Quick sort
- A[p...r] 에서 A[r]을 기준으로 삼는다.
- 배열 A에서, A[r]보다 작으면 A의 왼쪽, 크면 A의 오른쪽부터 채운다.
- 세분화된 배열 A[p...q], A[q+1, r]에 대해서도 (1), (2)의 과정을 진행한다.
pseudo code of Quick sort
QUICKSORT(A, p, r)
if p < r
q = PARTITION(A, p, r)
QUICKSORT(A, p, q-1)
QUICKSORT(A, q+1, r)
pseudo code of partition
PARTITION (A,p,r)
x = A[r]
i = p-1
for j = p to r - 1
if A[j] ≤ x
i = i + 1
exchange A[i] with A[j]
exchange A[i+1] with A[r]
return i+1
running time of partition
θ(n) (n = r - p 일때)
running time of heap sort
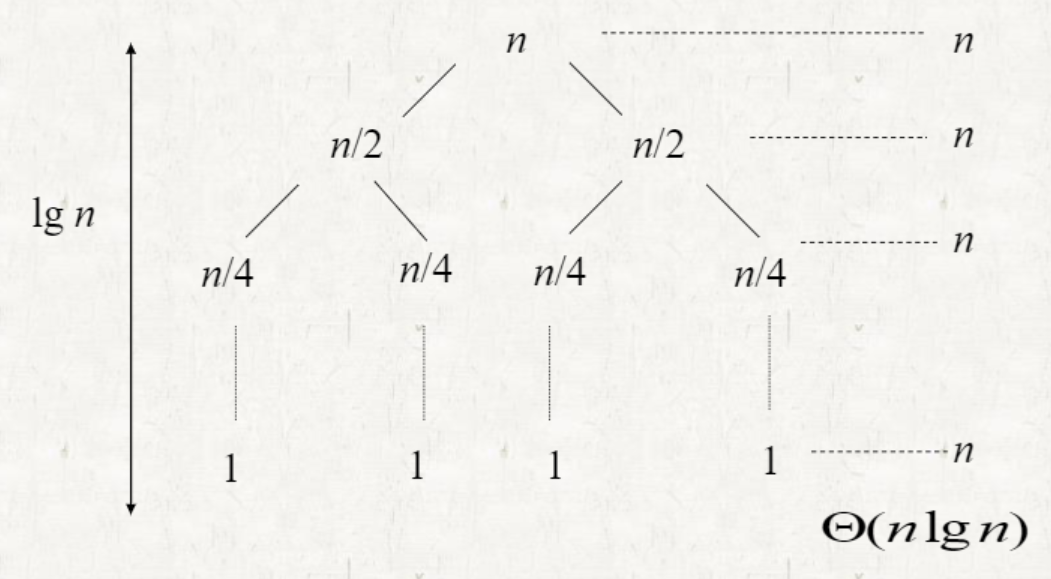
- Balanced partitioning
- partition 후의 세분화된 두 배열의 크기가 비슷할 때 (⌊n/2⌋, ⌈n/2⌉-1)
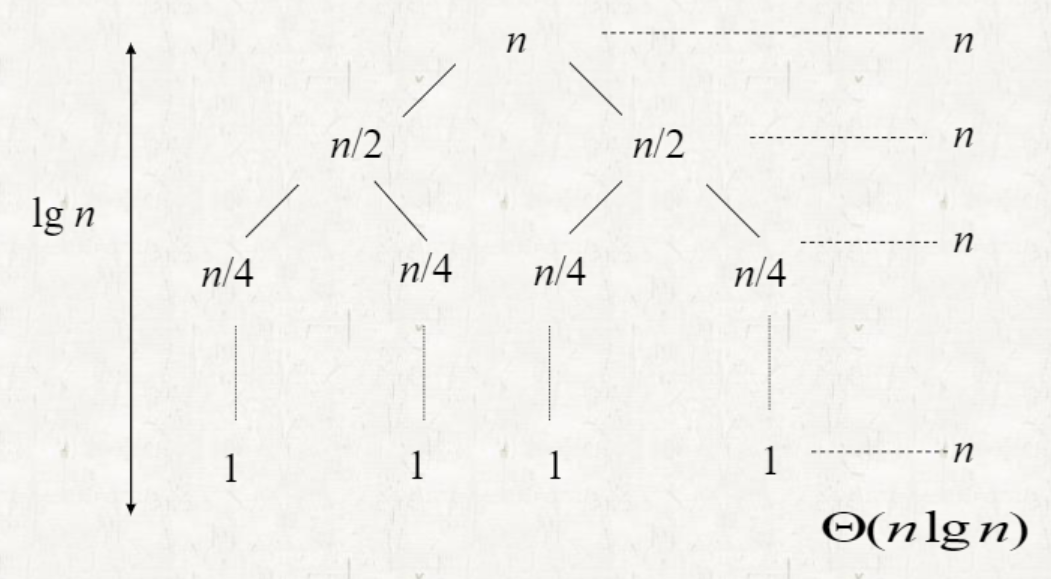
- T(n)≤2T(n/2)+Θ(n)=O(nlogn)
