1 Introduction
서비스 관점에서 효과적이고 유용한 application을 만들기 위해 LLM은 long sequence generation을 수행할 수 있어야한다. 그러나 현재 LLM은 pre-trained 과정에서 설정된 input token length 이상의 sequence를 generation 하는데 어려움을 겪는다. 따라서 infinite input stream에 대해서 현존 LLM이 대응하기 어렵고 이로인해 서비스의 질이 낮아진다.
논문에서는 infinite input stream에 대응할 때의 challenge로 두 가지를 선정했다.
- 1) memory usage
LLM은 input 처리 시, attention에 사용되는 key, value를 cahe로 저장한다. input이 infinite stream 형태라면 cache size가 지속적으로 증가하는 문제가 발생한다. - 2) attention window size
pre-trained 과정에서 설정한 input token length를 attention window라고 부른다. 이를 넘어선 input을 받았을 때, LLM은 performance가 저하된다.
이에대한 직관적인 해결법은 window attention을 사용하는 것이다. window attention은 모든 key, value를 이용하는 것이 아니라 Query의 인접 token 만을 고정된 크기로 이용하는 것이다. window attention은 사용하는 key, value가 고정되어 있어 maximum memory size를 보장하지만, input sequence length가 window size를 넘어가는 순간 성능이 크게 저하된다.
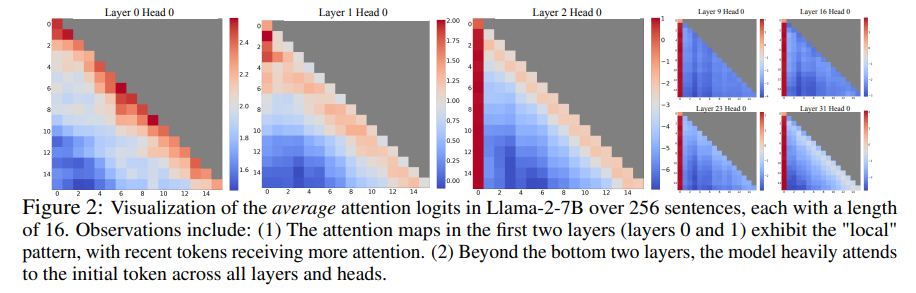
논문의 저자들은 실험을 통해 흥미로운 현상을 발견하였다. attention 연산 과정에서 발생하는 attention score 중 대부분을 초기 몇 개의 token이 차지한다는 점이다. 때문에 input length가 길어지면 초기 token이 제거되는 window attention은 성능이 떨어지게된다. 초기 token을 유지하기 위해 매번 re-compute를 하며 window attention을 진행하면 연산량이 매우 증가하여 서비스에 적합하지 않다. 논문에서는 초기 몇 개의 token들을 attention sinks라고 부르며 attention sink들을 유지하면서 최근 몇 개의 token들만 사용하는 StreamingLLM을 제시했다.
2. StreamingLLM
The Failure of Window Attention and Attention Sinks
앞서 설명한 것 처럼 window attention은 input sequence length가 window size를 넘어서면 초기 token들이 사라지기 때문에 성능이 크게 저하된다. attention은 softmax 연산을 통해 attention score를 구하게 되는데 softmax의 특성상 값의 대부분을 차지하는 초기 token이 사라지면 attention score의 distribution이 달라지기 때문이다.
논문에서는 초기 token들의 attention score가 높은 이유에 대해 두 가지 가설을 세우고 실험을 진행했다.
- 1) 초기 token들에 중요한 semantice information이 담겨 있다.
- 2) 모델이 학습 할 때 초기 token들의 attention score가 높게 되도록 bias 된다.
논문에서는 문장의 처음 4 단어를 linebreak toekn \n으로 설정한 후 모델의 attention score를 관찰하였다. 만약 가설 1)이 맞다면 \n의 attention score 값이 낮아야 하지만 여전히 높은 값을 유지하였다. 이를 통해 초기 token들의 attention score가 높은 이유는 semantice한 의미가 담겨 있기 때문이 아닌 absolute position 으로 인해 attention score가 높은 것을 확인 할 수 있다.

