Comparison sorts
정렬하기 위해 단지 비교 연산만을 사용하는 정렬 알고리즘
- Heapsort, Mergesort, Insertion sort, Selection sort, Quick sort
- 비교 연산: or
Lower bounds for comparison sorting
모든 comparison sort는 worst case에 n개의 element를 정렬하기 위해 시간이 소요된다.
필요한 가정
-
는 를 나타낸다. ()
- 기본 비교 연산 형태를 라고 가정한다.
-
모든 비교 연산이 동일하게 처리된다.
-
배열의 모든 element는 서로 다르다.
decision tree method
full binary tree의 형태
leaf node는 element가 정렬된 순열 형태이다.
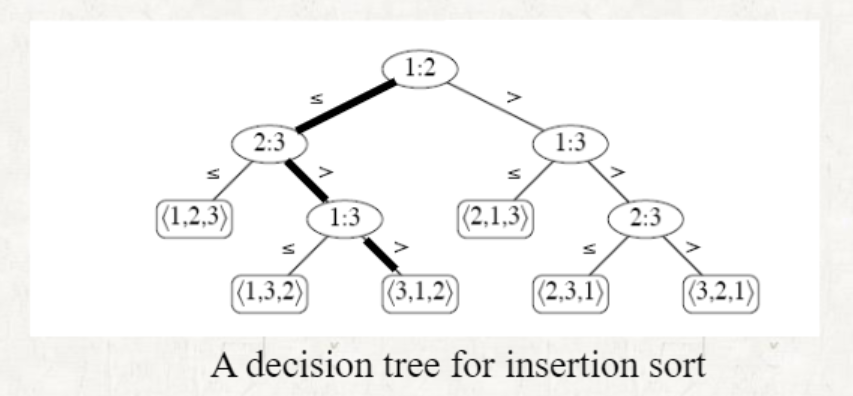 Left subtree는 형태의 순열
Left subtree는 형태의 순열
Right subtree는 형태의 순열
Running time in decision tree method
총 실행 시간은 decision tree에서 root에서 leaf까지 탐색하는 것과 동일하다.
The worst-case number of comparisons = the height of its decision tree
Height of its decision tree
- decision tree의 leaf 노드 개수는 이다.
- 트리 전체 노드 개수는 보다 많지만, 트리의 높이는 최소한 개의 리프 노드를 구분할 수 있을 만큼의 깊이를 가져야 하기 때문에 decision tree의 최소 높이는 이다.
- 트리의 높이를 h라고 할 때, Level h에서의 최대 노드 개수는 이다
- 이고, 양변에 를 취하면
따라서 decision tree 의 lower bound 는
Counting sort
배열에서 특정 element가 등장하는 횟수를 세어 정렬하는 알고리즘
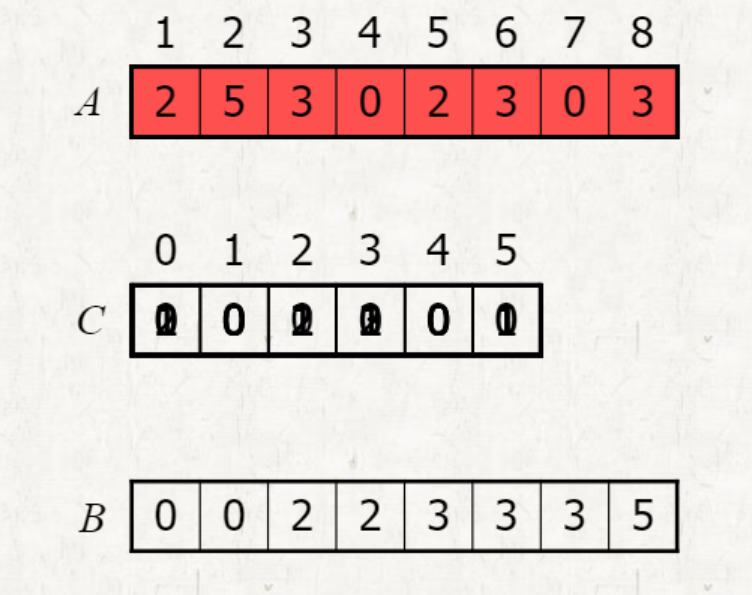 A는 원래의 배열
A는 원래의 배열
C는 A의 최대 숫자까지를 인덱스로 갖고 A에서 그 인덱스에 해당하는 숫자의 개수를 counting하는 배열
B는 counting sort를 수행한 배열
Running time of counting sort
n: A 배열의 크기, k: 가능한 가장 큰 값일 때,
stable of counting sort
배열 A에서의 같은 값을 가진 숫자들이 그 순서를 유지한 채로 배열 B에 정렬되는 것.
- 같은 값이라도 distinguishable 하다.
- 상대적인 순서가 그대로 유지되는 것이다.
prefix-sum of C
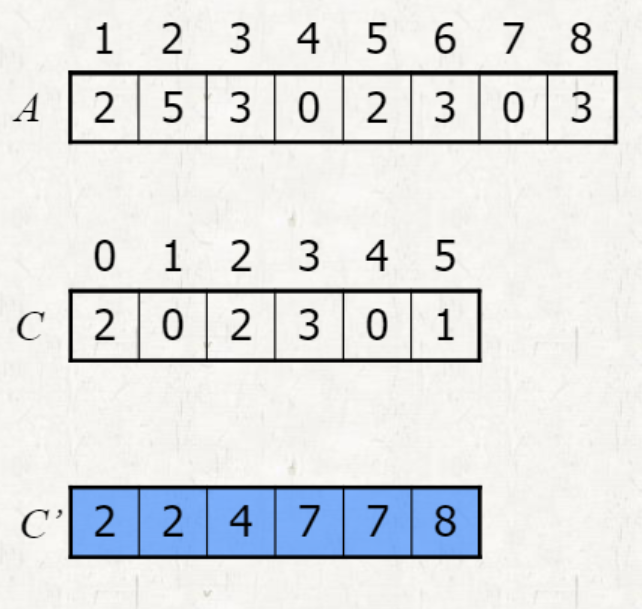
Running time of prefix-sum of C
-
- 1 + 2 + 3 + ... + k-1
-
- more simple form
precedure of counting sort
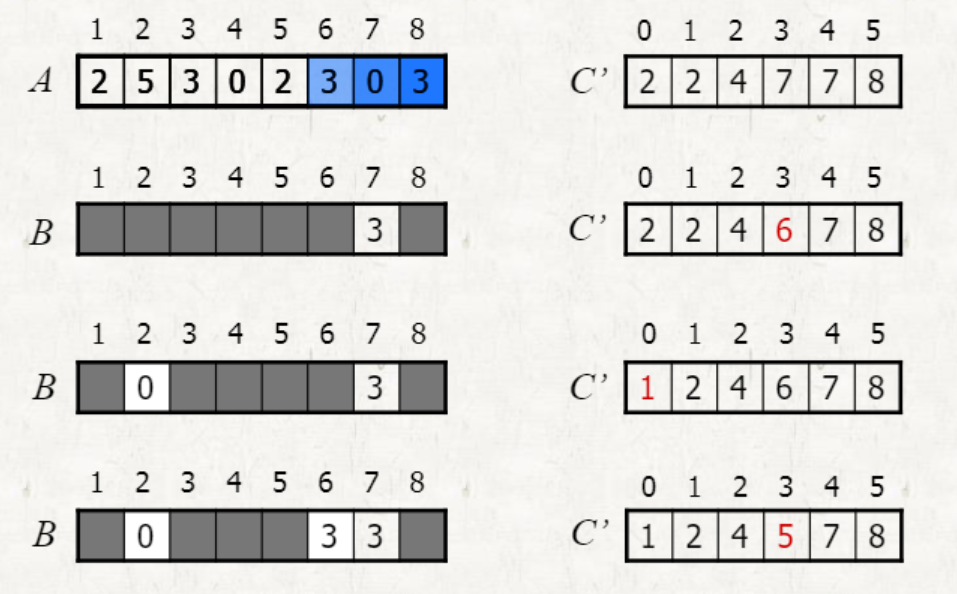
1. A 배열의 뒤부터 시작하여 A의 값에 맞는 C' 인덱스를 찾는다.
2. 해당 C'의 값에 맞는 B 인덱스에 C' 인덱스의 값을 저장한다.
3. 해당 C'의 값을 1 줄인다.
4. B가 다 채워질 때까지 (1)~(3) 의 과정을 반복한다.
pseudocode of counting sort
COUNTING-SORT (A, B, k)
for i = 0 to k
C[i] = 0 //initialize C
for j = 1 to A.length
C[A[j]] = C[A[j]] + 1
//C[i] contains the number of elements equal to i.
for i = 1 to k
C[i] = C[i-1] + C[i] //이미 C[i-1]까지는 C' = C이다. 따라서 C'가 따로 필요하지 않다.
//C[i] contains the number of elements less than
for j = A.length downto 1
B[C[A[j]] = A[j]
C[A[j]] = C[A[j]] - 1전체 시간 복잡도는 이다.
만약 k = n이라면 이다.
Radix sort
-
MSD -> LSD
- 왼쪽을 기준으로 시작하여 같다면 오른쪽으로 진행
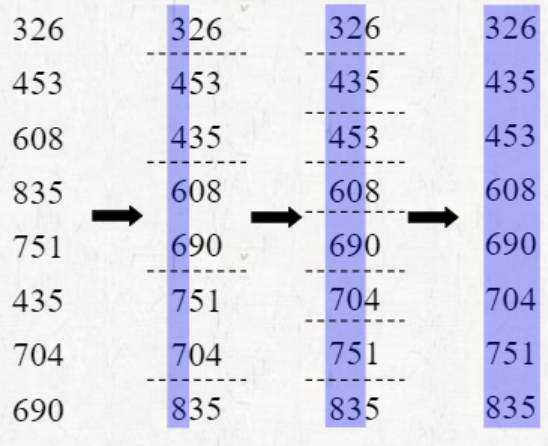
- 왼쪽을 기준으로 시작하여 같다면 오른쪽으로 진행
-
LSD -> MSD
- 오른쪽 기준으로 시작하여 정렬하되, 왼쪽에서 순서가 바뀌고 바로 왼쪽 bit가 같은 숫자인 경우 stable하게 정렬한다.
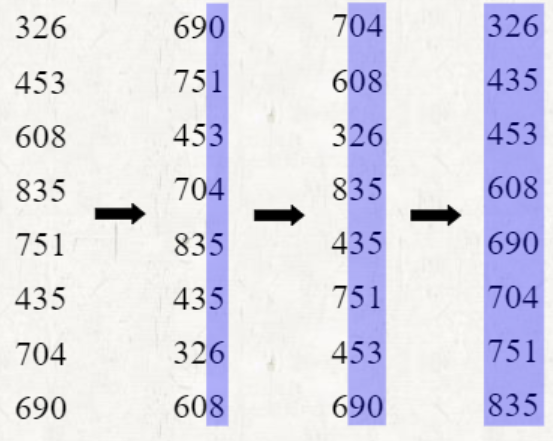
- 오른쪽 기준으로 시작하여 정렬하되, 왼쪽에서 순서가 바뀌고 바로 왼쪽 bit가 같은 숫자인 경우 stable하게 정렬한다.
pseudocode of Radix sort
RADIX-SORT (A, d)
for i = 1 to d
use a stable sort to sort array A on digit id: bit 수, n = 정렬할 개수, k는 각 자릿수가 취할 수 있는 값 (십진수라면 0~9)
LSD -> MSD 방식에서는 stable sort가 필수이지만, MSD -> LSD 방식에서는 stable sort가 필수는 아니다. 하지만 더 명확한 동작을 기대할 수는 있다.
running time of Radix sort
각 자릿수를 counting sort 한다고 생각하면 된다.
같은 상황에서, 전체를 counting sort를 이용하여 정렬한다면, n = 8, k = 999 이므로 linear time에 정렬할 수 없다.
n개의 b bits 수가 주어졌을 때, r ≤ b 이라면 RADIX-SORT의 시간 복잡도는 이다.
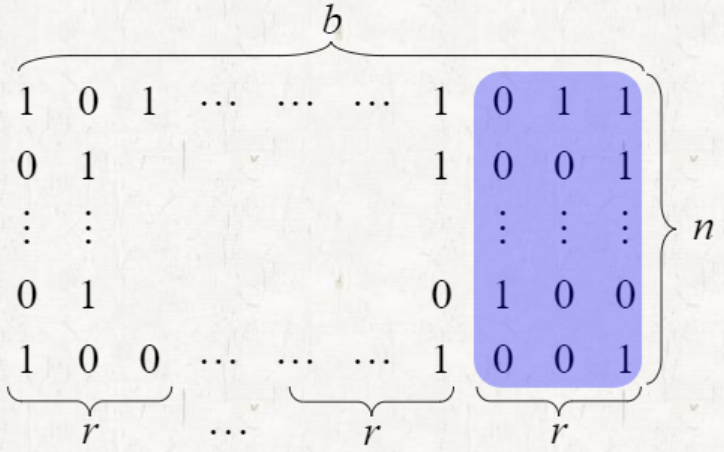 에서 d 대신 , k 대신 이다.
에서 d 대신 , k 대신 이다.
는 이진수 상황에서 r비트의 가능한 경우의 수이다.
Computing optimal "r" minimizing
-
-
r = b 를 선택하자.
-
-
-
-
-
r =
- = =
-
r >
- 증가 속도: 이므로 시간 복잡도는 r에 비례하여 계속 증가한다.
-
r <
- r이 작아진다면 은 증가하기 때문에 시간 복잡도도 비교적 커진다.
- 따라서 위의 경우, 을 선택하는 것이 좋다.
-
Radix sort vs Quick sort
-
Basic
-
Radix sort:
-
Quick sort:
-
이 경우, d가 과도하게 크다면 Quick sort가 유리할 수 있다.
-
-
-
이라고 가정하면 좋다.
-
Radix sort:
-
Quick sort:
-