- Unbalanced partitioning
- partition 후의 세분화된 두 배열의 크기가 심하게 비대칭인 경우하게 비대칭인 경우 (1, n-1)
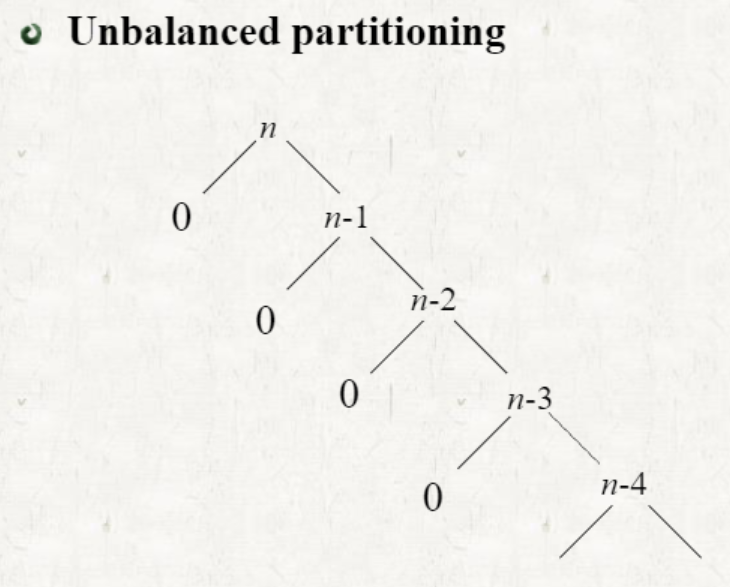
- T(n)=T(n−1)+Θ(n) =k=1∑nΘ(k) = Θ(k=1∑nk)
= Θ(n²)
Worst case analysis
substitusion method로 Unbalanced partitioning의 시간 복잡도를 증명해보자.
T(n)=max(T(q)+T(n−q−1))+Θ(n) (0 ≤ q ≤ n-1)
Show that T(n)≤cn² for some constant c.
T(n)≤max(cq²+c(n−q−1)²)+Θ(n) (0 ≤ q ≤ n-1)
=c•max(q²+(n−q−1)²)+Θ(n) (0 ≤ q ≤ n-1)
=c•max(2q²−2q(n−1)+(n−1)²)+Θ(n) (0 ≤ q ≤ n-1)
=c•max(2(q−(n−1)/2)²+(n−1)²/2)+Θ(n) (0 ≤ q ≤ n-1)
T(n)≤c⋅max0≤q≤n−1(2(q−(n−1)/2)2+(n−1)2/2)+Θ(n)
=c⋅(n−1)2+Θ(n)
=cn2−c(2n−1)+Θ(n)
≤cn2
따라서 −c(2n−1)+θ(n)≤0 을 만족하는 큰 c를 선택하면 T(n)=O(n2) 이다.
