관리가 간편한 파티셔닝
테이블과 인덱스를 파티션 단위로 나누는것을 파티셔닝 이라고 한다.
하나의 테이블 스페이스에 하나의 세그먼트가 일반적 이지만
파티셔닝 되었을땐 하나의 테이블 스페이스에 여러개의 세그먼트가 나누어져 있다.
이점
관리가 용이하다.
- 파티션 단위 백업, 추가, 삭제, 변경
성능의 상승
- 파티션 단위 조회 및 DML 수행
예를들어 특정 조건에 의해 하나의 파티션만 읽어도 된다면 그 파티션만 읽는다. 이것을 파티션Pruning 이라고 한다.
파티셔닝 해보자.
create table partition_table
partition by range(deptno) (
partition p1 values less than(20)
,partition p3 values less than(30)
,partition p3 values less than(40)
)
as
select * from emp;위는 partition_table을 생성하는 문구이다.
2행에서 range는 파티션 저장 구조를 설정한다.
range(deptno)는 deptno를 범위별로 파티셔닝 하겠다는 뜻이다.
아래에는 제약조건을 설정한다.
p1, p2, p3 세그먼트를 생성하며 조건을 values 뒤에 설정한다.
파티션 저장 구조
저장 구조는 크게 3가지로
- Range 파티셔닝
- Hash 파티셔닝
- List 파티셔닝
가 있고 이들은 범위, 해싱기법, 분류 기법으로 데이터를 분류한다.
다시 세부적으로 복합 파티셔닝이 가능한데 다음과 같다.
- Range-Hash 파티셔닝
- Range-List 파티셔닝
- Range-Range 파티셔닝
- List-Hash 파티셔닝
- List-List 파티셔닝
- List-Range 파티셔닝
Range 파티셔닝
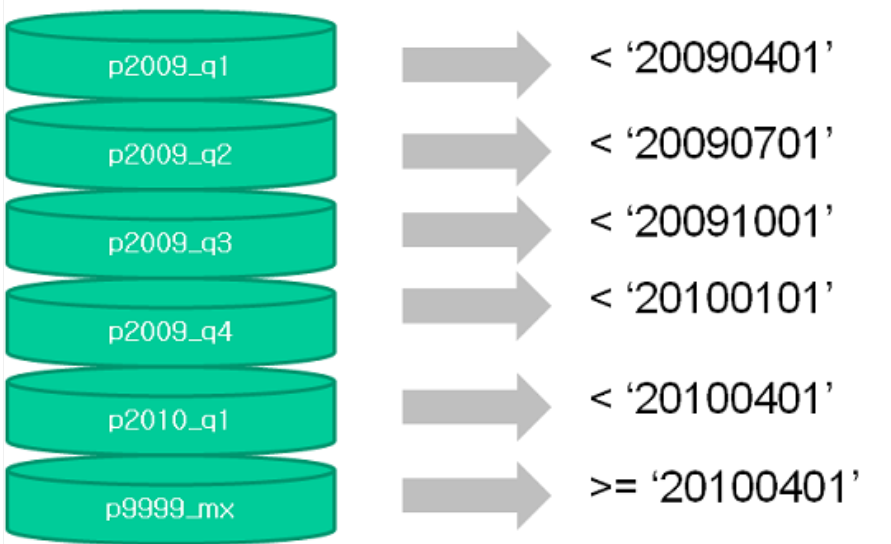
Range파티셔닝은 주로 날짜별로 범위를 지정하며, 맨 마지막 제약조건에는
MAXVLUE 를 필수로 지정한다.
왜냐하면 맨 마지막 범위를 넘어서는 데이터가 입력될떄, DB관리자가 실수로 신규 파티션을 생성하지 않았다면 데이터가 입력되지 않는다.
이를 방지하는 차원에서 마지막에 MAXVALUE를 지정한다.
