1. Introduction
Large Language Model(LLM)은 다양한 Natural Language Process(NLP) benchmark에서 인상적인 performance를 보여주었다. 그러나 LLM이 많은 computation과 memory를 요구하기 때문에 LLM을 real world application에 활용하는데 제약이 걸린다. 이를 해결하고자 quantization 방법이 주로 많이 사용된다. LLM의 규모를 고려했을 때 많은 training resource가 필요한 Quantization Aware Training(QAT) 방식보다 Post Training Quantization(PTQ) 방식이 qunatization 방식으로 주로 활용된다.
이전 PTQ 기반의 LLM quantization은 W4A16(Weight 4bit, Activation 16bit), W8A8 환경에서 꽤 좋은 성능을 보여주었다. 그러나 더 low-bit quantization의 경우(W2A16, W4A4) 심각한 성능의 저하가 발생한다. 논문에서는 이전 method 들이 hand-craft quantization parameter를 사용했기 때문에 성능의 저하가 발생한다고 주장한다.
따라서 논문의 저자는 OmniQuant라는 새로운 quantization 방식을 제시한다. OmniQuant는 quantization parameter를 learnable parameter로 바꾸어 학습을 통해 quantization parameter를 결정한다.
2. OmniQuant
Challenge of LLM Quantization
논문에서는 LLM quantization의 challenge로 두 가지를 언급한다.
- Activation Outlier Channel
model의 규모가 커지면서 특정 activation channel의 outlier 값이 발생한다. 이는 quantization을 어렵게 만든다. - Weights Quantization Error
weight가 activation에 대응되기 때문에 weight quantization error 역시 LLM에서 중요한 문제이다.
이전의 연구들은 위 challenge들을 해결하기 위해 hand-craft parameter를 도입했고 어느 정도 성공을 거두었다. 그러나 4bit 같이 extreme한 환경에서는 성능이 크게 떨어진다.
따라서 논문에서는 quantization parameter를 학습을 통해 결정하는 방식을 제안한다. weight quantization clipping strength를 학습하는 Learnable Weight Clipping(LWC), activation outlier를 조절하는 Learnable Equivalent Transformation(LET)를 제안한다. 그리고 LLM을 transformer block 단위로 학습하는 Block-wise Quantization Error Minimization 방식을 제시한다.
Block-wise Quantization Error Minimization
LLM의 모든 parameter에 대한 학습을 진행하면 search space가 커지기 때문에 optimize 하기 어려워 진다. 따라서 OmniQuant에서는 quantization parameter를 transformer block 단위로 학습을 진행한다.
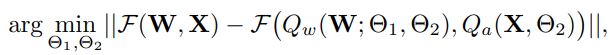
: Transformer block mapping function (transformer block의 output을 반환)
: Weight와 activation의 quantization function
: LWC parameter
: LET parameter
Block-wise quantization error minimization을 통해 LWC와 LET의 parameter를 jointly optimization이 가능하고 최소한의 resource를 가지고 optimization 진행이 가능하다.
Learnable Weight Clipping(LWC)
Weight quantization clipping threshold를 직접 학습하는 이전 방식들과 달리 min과 max 값의 정도를 조절하는 clipping strength를 학습한다.
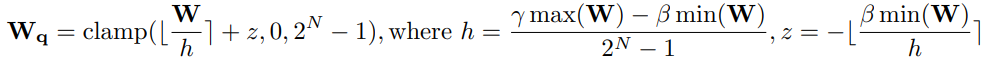
: Roud funcion (반올림)
: Target bit number
: Normalize factor
: Zero point value
: Clipping Strength (learnable parameter, )
Learnable parameter 는 0~1 사이의 값을 가지기 위해 sigmoid function으로 구현되었다.
Learnable Equivalent Transformation
Activation channel의 outlier는 clipping range를 크게 만들어 intermediate value의 information loss를 발생시킨다. SmoothQuant 같은 기법은 activation과 weight의 equivalent transformation을 통해 activation의 quantization 난이도를 크게 낮추고 weight의 quantization 난이도를 조금 상승 시킨다. 이때, hand-craft equivalent parameter를 사용한다.
LET에서는 이 parameter를 학습을 통해 결정한다. linear layer에만 equivalent transformation을 적용한 것과 달리 LET는 attention operation에도 equivalent transformation을 적용한다.