Average case analysis 1
worst case의 경우보다 best case의 경우에 더 가깝다. 심하게 unbalanced 한 경우에만 worst case로 분류되기 때문이다.
E[T(n)]=n1(∑q=1nE[T(q−1)]+E[T(n−q)]+Θ(n))
=n2(∑q=2n−1E[T(q)]+Θ(n))
E: 평균, 기댓값
pivot의 위치가 1에서부터 n-1 일때까지의 모든 경우의 수의 합을 n으로 나눈 것이다.
Show that T(n)≤cnlogn for some constant c.
-
T(k) ≤ cklogk 가 𝑘 ≤ 𝑛 − 1 (k≤n−1)에서 성립한다고 가정하자.
-
E[T(n)]=n2∑q=2n−1E[T(q)]+Θ(n)
-
E[T(n)]≤n2∑q=2n−1cqlogq+Θ(n)
-
∑q=2n−1qlogq 는 대략적으로 ∫2n−1qlogqdq 로 근사할 수 있다. (부분 적분법을 이용하여 계산한다.)
-
E[T(n)]≤c⋅logn⋅2nn(n−1)+Θ(n)
-
E[T(n)]≤cnlogn+Θ(n)
따라서 T(n)≤cnlogn 임을 보일 수 있다.
Average case analysis 2
X를 n개의 element가 있는 배열에서 비교 횟수라고 할 때, average running time of QUICK SORT는 T(n)=O(n+E[X]) 이다.
각 PARTITION에서 일어나는 비교 횟수를 셀 필요 없이, 전체 알고리즘 실행 동안의 비교 횟수에 대한 경계(bound) 를 도출해보자
- zi: 정렬된 배열에서 i번째 작은 요소
- Zij = zi,zi+1,...,zj
- zi 와 zj 는 최대 한번 (0번 또는 1번) 비교된다.
- pivot은 한번 PARTITION에 사용되면 다시 사용되지 않는다.
- 각 PARTITION에서 사용된 pivot은 각 요소와 비교된다.
E[X] = ∑i=1n−1∑j=i+1nPr{ziis compared tozj}
- zi 가 zj 와 비교되기 위해서는 둘 중 하나가 반드시 pivot이어야 한다.
- 둘 중 하나가 pivot일 확률 = j−i+12
- E[X] 는 기댓값으로, (확률 변수 값) x (확률) 이다.
- 여기서는 Bernoulli Distribution를 따른다.
- zi 와 zj 가 서로 비교되었을 때 확률 변수: 1
- zi 와 zj 가 서로 비교되지 않았을 때의 확률 변수: 0
- 따라서 위 식은 전체 숫자에 대해 각 쌍이 서로 비교가 되었는지를 통해 나타낸 전체 비교 연산의 기댓값이다.
- E[X] = ∑i=1n−1∑j=i+1n{1×j−i+12+0×j−i+1j−i−1}
- = ∑i=1n−1∑j=i+1n{j−i+12}
E[X] = ∑i=1n−1∑j=i+1n{j−i+12} 의 계산
k=j−i 라고 하자
E[X]
= ∑i=1n−1∑j=i+1n{j−i+12}
= ∑i=1n−1∑k=1n−i{k+12}
< ∑i=1n−1∑k=1n−i{k2}
(∑k=1n−i{k2} ≤ 2lnn+2)
= ∑i=1n−1O(logn)
= O(logn)
Randomized quick sort
pivot을 배열의 맨 끝 값이 아닌 random하게 뽑아 진행하는 quick sort
pseudocode of randomized-quick sort
RANDOMIZED-QUICKSORT(A, p, r)
if p < r
q = RANDOMIZED-PARTITION(A, p, r)
RANDOMIZED-QUICKSORT(A, p, q-1)
RANDOMIZED-QUICKSORT(A, q+1, r)
pseudocode of randomized-partition
RANDOMIZED-PARTITION(A, p, r)
i = RANDOM(p, r)
exchange A[r] with A[i]
return PARTITION(A, p, r)