병렬쿼리의 기본매커니즘은 멀티 프로세스(또는 쓰레드)가 동시에 작업을 처리한다는 것을 뜻한다. 다같이 후딱 끝냅시다
병렬 처리 관리자 Query Coordinator
QC는 병렬 SQL문을 발행한 세션을 말하고 병렬 서버 프로세스는 실제 작업을 수행하는 개별 세션들을 말한다.
- 작업 순서
-
병렬 SQL 명령을 내리면 QC는 병렬도, 오퍼레이션 종류에 따라 하나 또는 두개의 병렬 서버 집합을 할당한다. 우선 서버 풀로부터 필요한 만큼 서버 프로세스를 확보하고, 부족한 부분은 새로 생성한다.
-
QC는 각 병렬 서버에게 작업을 할당하고 관리한다.
-
병렬로 처리하도록 지시하지 안흔 테이블은 QC가 직접 처리한다.
-
QC는 각 병렬 서버들로부터 산출물을 건네받고 통합하는 작업을 한다.
-
이 통합 산출물을 사용자에게 건네주며, 스칼라 서브쿼리도 QC가 수행함.
테이블 큐
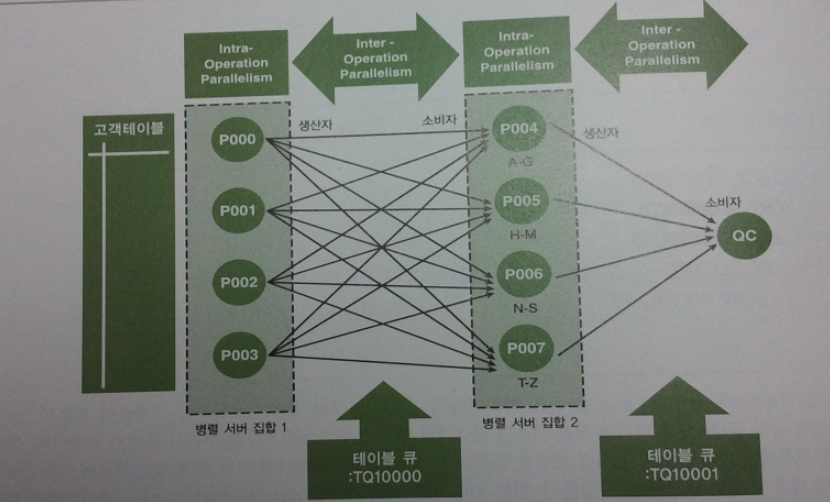
위 그림은 각 병렬 프로세스가 각자의 범위만을 처리한뒤 다음 서버에 전달하며 머지하는 방식이다.
서버집합 1은 A-Z를 분배하여 전달하고 서버집합 2는 이것을 정렬하여 QC에게 전달한다.
QC는 그저 전달받은 데이터를 합치기만 하면 된다.
이떄, Intra-Operation Parallelism, Inter-Operation Parallelism이 동시에 발생한다.
- Intra-Operation Parallelism
- 서로 배타적인 범위를 동시에 처리하는 것
- 서버집합 내부에서는 각자의 일만 하기때문에 서로 데이터를 주고받을 일이 없다.
- Inter-Operation Parallelism
- 데이터를 분배해서 서버집합2에 데이터 전송
- 데이터를 정렬하여 QC에 데이터 전송
- 작업내용을 전달하기 때문에 서버집합간에 항상 통신이 발생한다
쿼리 서버 집합간 P->P Inter-Operation-Parallelism 이 일어날땐, 사용자가 지정한 병렬도의 2배만큼 서버프로세스가 필요하다.
그리고 테이블 큐에는 병렬도의 제곱만큼의 파이프 라인이 필요하다
위그림에서 4개의 서버프로세스가 통신하므로 8개의 서버프로세스가 필요하고
이둘이 통신할때 16개의 파이프 라인이 사용된걸 볼 수 있다.