논문의 저자는 초기 token들이 의미있는 내용을 담지 않더라도 attention score가 높은 이유를 softmax의 성질 때문이라고 설명한다. 위의 softmax 함수를 살펴보면 softmax는 output 확률의 합이 1이 되도록하기 위해 모든 요소의 값이 0이 되는 것을 방지한다. 따라서 self attention 연산 시 현재 Query 단어가 충분한 정보를 가지고 있을 때도 다른 단어와의 attention score가 충분히 주어져야 하고(sink), 이러한 역할을 하는 것을 초기 token들이 담당한다고 설명한다.
초기 token들이 sink 역할을 하는 것에 대해서 논문의 저자는 초기 token의 이후 등장하는 모든 token들을 볼 수 있기 때문이라고 설명한다. auto-regressive 성질로 인해 초기 token들은 자연스럽게 이후 등장하는 모든 token 연산에 참여하게 된다. 때문에 초기 token들이 sink 역할을 하기에 적합하다고 설명한다.
Rolling KVCache with Attention Sinks
일반적으로 LLM은 inference 과정에서 KV cache를 사용한다. StreamingLLM에서 KV cache는 크게 두 과정으로 나눌 수 있다.
- 1) Attention sinks(inital tokens) 유지
- 2) Recent tokens rolling
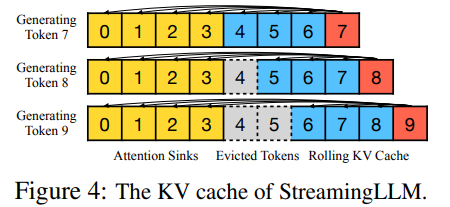
위 figure 4 처럼, attention sinks들은 항상 유지를 하고, 중간에 recent cache size를 넘어서는 token들을 버리고 새로운 token들을 caching하는, rolling 과정을 거친다. 이때 StreamingLLM은 caching된 data를 기준으로 relative position embedding을 다시 수행한다. 예를 들어 token 9을 생성하는 단계에서 caching된 데이터의 실제 position id는 [0, 1, 2, 3, 6, 7, 8] 이지만, [0, 1, 2, 3, 4, 5, 6, 7]을 가지고 relative position embedding을 사용한다. RoPE(Rotary Poisitonal Embedding)을 사용한다면, cache 이후 RoPE를 적용하는 방식으로 StreamingLLM을 구현할 수 있다.
Pre Training LLMs with Attention Sinks
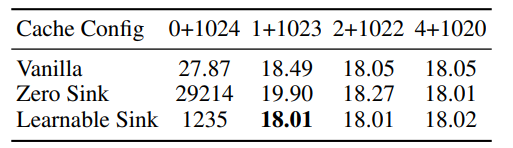
논문의 저자는 초기 token들이 attention sinks 역할을 하기 때문에 score가 높게 나타난다고 주장했다. 이때 한 개가 아닌 여러개의 token이 sink 역할을 수행한다. 이를 논문에서는 pre-train 과정에서 문장의 첫 token이 일정하지 않기 때문에 여러 token이 sink 역할을 수행한다고 주장한다. 이에 pre training 과정에서 sink 역할을 하는 token을 추가해 학습하면, 한 개의 sink token 만으로도 충분할 것이라는 가설을 세우고 실험을 진행했다. sink 역할을 하는 token을 learnable sink라고 불렀고, learnable sink를 사용해 학습한 결과, 한 개의 sink token으로도 4 개를 사용한 것과 비슷한 수준의 성능을 얻을 수 있었다. (비교군인 zero-sink는 softmax를 개량한 버전)
3. Experiments
Language Modeling on Long Texts across LLM Families and Scales
PG19 test dataset을 모두 concat 하고 model의 perplexity를 측정하였다.
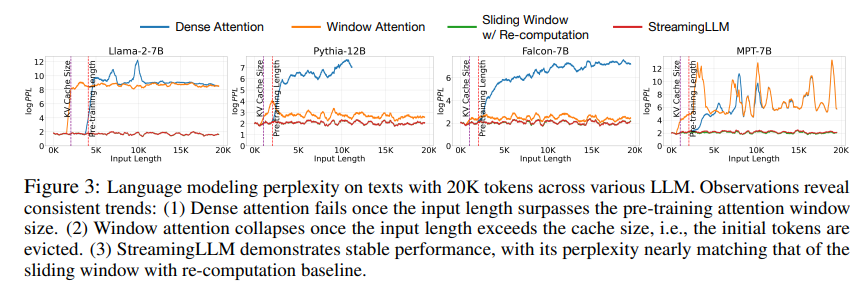
Dense attention의 경우 pre-tranied length를 넘어서면 성능이 저하되었고, window attention의 경우 cache size를 넘어서면 성능이 하락하였다. 반면 Streaming LLM의 경우 지속적으로 성능을 유지한 것을 확인 할 수 있다.
Result of Pre-training with a Sink Token

