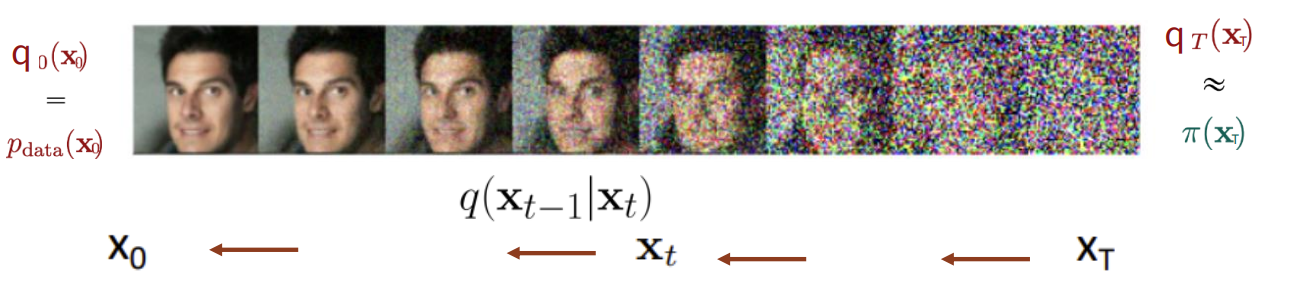x0 부터 xT 까지 점차 noise를 더해간다. x0는 perturbed 되지 않은 density를 가지며 pdata(x0) 와 같다. xT는 pure noise density를 가지며 π(xT)와 같다. 아래 그림의 q는 noise를 더하는 kernel 정도로 생각할 수 있다.
time step t는 이전 step에 의해서만 영향을 받으며 다음과 같은 관계식을 같는다.
따라서 특정 step t 에 대한 perturbed distribution을 얻기 위해 모든 noising process를 거치지 않아도 왼다.
Iterative Denosing
Denosing process는 noising process의 정확히 반대로 수행된다. xT를 π(xT)로 부터 sampling 하여 반복적으로 q(xt−1∣xt) 를 수행한다. 이때 문제는 q(xt−1∣xt) 가 unknown이라는 것이다. 따라서 이 문제를 해결하기 위해 q(xt−1∣xt) 에 대한 variational approximation을 수행한다.
q(xt−1∣xt)≈pθ(xt−1∣xt)를 modeling 한다. pθ(xt−1∣xt)=N(xt−1;μθ(xt,t)0,σ2I)를 만족하며, pθ로 부터 sampling을 반복한다. joint distribution은 pθ(x0:T)=p(xT)t=1∏Tpθ(xt−1∣xt)로 정의 된다.
Diffusion Model as a Hierarchical VAE
Diffusion model을 계층적 구조를 가진 VAE의 연속으로 볼 수 있다. noise를 더하는 과정을 encoder로 보고, de-nosing 과정을 decoder로 보면 VAE 형태가 된다. 이 때, VAE와 달리 encoder는 고정된 형태로 학습이 불가능하다.