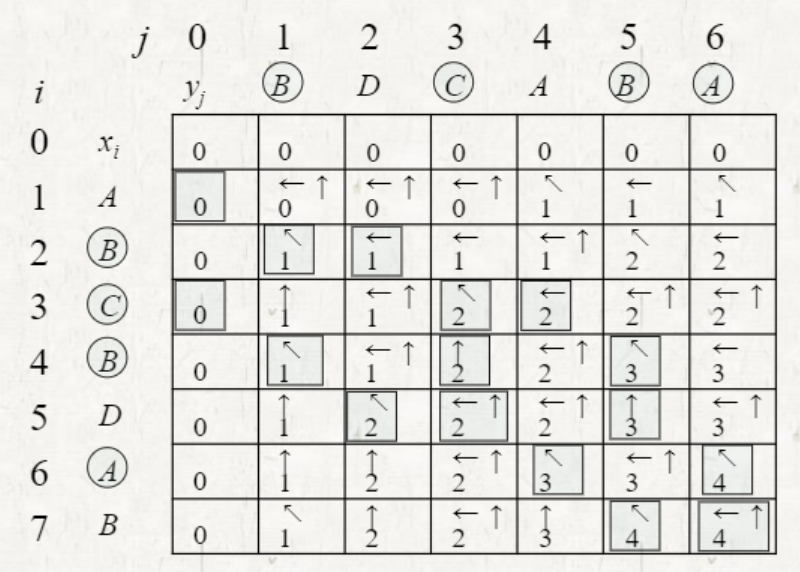
Space consumption for LCS
- c:
- b:
Running time of LCS
- for entry
Back-tracking 정보를 제공하지 않는다면?
- b 배열이 필요없다.
- c 배열에서 LCS의 길이만을 구하기 위해선 두 개의 행만이 필요하다.
- 이때 space consumption은
- m이 더 작다면 m x 2 행렬이 필요하다.
- n이 더 작다면 2 x n 행렬이 필요하다.
Matrix-chain multiplication
A (p x q) 와 B (r x s) 행렬이 있을 때, q = r 이어야 두 행렬을 곱할 수 있고, 필요한 공간은 pr이며, scalar multiplication의 횟수는 pqr이다.
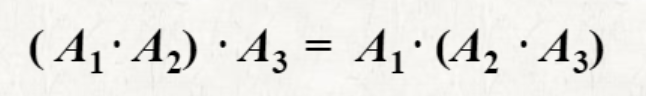 계산 순서에 따라 계산 결과는 동일하지만, 계산 횟수는 바뀔 수 있다.
계산 순서에 따라 계산 결과는 동일하지만, 계산 횟수는 바뀔 수 있다.
의 n개의 행렬이 주어졌을 때, 행렬은 x 의 차원을 가졌다고 가정하자.
scalar multiplication의 횟수를 최소화하는 계산 순서를 찾는 문제이다.
Solving Matrix-chain multiplication
1. Brute-force approach
p(n)을 n개의 행렬의 곱에 대한 괄호의 개수라고 하자.
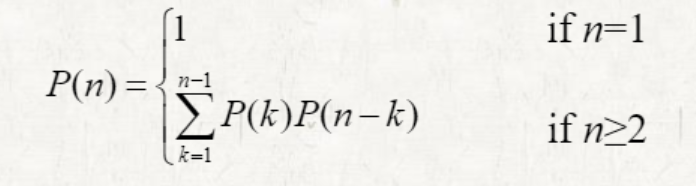 괄호의 개수는 이다.
괄호의 개수는 이다.