Linear layer
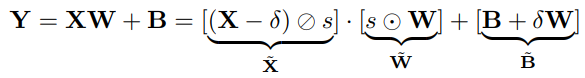
: Channel wise scaling parameter,
: Channel wise shifting parameter,
: Element wise divide, multiplication
: Equivalent activation, weight, bias
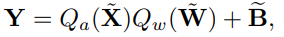
: Vanila Min Max quantization
: LWC quantization
의 shifting, scaling factor는 이전 normalization, linear layer에 통합이 가능하다. 또한 의 scaling factor는 origin weight 에 통합이 가능하다.
논문에서는 FFN의 두 번째 linear layer를 제외한 모든 linear layer에 대해 위와 같은 quantization을 적용하였다. 두 번째 linear layer를 제거한 이유는 non-linear layer이후에 feature가 sparse 해지기 때문이다.
Attention operation
LLM의 attention은 /를 가지고 있어야 하기 때문에 substantial memory가 필요하다. 그렇기 때문에 논문에서는 //를 low-bit으로 qunatization 하였다.
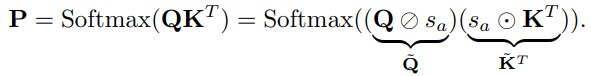
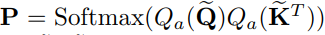
Attention의 quantization function으로 Min Max quantization을 사용하였으며 의 parameter 는 projection layer의 weight에 통합 할 수 있다.
는 output projection linear layer의 inverse transformation에 의해 변경되기 때문에 따로 수식을 명시하지 않았다.
3. Experiments
Weight Only Quantization Results
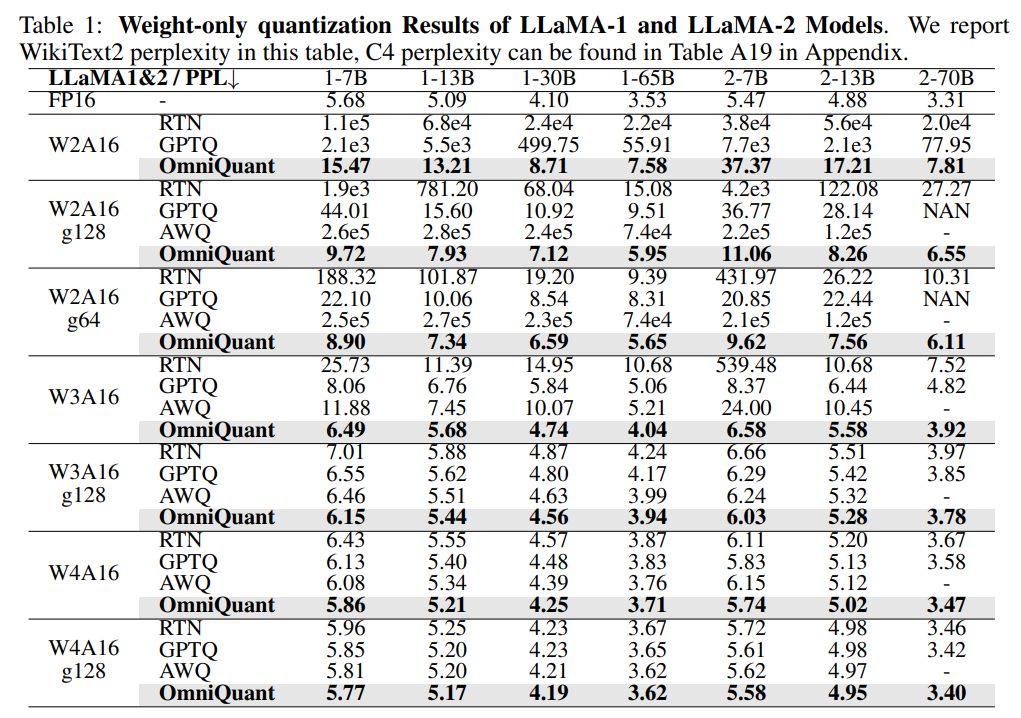
- g : group wise weight quantization
OmniQuant를 가지고 weight only quantization을 진행한 결과 이전 모델들에 비해 성능이 높았고, 특히 low-bit으로 갈 수록 좋은 성능을 보여주었다. 또한 group wise, channel wise 모두에서 좋은 결과를 보여 OmniQuant가 다양한 환경에서 좋은 성능을 낼 수 있다는 것을 보였다.
