1. Introduction
Efficient on-device neural networks는 빠르고 interactive한 neural networks 경험을 제공한다. 또한 private data를 public internet에 streaming 하는 것을 방지할 수 있다. 그러나 on-device의 computation constraint로 인해 model의 accuracy와 efficient 간의 trade-off가 발생한다.
이 논문에서는 UIB(Universal Inverted Bottleneck) block, Mobile MQA(Multi-Query Attention)을 제시하고, NAS를 통해 둘을 결합하여 mobile에 efficient한 nueral network인 MobileNetV4를 제시한다.
2 Hardware-Independent Pareto Efficient
Model performance의 주요 bottleneck은 hardware의 peak computational throughput과 peak memory bandwdith에 의해 computation bottleneck(compute bound)인지 memory access bottleneck(memory bound) 로 나뉜다.
Roofline model을 통해 hardwrare의 bottleneck이 memory bound인지 compute bound 인지 예측 할 수 있다.
Roofline model이란 고유한 하드웨어 제한과 최적화의 잠재적 이점 및 우선순위를 보여줌으로써 멀티 코어, 다수 코어 또는 가속기 프로세서 아키텍처에서 실행되는 특정 컴퓨팅 커널 또는 애플리케이션의 성능 추정치를 제공하는 데 사용되는 직관적인 시각적 성능 모델입니다. 출처 wiki
Roofline model을 만들기 위해 필요한 neural network inference latency는 다음과 같이 정의하였다.
- (연산시간)
- (데이터 전송 시간)
- : multiplier–accumulator
최대 performace를 달성하기 위해서는 최소한의 operational intensity가 요구된다. operational intensity는 memory bandwith 당 연산량으로 볼 수 있다.
Ridge Point Sweep Analysis
Ridge Point(RP) 란 "the ratio of a hardware’s PeakMACs to PeakMemBW" 를 말한다. CPU 같은 hardware의 경우 low-RP를 가지며, compute bound가 주요 bottleneck이 된다. 따라서 를 줄이는 것이 latency 감소에 도움이 된다. 반면 GPU 같은 hardware의 경우 high-RP를 가지며, memory bound가 주요 bottleneck이다. 따라서 model optimization(를 줄이는 것)이 큰 도움이 되지 않는다.
MobileNetV4 Design
논문의 저자는 MobileNetV4가 hardware에 independent한 pareto-optimal을 달성했다고 주장한다. 이를 위해 모델의 설계를 다음과 같이 진행하였다.
- beginning of network: low-RP에서 문제, high-RP에서는 문제 x
large and expansive layer
high number of - end of network: low-RP에서 문제 x, high-RP에서 문제
variatnts same size FC를 사용
FC layer가 크기 때문에 memory bandwidth가 커짐
3. Universal Inverted Bottlenecks
논문의 저자는 MobileNetV2에서 제시한 Inverted block의 개량판인 Universal inverted bottlenecks block(UIB block)을 제시한다.
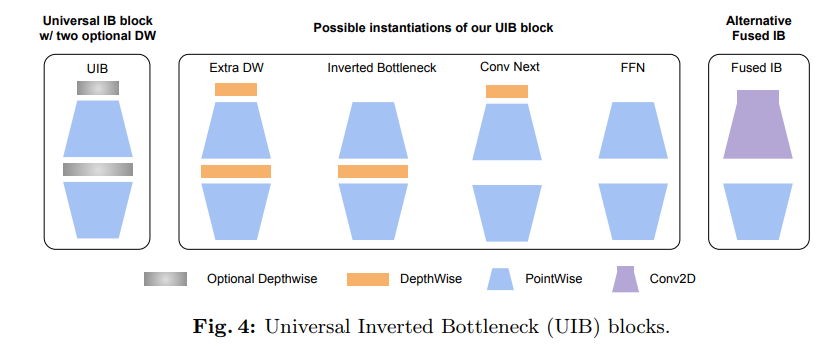
UIB block은 point wise conv의 input 부분과 사이에 optional depth wise conv를 두고, NAS를 통해 최적화된 block을 찾는다. 조합에 따라 총 4개의 variation이 발생 할 수 있다.
- Inverted Bottleneck(IB): expasion 이후 spatial mixing 수행
- ConvNext: expasion 이전에 spatial mxing 수행
- Extra D.W: IB + ConvNext 형태
- FFN: spatial mixing을 진행하지 않고, point wise conv만 수행
4. Mobile MQA
UIB block과 더불어 논문에서는 새로운 Mobile Multi Query Attention을 제시한다.
Importance of Operational Intensity
Mobile accelerator의 주요 bottlneck은 memory access에 의해 발생한다. 과거에는 연산 performance를 높히기 위해 arithmetic operation 시간을 줄이는데 집중했다. 그러나 bottleneck의 주요 원인이 mermory access이기 때문에 단순히 arithmetic operation 시간을 줄이는 것은 performance 향상으로 이어지지 않을 수 있다.(연산이 끝나도 다음 데이터의 전송이 되지 않기 때문) 따라서 논문의 저자는 arithmetic operation 시간을 줄이는 것 대신, memory access 당 arithmetic operations인 Operational Itensity를 높히는데 집중 하였다.
MQA is Efficient in Hybrid Models
Multi Query Attention(MQA)는 query가 key와 value를 공유하여 Multi Head Self Attention(MHSA)를 단순화 한다.(query는 여러개, key, value는 한 개인 구조)
MQA는 key, value의 head 수를 줄여 memory access를 감소시키기 때문에, operation intensity는 자연스럽게 증가한다.
Incorporate Asymmetric Spatial Down-Sampling
논문에서는 key와 value는 down sampling하고 query의 resolution은 유지하는 asymmetric spation down sampling을 사용하였다.
Mobile MQA는 다음과 같이 표현 가능하다.
은 spatial reduction(2 strides D.W)
5. Design of MNv4 Models
Our Design Philosohy: Simplicity Meets Efficiency
실험을 통해 논문의 저자들은 다음과 같은 사실을 밝혀냈다.
- Multi path efficiency concerns
group conv와 같은 multi path 방식의 design들은 memory access complexity로 인해 낮은 efficiency를 보임 - Hardware supports matters
Squeeze and Excite(SE) module, GELU, LayerNorm은 DSP에서 지원이 되지 않는다. - The power of simplicity
D.W나 point wise conv, ReLU, BatchNorm, simple Attention 같은 기본적인 component들이 efficient 함
위와 같은 발견을 통해 논문의 저자들은 다음의 design principle을 세웠다.
- Standard component를 사용
- Flexible UIB 사용
- Straitforward Attention 사용
Refining NAS for Enhanced Architecture
UIB block을 결정하기 위해 refinining을 진행한 TuNAS를 이용하였다.
- two stage search
TuNAS의 small filter와 expansion factor에 대한 bias를 조정 -> two stage search 진행
1. coarse-grained search
parameter 수를 고정하고 filter size optimization. inverted bottleneck block의 expansion factor를 4로, 3x3 D.W로 고정.
2. fine-grained search
UIB의 D.W를 optimization.
6. Conclusion
이전 경량화 모델에 대한 논문들은 주로 모델의 연산량을 줄이는데 집중하는 경향을 보였다. 그러나 최근 Deep Learning 모델의 주요 bottleneck은 연산량 보다는 memory bandwidth에 의해 발생한다. MobileNetV4에서는 이러한 점을 지적하며, 그에 맞는 모델 architecture를 제시했다는 점에서 신선한 것 같다.
Reference