실행 계획상 생성자와 소비자
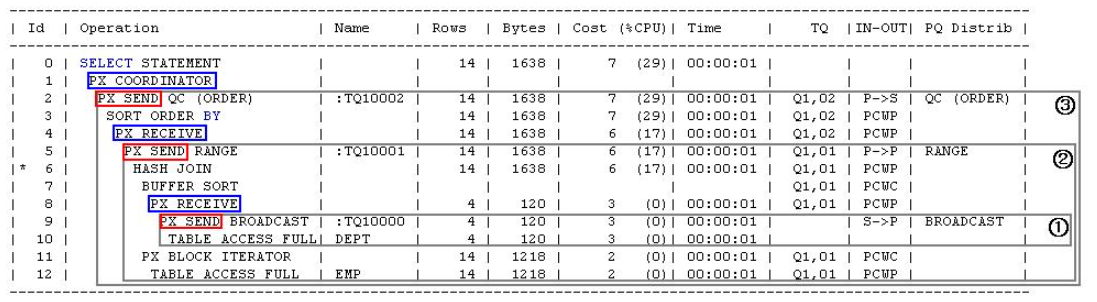
위 그림은 전형적인 병렬쿼리의 실행 계획이다.
IN-OUT모습을 보자.
-
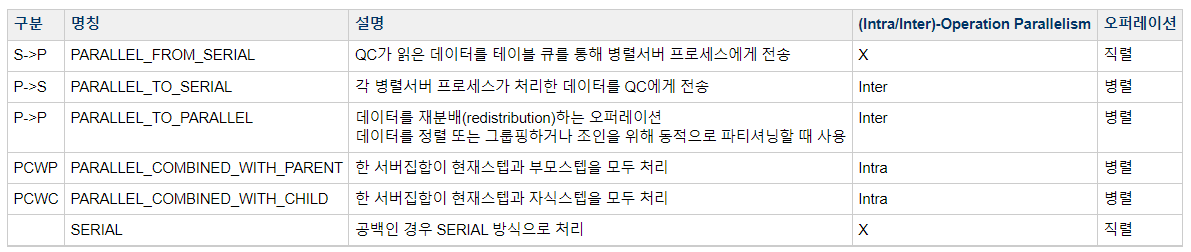
S -> Q
Parallel_from_serial 이다. 위 실행 계획에서 9번에 해당하며 QC가 읽은 데이터를 테이블 큐를통해 병렬 프로세스에게 전달한다. -
P -> S
Parallel_to_seria 이다. 위에서 2번 실행 계획이며 각 병렬프로세스가 작업한 내용을 QC에게 전달하는 것을 말한다. 이떄 Inter-Operation-Parallelism이 발생한다. S -> Q 는 S가 병렬프로세스로 보내는것이므로 통신이 발생해도 Inter-Operation-Parallelism이 아니다.
-
P -> P
데이터를 재 분배하므로 위에서 5번 계획에 해당된다.
실행계획에서 P->P가 나타난다면 무조건 두개의 서버집합이 처리한다는 사실을 알 수 있다. 데이터를 정렬 또는 그룹핑, 조인 등 동적으로 파티셔닝 할때 사용되며 병렬 프로세스간의 통신이 발생하므로 Inter-Operation-Parallelism에 해당된다. -
PCWP (Parent)
위에서 3,4,6,12 번에 해당된다.
현재 스텝과 부모 스텝을 모두 처리함을 의미한다.
한 서버 집합이 일련의 오퍼레이션을 처리한다는 뜻이며 분명 병렬 오퍼레이션 이지만, 한 서버 집합 내에서는 통신이 발생하지 않으므로 Intra에 속한다. -
PCWC (Child)
위에서 7번에 해당하며, 현재 스텝과 자식 스텝을 모두 처리한다.
PCWC도 한서버 집합내에 통신이 발생하지 않으므로 Intra에 속함
규칙
- S > P, P > S, P > P 는 프로세스간 통신이 발생한다.
- PCWP와 PCWC는 프로세스간 통신이 발생하지 않으며,각 병렬 서버가 독립적으로 여러 스템을 처리 할 때 나타난다.
데이터
분배의 방식은 5가지가 안전하다.
- Range
- orderby, groupby 를 병렬로 처리할깨 사용된다.
- 두번째 서버집합 마다 프로세스의 처리범위를 지정한다
- Hash
- 조인이나 해시그룹핑을 병렬로 사용할때 사용한다.
- 키값을 해시함수에 넣고, 리턴값에 따라 데이터르 분배
- BROADCAST
- QC또는 첫번째 서브 집합에 속한 프로세스들이 두번쨰 서버 집합에 속한 '모든'프로새스 들에게 정의한다.
- KEY
- 특정 컬럼 기준으로 테이블 또는 인덱스를 파티셔닝 할떄 사용됨
- ROUND ROBIN
- 무작위로 반대편 벙렬 서버에 데이터를 분배한다. 단 골고루 분배되게는 가능하다.
Granule
Granule은 데이터를 병렬로 처리할 때 일의 최소 단위이다.