Hash 파티셔닝
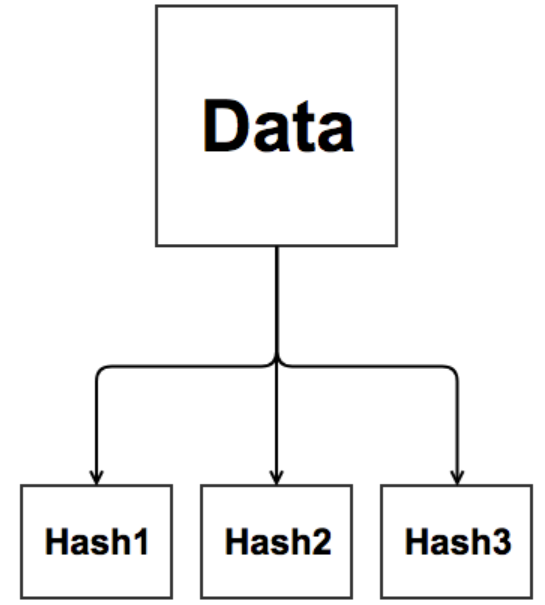
파티션 키에 해시함수를 적용해 결과값이 같은 레코드를 세그먼트에 넣어 분류하는 방식이다. 주로 고객ID처럼 변별력이 높고 데이터 분포가 고른 컬럼이 사용된다.
검색할땐 조건절 비교값에 해시함수를 적용해 읽어야할 파티션을 정하며,
해시함수 특성상 등치조건으로 적용된 조건일때만 활용된다.
대용량 테이블에 동시입력이 많을때는 경합을 줄일 목적으로도 해시 파티셔닝을 사용한다.
데이터가 입력될떄 테이블 블록에도 경합이 발생할 수 있지만, 그보다는 입력할 블록을 할당받기 위한 FreeList 조회 떄문에 세그먼트 헤더 블록에 대한 경합이 더 자주 발생한다. 이를 해시파티셔닝으로 극복할 수 있다.
Right Growing 인덱스도 맨 우측끝 블록에만 데이터가 입력되므로 경합이 발생한다. 이역시 인덱스 해시 파티셔닝으로 극복 가능하다.
List 파티셔닝
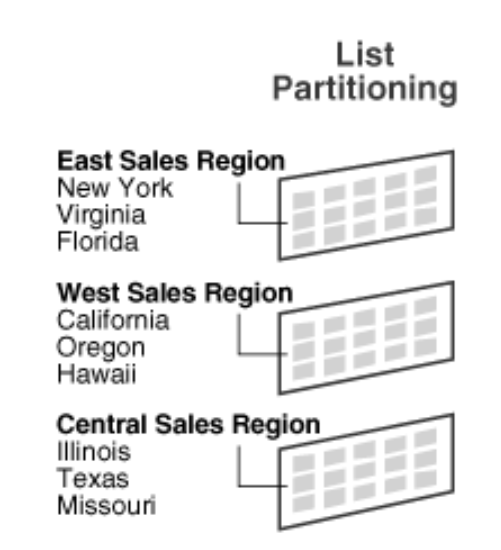
List 파티셔닝은 사용자가 미리 정해둔 그룹핑 기준(지역, 분류코드 등) 에 따라 데이터를 분할 저장한다.
Range 파티셔닝의 MAXVALUE와 같이 Lsit 파티셔닝에는 DEFAULT 파티션을 반드시 지정해 두어야 한다.
파티션 SQL조건절 작성 시 주의사항
create table 고객
partition by range(가입일)
( partition m01 values less than('20090201')
, partition m02 values less than('20090301')
, partition m03 values less than('20090401')
, partition m04 values less than('20090501')
, partition m05 values less than('20090601')
, partition m06 values less than('20090701')
, partition m07 values less than('20090801')
, partition m08 values less than('20090901')
, partition m09 values less than('20091001')
, partition m010 values less than('20091101')
, partition m011 values less than('20091201')
, partition m012 values less than('20100101'))
as
select rownum 고객 ID
...
.
.위와같이 고객 테이블을 생성하면서 range partitioning 하였다.
select * from 고객
where 가입일 like '200910%'이떄 위와같이 조회할때 9~10 파티션을 두개 읽는것을 확인할 수 있다.
왜 하나가 아닌 두개 파티션을 읽을까?
20091001 보다 작은 문자는 수없이 많다.
- ex) 200910, 20091000, 2009100+ 등
이떄 200910%같은 쿼리를 사용할때는 이들값까지 모두 결과집합에 포함 시켜야하므로 옵티마이저는 m09 파티션을 스캔하지 않을 수 없다,
따라서 위와같이 일자로써 파티션 키값을 정의했다면 아래오 같이 between 연산자를 이용해 정확한 값 범위를 주어야 한다.
select * from 고객
where 가입일 between '20091001' and '20091031'이때 비로소 하나의 파티션만을 읽는다.
반드시 기억하자 파티션 설계와 상관없이 옵티마이저가 효율적인 선택을 할 수 있도록 하려면 between 연산자를 사용하자
