인덱스를 활용하면 소트를 하지않는다.
인덱스는 컬럼 순서대로 정렬하고 있으므로 이를 잘 활용하면 소트 오퍼레이션을 건너뛸수 있다.
예제 1

emp 테이블에 sal 단일컬럼을 적용하는 인덱스를 미리 만들어 두었다.
이떄, 인덱스를 활용하면 order by를 제거할 수 있지 않을까?
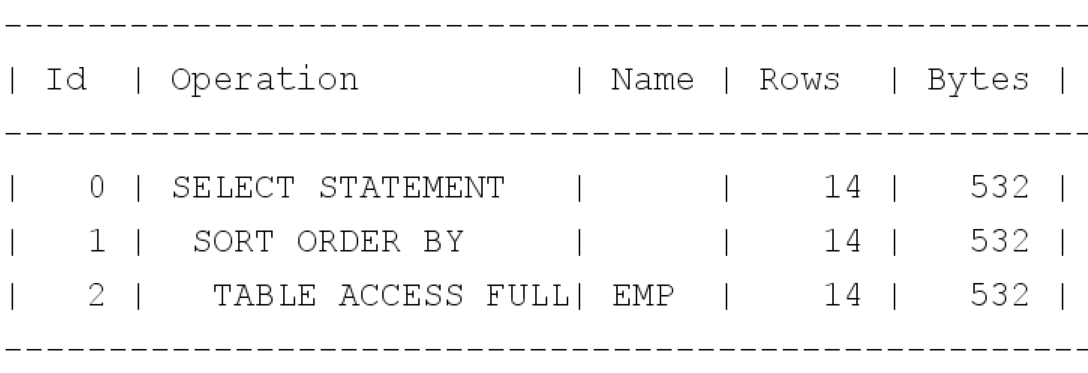
결과는 풀 테이블스캔 & 소트 오퍼레이션 발생이다.
이유는 옵티마이저가 인덱스를 경유하지 않는것이 더 낫다고 판단했기 때문이다.
힌트로 all_rows를 주었을떄, 전체 row를 feach하는 것을 기준으로 비용을 산정한다. 이를 근거로 풀스캔이 적용되어 소트 오퍼레이션이 적용되었다.

이번엔 first_rows로 적용된 쿼리이다.
하지만 그럼에도 풀스캔&소트오퍼레이션이 적용되었다.
이는 sal컬럼에 not null 제약이 해당되지 않아서 인데, 옵티마이저는 null이 허용되는 인덱스는 신뢰 할수 없다.
정렬을 없앤다면 결과집합에 변동이 있을수도 있다.

not null 제약을 설정하고 난 뒤 실행계획 이다.
인덱스를 경유하여 테이블 액세스를 하고 결과집합을 도출 하므로, 정렬작업은 생략할 수 있다.
예제 2
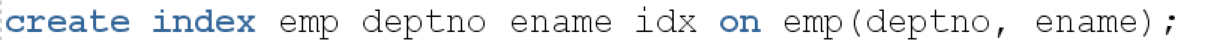
deptno, ename 의 결합 인덱스를 생성한다.


정상적으로 인덱스를 경유하고, 소트 오퍼레이션이 생략된 모습이다.

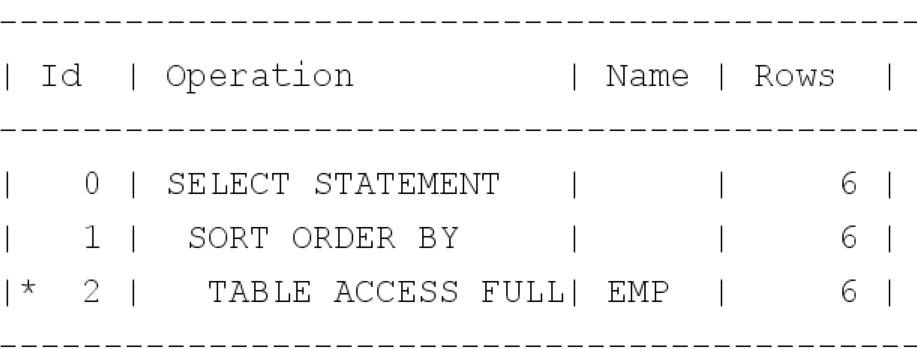
위처럼 nulls first 키워드를 사용할때 실행 계획이다.
단일 컬럼 인덱스는 null을 저장하지 않지만, 결합인덱스는 null값을 맨뒤쪽에 저장한다. 그러므로 nulls first 키워드를 사용했을땐, 정상적 인덱스 경유가 아니므로 소트 오퍼레이션이 생략되지 않는다.

🔥🔥🔥🔥 G U N F E 🔥🔥🔥🔥