Weight Activation Quantization Results
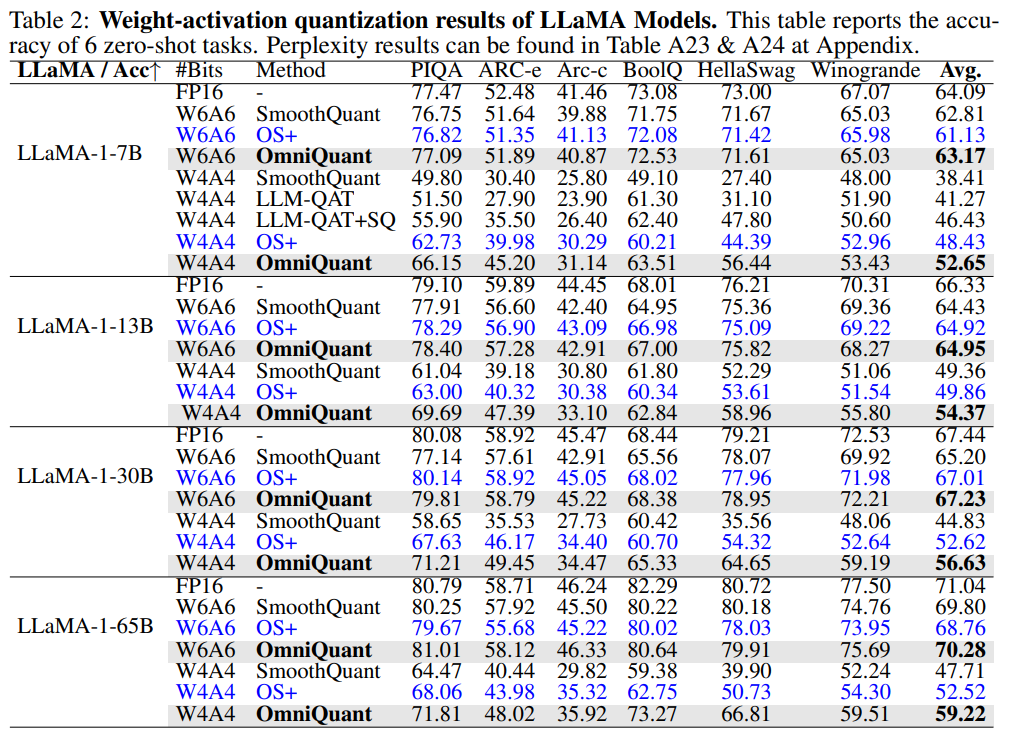
Weight activation quantization 역시 이전 method들 보다 더 좋은 성능을 보여주었다. 주목할 만한 점은 OmniQuant가 QAT 보다 더 좋은 성능을 보였다는 점이다.
Quantization of Instruction-Tuned Models

Chatbot test에 대한 quantization 성능 평가를 진행하였다. LLaMA-2-7b-chat에 대해 OmniQuant가 RTN 보다 압도적인 승률을 보였고, AWQ와는 동률을 보였다. 반면 LLaMA-2-13b-chat에 대해서는 둘다 약간 우세인 승률을 기록하였다.
4. Conclusion
기존 LLM의 quantization에 사용하던 parameter들을 learnable parameter로 바꾼 아이디어를 제시한 논문이다. 논문에서 언급한대로 W8A8 같이 일반적 case의 quantization은 기존에도 어느정도 좋은 성과를 보이고 OmniQuant도 이와 크게 다른 성능을 보이지는 않는다. 다만 극단적으로 low bit으로 가는 경우 기존 방법들에 비해 훨씬 좋은 성능을 보여준다. 그러나 real world application에서 이 정도 극단적 환경에서 LLM을 돌릴 경우가 많을지 의문이며 training 시간이 추가로 발생한다는 점이 단점으로 생각된다. 기존 method 들을 적용했을 때 원하는 만큼의 성능이 나오지 않은 경우 한번 적용해볼만 할 것 같다.
Reference
