NL조인의 약점을 극복한 HashJoin
7.3버전에서 처음 소개된 해시조인은 소트 머지 조인과 NL조인이 효과적이지 못한 상황에 대한 대안으로써 개발되었다.
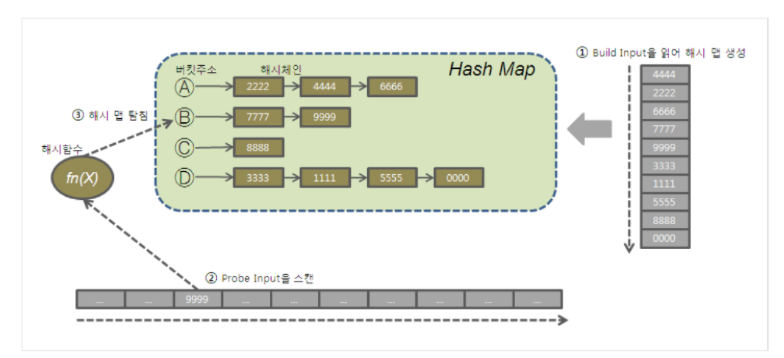
해시조인은 둘중 작은 집합을 Build Input으로 읽어 Hash Area에 해시테이블을 생성하고 반대쪽 큰 집합을 Probe Input으로 읽어 해시테이블을 탐색하며 조인한다.
내부 원리
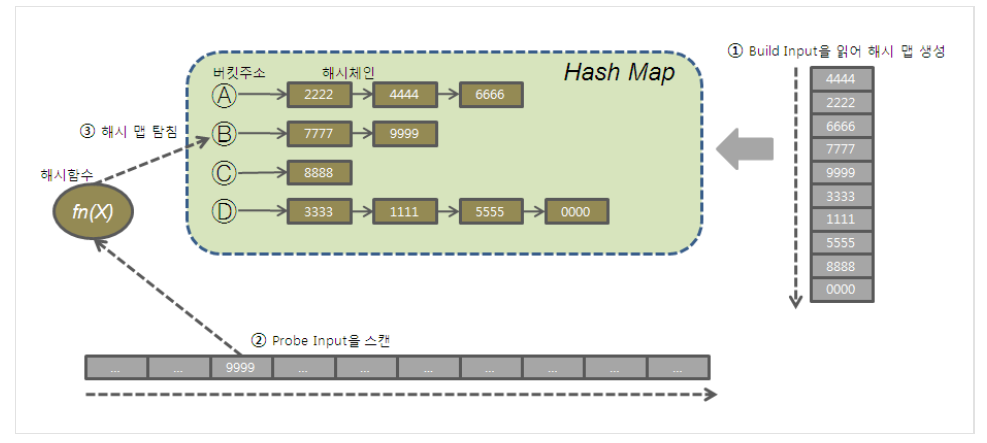
- 해시테이블을 생성할때 키값을 해시함수에 넣고 리턴받은 버킷주소로 찾아가 해시 체인에 엔트리를 연결한다.
- 해시 테이블을 탐색할때도 해시함수에 리턴받은 버킷주소로 찾아가 체인을 스캔하며 데이터를 찾는다.
- 그림에서 처럼 하나의 버킷주소에 여러개의 체인이 달릴수 있다.
이 특성을 통해 Build Input이 작은( 버킷주소에 체인이 적게 달려있는)상태가 해시조인의 성능이 효과적일 때다. - 해시조인은 소트 머지 조인처럼 정렬하기위한 부담이나 NL조인의 Random 액세스의 부담도 없지만 해시 테이블을 생성하는 비용이 수반된다.
Build Input이 얼마나 작아야 할까?
정확히 말해 PGA 메모리에 할당되는 Hash Area에 담길 정도로 충분히 작아야 한다. 만약 이를 초과할 시 디스크에 썻다가 다시 읽어들이는 과정을 거치므로 성능이 많이 저하된다.
해시조인은 왜 빠를까?
해시조인은 PGA 영역에 할당되는 것에 그 이유가 있다.
NL 조인은 Outer 테이블에서 읽히는 레코드마다 Inner 쪽 테이블을 버퍼캐시 탐색을 위해 래치 획득을 반복하지만, 해싲인은 래치 획득과정 없이 PGA에서 빠르게 데이터를 탐색한다.
해시조인의 힌트.
select /*+ use_hash(d e) */ d.deptno, e.ename
from dept d, emp e
~~~위와 같은 힌트는 d e 테이블을 해시조인 하겠다는 의미이다.
하지만 해시조인이라고 명시할뿐 순서는 옵티마이저가 정한다.
(크기가 작은 dept 테이블을 Build Input으로 정한다.)
순서를 사용자가 정할땐 ordered, leading swap_join_inputs 등의 명령어를 사용한다.
select /*+ use_hash(d e) swap_join_inputs(e) */ d.deptno,
e.enamed e 테이블을 해시조인 하며 e테이블을 build input으로 지정한다.
해시조인의 성능 키포인트
해시조인은 Build Input의 크기가 PGA의 해쉬 영역에 포함될만큼 작고,
버킷의 체인이 작을수록 최대의 효율을 낸다.
버킷의 체인이 크기가 작다는 말은 해쉬키값의 중복값이 적다는 의미이다.
예를들어 해시키값이 주문일자 같은 변별력이 적은 타입은 하나의 버킷에 많은 체인을 생성한다.
이는 NL조인에서 Outer Table의 인덱스 선두 컬럼이 주문일자이며, Inner table에서 주문번호로 값을 구별할떄와 비슷하다.
Outer Table에서 엄청난 Random 액세스를 생성하며 하나의 결과값을 위해 불필요한 연산이 생긴다.