2. Dynamic programming
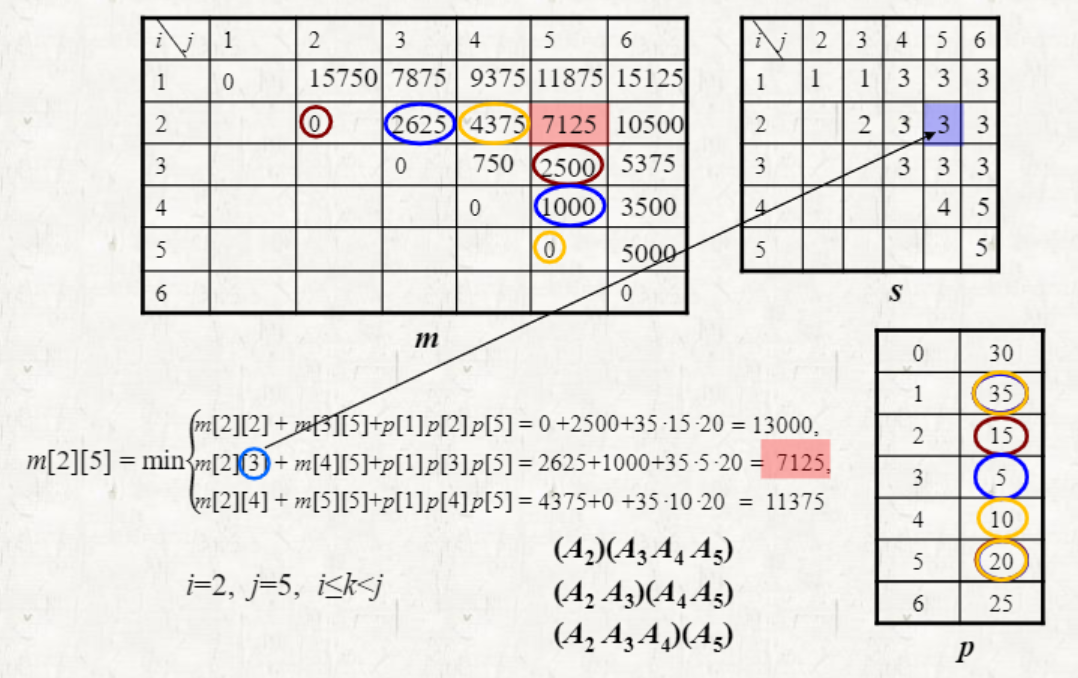
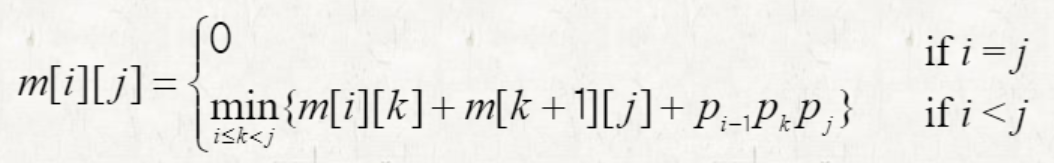 m[i][j]: 를 계산하는 scalar multiplication의 최소 횟수
m[i][j]: 를 계산하는 scalar multiplication의 최소 횟수
s[i][j]: m[i][j]를 최소화하는 k를 저장
: 를 계산하는데 소요되는 계산 횟수
p[i]: 의 행 개수를 저장
pseudocode of Matrix-chain multiplication
MATRIX-CHAIN-ORDER (p)
n = p.length−1
let m[1 .. n][1 .. n] and s[1 .. n−1][2 .. n] be new tables
for i = 1 to n
m[i][i] = 0 //initialize diagnal element to 0
for l = 2 to n // l is the chain length
for i = 1 to n − l + 1
j= i + l − 1
m[i][j] = ∞
for k = i to j − 1
q = m[i][k] + m[k+1][j] + p[i−1]p[k]p[j]
if q < m[i][j]
m[i][j] = q
s[i][j] = k
return m and sPRINT-OPTIMAL-PARENS (s,i,j)
if i == j
print "A_i"
else print "("
PRINT-OPTIMAL-PARENS(s, i, s[i][j])
PRINT-OPTIMAL-PARENS(s, s[i][j] +1, j)
print ")"s[i][j] = k의 값
Space consumption of Matrix-chain multiplication
- m:
- s: