특정 순간에 최선으로 보이는 선택을 하는 알고리즘
- It makes a locally optimal choice in the hope that this choice will lead to a globally optimal solution
- It makes the choice before the subproblems are solved.
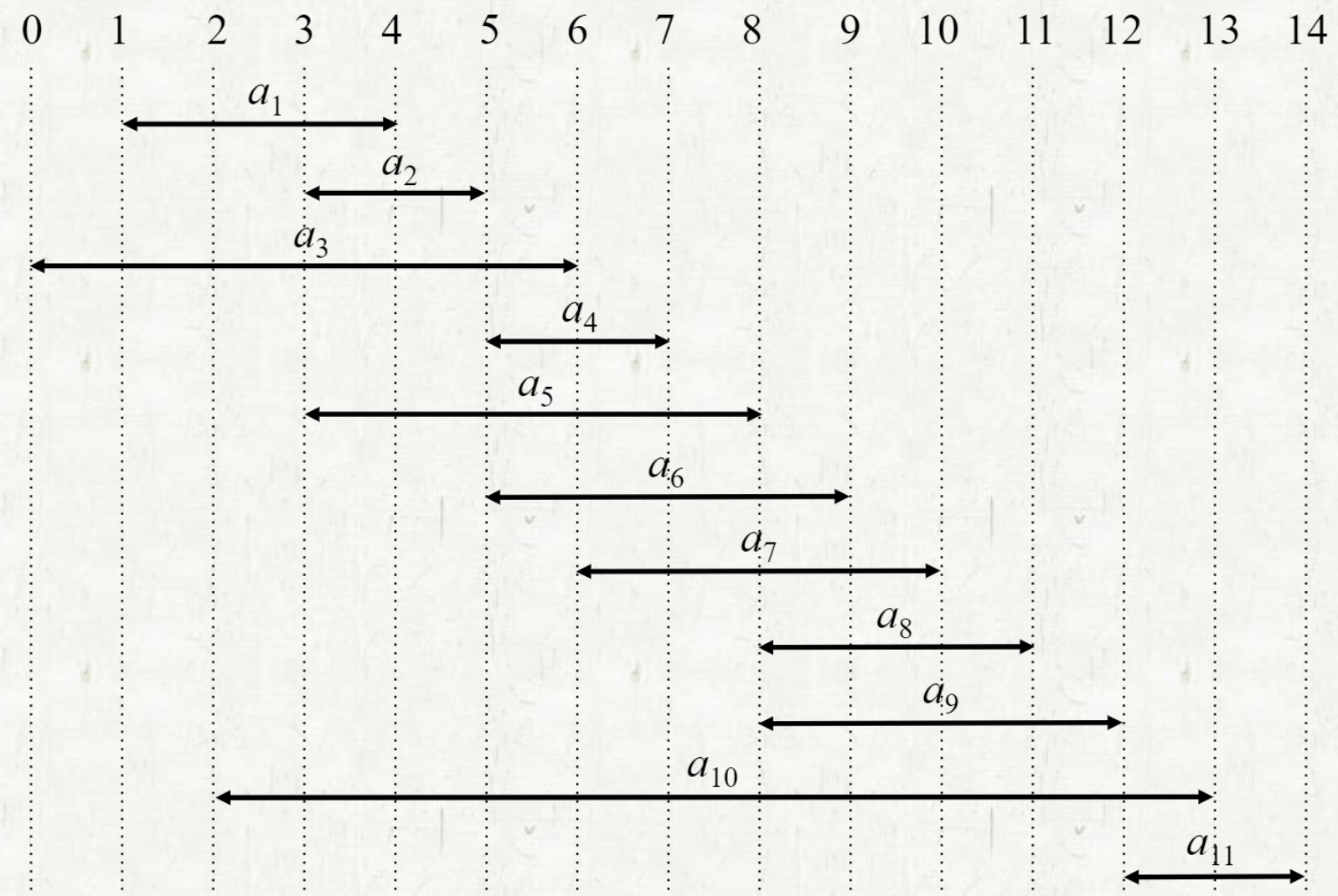
An activity selection problem
활동 시간이 겹치지 않도록 가장 큰 집합을 찾는 문제
S: {}
: 각 활동이 시작하는 시간
: 각 활동이 끝나는 시간
 compatible : [si, fi) and [sj, fj) do not overlap
compatible : [si, fi) and [sj, fj) do not overlap
largest subset: {}, {}
Solving an activity selection problem
Greedy algorithm
- 끝나는 시간을 오름차순으로 정렬하고, 끝나는 시간이 빠른 것 중에 이미 선택된 활동과 겹치지 않는 것을 고른다.
- {}
- 은 보다 무조건 빨리 끝나기 때문에 시작을 로 잡을 수도 있다.
Running time of an activity selection problem
- 각 단계에서 new activity와 latest activity를 비교
Dynamic programming vs Greedy algorithm
-
Greedy algorithm은 subproblem이 해결되기 전에 선택을 하고, Dynamic programming은 subproblem이 모두 해결되고 난 다음에 선택한다.
-
Greedy algorithm은 항상 최선의 선택을 하기 때문에 오직 하나의 subproblem이 존재하지만 Dynamic programming은 여러 개의 subproblem이 생성될 수 있다.
0-1 knapsack
n개의 물건이 있을 때, i번째 물건은 의 가치가 있고, 만큼의 용량을 차지할 때, 가방의 용량이 W라면 가방 속 물건의 가치를 최대화하기 위해서 어떤 물건을 얼만큼 담아야 하는가?
-
Greedy algorithm이 올바른 해답을 구해주지 못 한다.
-
Greedy algorithm은 의 결과가 큰 것부터 채워넣는다.
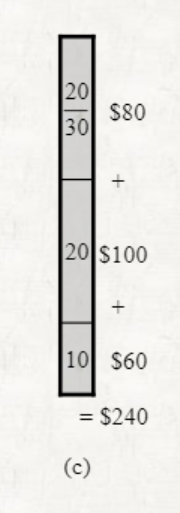
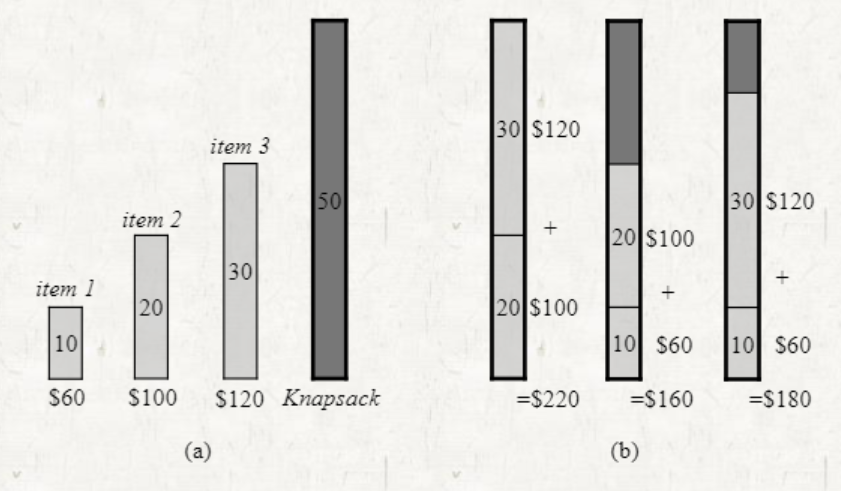 위 그림과 같은 경우에는 greedy algorithm이 올바른 해답을 구해주지 않는다.
위 그림과 같은 경우에는 greedy algorithm이 올바른 해답을 구해주지 않는다. -
Dynamic programming을 사용하면 올바른 해답을 얻을 수 있다.
- p[i][w]를 첫 번째부터 i번째 물건까지 고려했을 때, 배낭의 용량이 w일 때 얻을 수 있는 최대 가치라고 하자

Fractional knapsack
하나의 물건을 쪼개서 넣을 수 있는 0-1 kanpsack 문제이다.
- 이 경우, Greedy algorithm이 올바른 해답을 알려준다.
Huffman codes
데이터를 출현 빈도에 따라 다른 길이의 비트 문자열을 이용하여 압축하는 기술
Fixed-length code
압축할 문자들의 각 비트 문자열의 길이가 모두 같은 경우
- 3-bit fixed-length code로 100,000 characters 를 표현하기 위해서는 300,000개의 비트가 필요하다.
Variable-length code
압축할 문자들의 각 비트 문자열의 길이가 다른 경우
- 보통 저장 공간의 절약을 위해 빈도수가 높은 문자에 작은 길이의 비트 문자열을 할당한다.
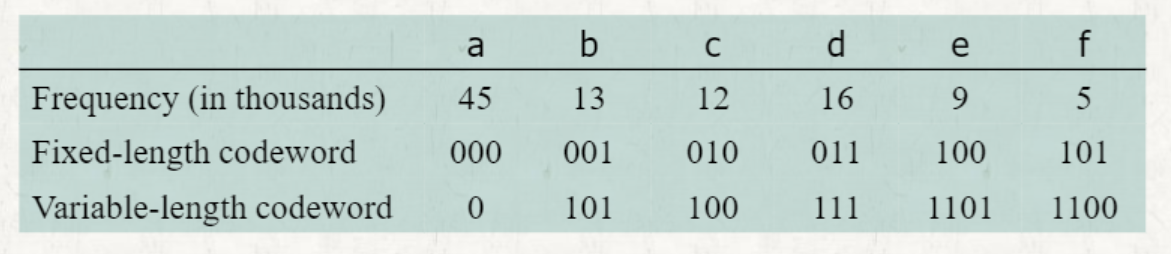 이 경우, (각 문자가 나오는 빈도수) X (Variable-length codeword의 길이) 의 합이 전체 비트수이다.
이 경우, (각 문자가 나오는 빈도수) X (Variable-length codeword의 길이) 의 합이 전체 비트수이다. - Encoding: 문자 -> codeword
- abc -> 0 101 100
- Decoding: codeword -> 문자
- 001011101 -> aabe
- Decoding의 경우, 001(aac/ab)처럼 중복 해석이 가능한 경우도 있을 수 있다.
- 중복 해석이 가능한 경우, 한 문자가 다른 문자의 prefix 이다.
Radix tree
codeword를 Decoing 할 때 사용하는 tree
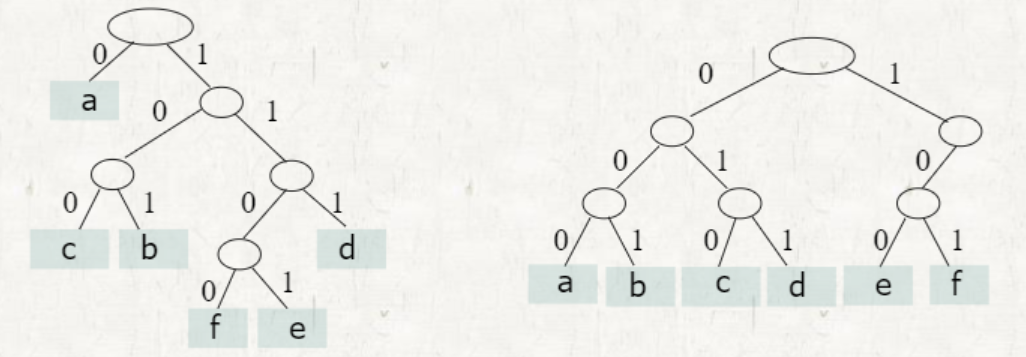 오른쪽의 tree는 e와 f를 구별하는 과정을 한 단계 줄일 수 있으므로 최적의 방법은 아니다.
오른쪽의 tree는 e와 f를 구별하는 과정을 한 단계 줄일 수 있으므로 최적의 방법은 아니다.
100: e, 101: f -> 10: e, 11: f로 바꿔서 사용하는 것이 이득이다.
Prefix tree
한 codeword가 다른 codeword의 prefix가 되지 않는 radix tree
- variable-length codeword의 prefix tree는 full binary tree이다.
- full binary tree는 codeword의 개수만큼의 leaf node를 가지고 있고 (codeword의 개수 - 1)의 개수만큼의 internal node를 가진다.
- 최적의 tree는 항상 full binary tree이다!
cost of tree
f(c): frequency of a character c
: length of the codeword for c
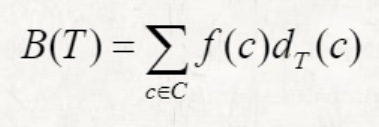
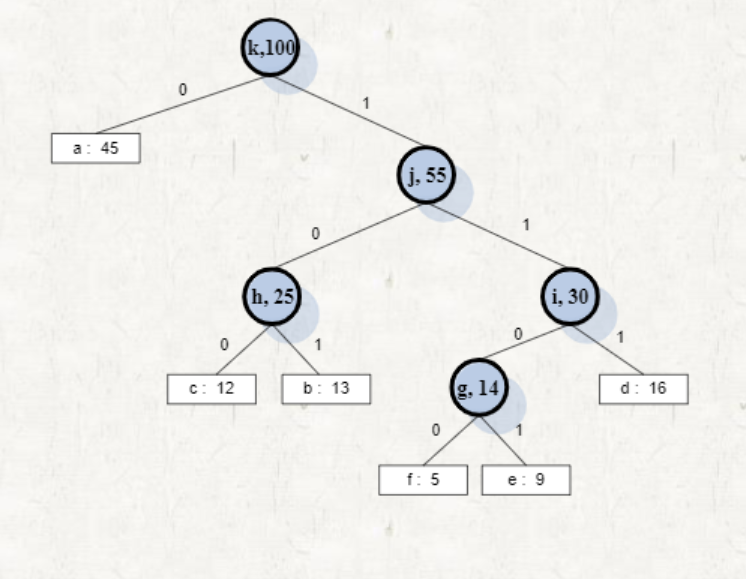
Solving huffman codes
Greedy algorithm을 이용하여 해결해보자
Optimal tree를 관찰하면 frequency가 작을수록 해당 노드의 level이 높고 codeword도 길다.
-
n개의 character 중 frequency가 가장 작은 2개를 찾는다.
-
2개를 새로운 노드(virtual node)를 사용해서 하나의 subtree로 만든다.
- virtual node는 두 개의 frequency를 합한 값을 frequency로 갖는다.
-
frequency가 가장 작은 2개를 제외한 기존의 character와 (2)에서 만든 virtual node를 포함하여 (1) ~ (2) 의 과정을 반복한다.
-
전체 node가 하나의 tree로 묶일 때까지 진행한다.
(1)의 과정은 부터 까지 소요된다.
- 각 과정마다 노드가 한 개씩 줄어들기 때문이다.
- subtree를 형성하는 과정은 이기 때문에 무시해도 된다.
따라서 Tree를 형성하는 전체 시간 복잡도는 이다.

위의 (1)의 과정에서 min-heap을 사용한다면?
frequency가 가장 작은 2개를 찾는 과정은 min-heap을 이용한다.
위의 과정에서 과정 (1)~(2) 를 하나의 사이클이라고 하자.
BUILD-MINHEAP:
MIN-HEAPIFY:
- 이 과정은 하나의 사이클에서 2번 진행된다.
INSERT:
- virtual node를 삽입한 후 MIN-HEAPIFY를 진행해야한다.
- 각 사이클에서 1번 진행된다.
Running time
BUILD-MINHEAP:
MERGE:
- 각 merge는 2개의 minimum selection과 1개의 insertion을 포함한다.
- 각 merge의 시간 복잡도는 이다.
따라서 Total running time은 = 이다.
To get optimal prefix code
C를 집합이라고 할 때, c∈C는 frequency f[c]를 가진다고 하자.
를 C에서 frequency가 가장 작은 2개라고 할 때, x와 y의 codeword의 길이가 같고, 마지막 bit만 다를 때 optimal prefix code를 얻을 수 있다. 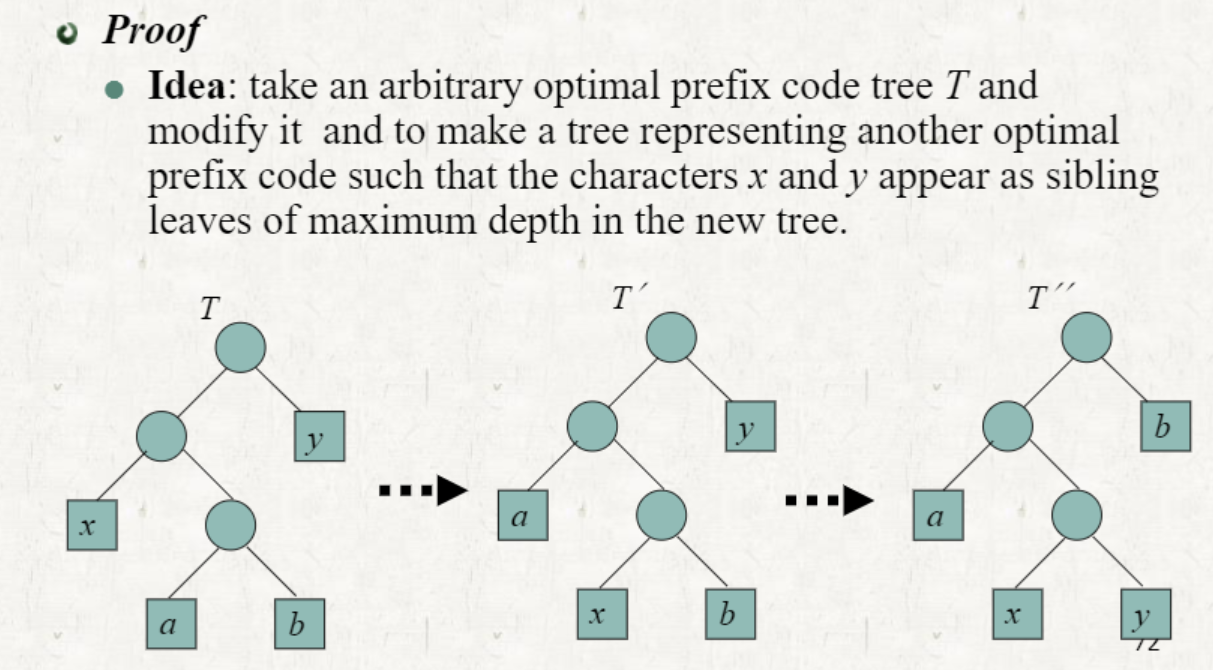 cost comsumption 관점에서 frequency가 작은 것의 codeword 길이가 긴 것이 유리하므로 prefix code를 임의로 조정할 수 있다.
cost comsumption 관점에서 frequency가 작은 것의 codeword 길이가 긴 것이 유리하므로 prefix code를 임의로 조정할 수 있다.
cost consumption
f(c): frequency of a character c
: length of the codeword for c
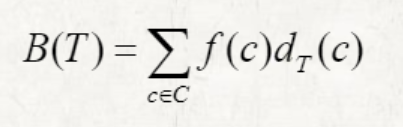
조정 전 cost: B(T) = ... + 2f(x) + 1f(y) + 3f(a) + 3f(b)
조정 후 cost: B(T'') = ... + 2f(a) + 1f(b) + 3f(x) + 3f(y)
두 식을 빼면
2(f(x)-f(a)) + (f(y) - f(b)) + 3(f(a) - f(x)) + 3(f(b) - f(y))
= f(a) - f(b) + 2(f(b) - f(y)) 0 이므로
B(T) B(T'') 이며, 조정 후의 cost가 더 적다.
T가 optimal prefix code라고 가정을 했다면 T''는 optimal prefix code일 수 있다..
frequency가 작은 것의 codeword를 길게하고, 마지막 비트만 같게 한다면 optimal tree를 얻을 수 있음을 보여준다.
vitual node를 추가해도 optimal prefix code임이 보장되는 이유는 무엇일까?
C를 집합이라고 할 때, c∈C는 frequency f[c]를 가진다고 하자.
를 C에서 frequency가 가장 작은 2개라고 하자.
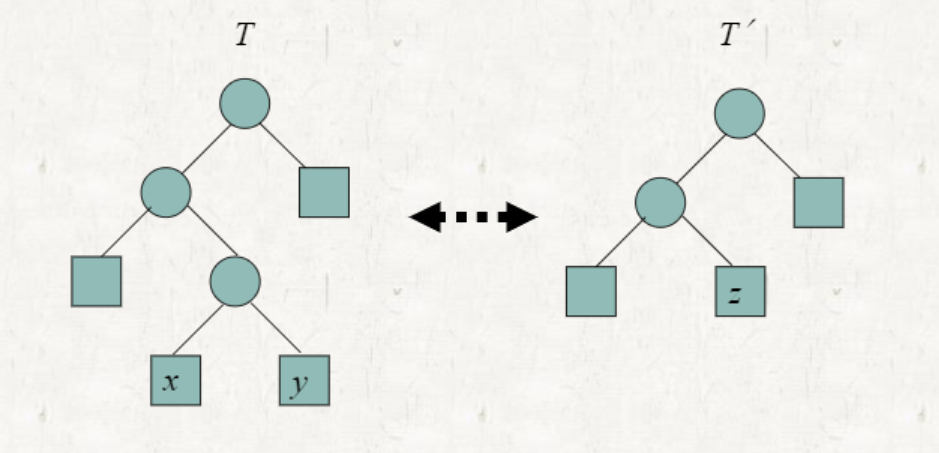
C′= C - {x, y}U{z} 이며, f[z] = f[x] + f[y] 라고 예상할 수 있다.
T를 optimal prefix code for the alphabet C′라고 하자.
T'이 optimal일 때, T가 optimal임을 증명하자
-
-
T가 optimal prefix code가 아니라고 가정하자.
-
(2)의 말은 즉 를 만족시키는 있다는 것과 같다.
-
를 의 공통된 를 leaf (with f[z] = f[x] + f[y])로 대신할 수 있다.
-
=
<
= () -
(5)은 가 optimal tree라는 가정에 모순이다.
-
따라서 가 optimal tree라면, 또한 optimal tree 이다.
이는 가상의 노드를 추가하고, 병합해도 optimal tree가 유지됨을 보여준다.