Sink token을 모든 학습 문장의 맨 앞에 추가해도 loss는 이전과 유사하게 감소하는 것을 확인할 수 있다. chapter 2에서 본 표에서 알 수 있듯이 sink token을 가지고 학습한 결과 한 개의 sink token만 가지고도 4개의 sink token을 사용하는 것과 유사한 결과를 얻었다. attention map을 시각화 한 결과 sink token에 지속적으로 concetration 하는 것을 확인 할 수 있다.

Results on Streaming Question Answering with Instruction-tuned Models.
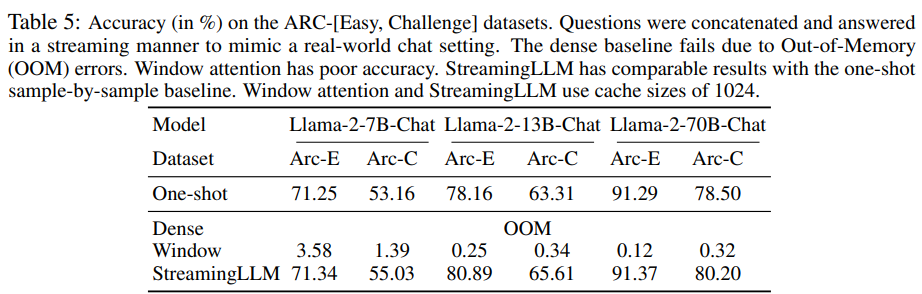
ARC dataset의 모든 question과 answer를 concat한 후 streaming 방식으로 forwarding 하여 accuracy를 측정하였다. 기존 dense attention은 OOM이 발생해 평가를 할 수 없었고, window attention 방식에 비해 Streaming LLM의 accuracy가 압도적으로 높았다.
Ablation Studies
Numbers of Initial Tokens

1~2 개의 initial token을 가지고는 완벽하게 ppl을 복원 하지 못했다. 실험적으로 4 개의 token을 사용하는 것이 가장 효율적이라는 것을 밝혔다.
Cache Size
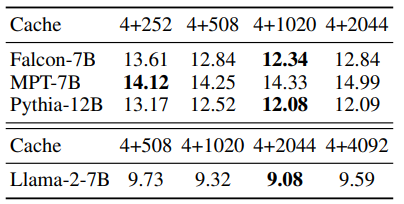
rolling 되는 cache size를 증가 시켜도 ppl이 지속적으로 낮아지지는 않았다. 이를 통해 model이 input 전체를 이용하지 않는 다는 것을 유추할 수 있다.
Efficient Results

Streaming LLM은 cache size가 증가 할 수록 decode latency가 linear하게 증가하는 반면, window attention with re-compute는 cache size가 증가 할 수록 quadratic 하게 latency가 증가하는 것을 확인 할 수 있었다.
4. Conclusion
Streaming LLM은 KV cache 크기를 고정시킬 수 있다는 점에서 LLM service를 고려하고 있다면 무조건 활용할 수 밖에 없는 기술인 것 같다. 다만 initial token 몇개와 최근 token들만 가지고 성능을 낼 수 있다는 점은 다소 직관적이지 않아 후속 연구가 더 진행되어야 할 것 같다. 또한 streaming input을 처리하면서 token들을 삭제하는 과정이 있기 때문에 과거 기억을 잃어버리는 것에 대한 보완이 필요하다.
Reference
