
GPT LLM 구조 완벽 가이드: 개념부터 생성까지
GPT와 같은 대규모 언어 모델은 복잡해 보이지만, 실제로는 동일한 구조의 반복으로 이루어진 모듈식 아키텍처
1. LLM의 기본 구성 요소
- 파라미터(Parameter): 모델이 학습하며 조정하는 가중치(weight)입니다. 마치 요리할 때 소금, 고춧가루, 불의 세기를 조절하는 것과 같습니다. 파라미터가 많을수록 표현력은 좋아지지만, 계산 비용과 메모리 사용량도 함께 증가
- 처리 흐름: 1. 토큰화(Tokenization): 문장을 숫자(토큰) 단위로 분해
- 임베딩(Embedding): 각 토큰을 위치 정보가 포함된 고정 차원의 벡터로 변환
- 모델 주입: 벡터들이 여러 층의 트랜스포머 블록을 통과하며 다음 토큰을 예측
2. 활성화 함수와 정규화
모델이 복잡한 패턴을 학습하게 하려면 비선형성을 도입하는 것이 필수
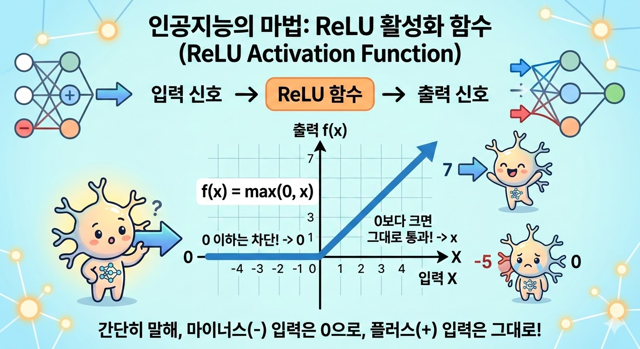
- ReLU: 0보다 작으면 0으로, 크면 그대로 통과. 빠르고 효율적이지만, 입력이 음수일 때 출력이 0으로 고정되는 '죽은 ReLU' 문제가 발생
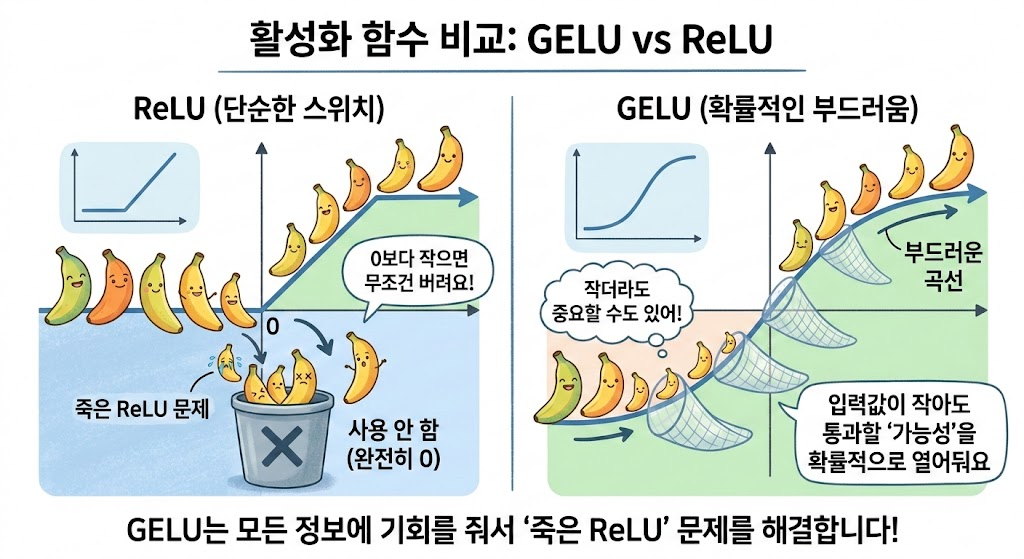
- GELU: ReLU의 개선판으로, 0 이하인 값도 부드러운 곡선으로 처리. 특정 정보가 중요할 가능성을 확률적으로 열어두어 학습 안정성
- 층 정규화(Layer Normalization): 각 층의 입력 평균과 분산을 조절하여 값들이 들쭉날쭉하지 않게 유지. 이를 통해 학습 속도를 높이고 모델을 안정화
3. 숏컷 연결 (Shortcut Connection)

깊은 네트워크에서 발생하는 그레디언트 소실(Gradient Vanishing) 문제를 해결하기 위한 핵심 기술
- 문제점: 역전파 과정에서 0보다 작은 값들이 여러 번 곱해지면, 앞쪽 층으로 갈수록 그레디언트가 거의 0이 되어 초기 레이어의 가중치가 업데이트되지 않음
- 해결책: 숏컷 연결은 레이어의 출력에 원래 입력을 더해줍니다. 이를 통해 최소한 1이라는 직접적인 경로를 확보하여 그레디언트가 깊은 층까지 안전하게 전달되도록 도움
4. 트랜스포머 블록과 모델 구조
GPT는 여러 개의 트랜스포머 블록(Decoder Block)이 쌓여 있는 구조로 각 블록 내에는 숏컷 연결을 포함한 다음과 같은 요소들이 포함
- 구성: 층 정규화 → 마스크드 멀티 헤드 어텐션 → 숏컷 → 층 정규화 → 피드포워드 네트워크 → 숏컷
- 드롭아웃(Dropout): 특정 뉴런을 무작위로 소거하여 모델이 특정 패턴에만 과하게 의존하는 '과적합'을 방지
5. 텍스트 생성 과정
모델은 한 번에 문장을 뱉어내는 것이 아니라, 한 단어씩 예측하며 생성
- 입력: 현재까지의 문맥이 모델에 입력
- 예측: 최종 층을 통과한 출력 벡터가 생성할 다음 토큰의 후보군
- 소프트맥스(Softmax): 벡터의 총합이 1이 되도록 변환하여 확률 분포를 생성
- 선택: 가장 확률이 높은 토큰을 선택하여 문장에 연결
- 반복: 새롭게 생성된 문자를 포함하여 다음 단어를 다시 예측

내 지식을 공유할 수 있는 대담함
nice!