클러스터링 펙터란?
물리적 디스크파일에서 데이터가 모여있는 정도를 나타낸다.
예를들어 OLTP의 필수 컬럼으로 날짜가 있는데 데이터가 입력될때마다 날짜로 정렬하듯이 데이터가 입력된다.
이것을 보고 날짜별 Clustering Factor가 좋다 라고한다.
주의할점은 테이블에는 그저 날짜별로 입력이 된것일뿐 DBMS는 이것을 신뢰하지않고 날짜 컬럼으로 index를 만들어야 그 순서를 신뢰한다.
클러스터링 펙터가 좋다면?
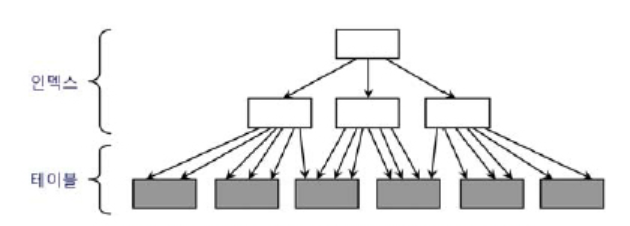
위그림은 클러스터링 펙터가 좋은 예이다.
인덱스의 논리적 순서와 테이블의 물리적 순서가 완벽히 일치하면 이런 그림이 나온다.
즉 인덱스에서 Rowid로 가져온 하나의 블록을 버퍼캐시에 적재할때, 다음 Rowid도 미리 적재된 블록을 가리킬 확률이 매우 높다
이것은 물리적 디스크I/O를 현격히 떨어트린다.
클러스터링 펙터가 나쁘면?
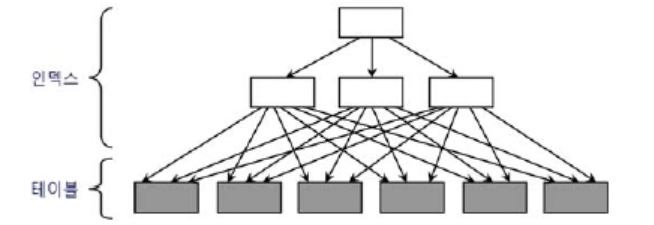
위는 클러스터링 펙터가 나쁜 예이다.
Index Range Scan시 Single Block IO로 인해 가져온 하나의 물리적 블록이 바로 다음 Scan에서는 전혀다른 블록을 가리킨다.
즉 매번 조회마다 새로운 블록을 검색하고 적재하며 버퍼캐시에서 밀려나는 행위가 반복된다
이것은 물리적 디스크 I/O를 최대치로 높힌다.
어떻게 확인하나?
예를들어 obj테이블의 id별로 정렬하여 새로운 t 를 만들었다.
create table t as select * from obj order by obj_id;그후 t테이블의 id 인덱스와 name 인덱스를 두개 만든다.
create index t_obj_id on t(obj_id);
create index t_obj_name on t(obj_name);통계정보를 수집한다.
exec dbms_stats.gather_table_stats(user,'t');데이터를 출력한다.
select i.index_name, t.blocks, i.num_rows, i.clostering_factor
from user_table t, user_indexes i
where t.table_name = 't'
and i.table_name = t.table_name;| Index_name | blocks | num_rows | clustering_factor |
|---|---|---|---|
| t_obj_id | 709 | 50093 | 689 |
| t_obj_name | 709 | 50093 | 24936 |
위에서 본 clustering_factor의 값이 blocks에 가까울수록 CF가 좋고
num_rows에 가까울 수록 CF가 나쁘다.
clustering_factor 값의 계산원리는 아래와 같다.
변수clustering_factor를 선언한다.
인덱스 리프블록에서 처음부터 끝까지 스캔하며 rowid로 블록번호를 취한다.
현재의 블록번호와 전의 블록번호가 다르면 변수값을 +1 한다.
CF로 무엇을 판별하나?
Index Scan의 효율을 판별할 수 있다.
손익 분기점 이라고 부르며, 대개 Index 손익분기점은 5~20% 이다.
100개의 데이터중 5개~20개 까지가 인덱스로 스캔하기 적절하다는 뜻이다.
여기서 CF의 개입이 있는데 CF가 나쁠수록 손익분기점은 1%미만 까지 떨어질 수 있다. 반대로 CF가 좋을수록 90%수준까지 올라가기도 한다.
