1. Introduction
NLP task에서 pre-training task agnostic models은 일반적이다. 최근 LLM들은 pre-training task에 상관없이 비교적 적은 수의 samples로 downstream task에 대해 좋은 성능을 보인다. 이 논문은 NLP가 아닌 Image domain에서도 이러한 trend가 통하는지 실험한다.
LLM과 유사하게 하기 위해 ViT를 이용하여 autoregressive objective pre-training을 수행하는 모델인 Autoregressive Image Model(AIM)을 제시한다.
2. Pre-training Dataset
논문에서는 DFN dataset(12.8B images)을 base로 pre-training을 진행한다. DFN dataset은 image와 caption pair로 구성되어 있는데 alignment score를 통해 2B images를 sampling 한 dataset을 DFN-2B라고 한다. LLM pre-training에서 일반적으로 high-quality data를 oversampling 하여 pre-training을 진행한다. 이와 비슷하게 논문에서는 DFN-2B에서 0.8 비율로 sampling하고 ImageNet Dataset에서 나머지 0.2를 sampling 한 dataset DFN-2B+를 만들었다. 논문의 대부분 모델은 DFN-2B+로 pre-training을 진행하였다.
3. Approach
Training Objective
Image 를 개의 non-overlap patches로 나누고 sequence of image patches에 대해 autoregressive objective를 적용한다. patches의 order는 raster ordering을 따른다.
이에 따른 image probability는 다음과 같이 정의 된다.
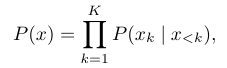
: patch number
: image patch
: first patches
Training loss는 NLL(Negative Log-Likelihood)로 정의할 수 있다.
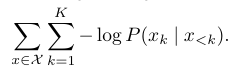
Prediction Loss
위 training loss는 의 정의에 따라 다양하게 결정된다. 논문에서는 sum l2 norm squared distance를 minmize 하였다. 이는 를 constant variance를 가진 Gaussian distribution으로 정의한 것과 동일하다.
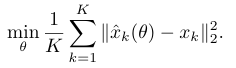
: prediction of th patch
Architecture
AIM의 전체 architecture는 다음과 같다.
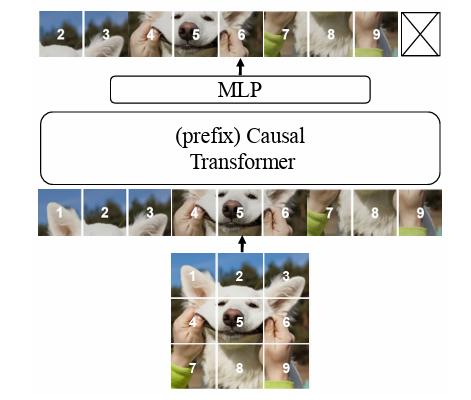
ViT를 기반으로 AIM을 구축하였고 model capacity에 대한 scaling은 model의 width를 확장하였다. 이는 LLM과 유사하다.
Pre-training 과정에서 self-attention layer에 대해 casual mask를 적용하였다. 이를 통해 patch는 자신보다 이후에 등장하는 patch를 참고하지 못하고 attention 연산이 수행된다.(일반적 Transformer의 mask와 동일)
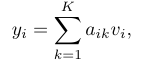
: attention weight
: value embedding
위 식에서 는 인 값에 대해 모두 0을 가지게 하여 casual mask를 적용한 효과를 내었고 로 설정하였다.(일반적인 Attention 연산과 동일)
Prefix Transformer
Downstream task에서 ViT 모델은 주로 bidirectional self-attention을 필요로한다. 이는 autoregressive objective에서 casual mask를 사용하는 것과 다르기 때문에 downstream task에서의 performance를 저하시킨다. 따라서 논문에서는 Prefix Transformer를 제시한다.
Prefix Transformer는 patch의 일정 앞부분을 prefix로 간주하고, 이 부분에 대해서는 casual mask를 적용하지 않는다. 그리고 autoregressive prediction에서 prefix는 제외된다.
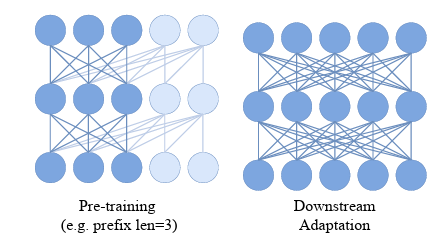
Prefix length 이 주어지면 인 에 대해 0을 할당하지 않는 방식으로 casual mask를 제거한다.
MLP Prediction Head
Pre-training model의 head는 feature가 pre-training task에 over specialize 되는 것을 방지한다. downstream task에 대해 head가 제거되고 task에 맞는 head를 구성하여 새롭게 학습하는 방식을 통해 downstream task에 대한 suitability를 향상 시킨다.
논문에서는 patch를 independently process하는 MLP block을 개를 쌓아 head를 구성하였다.
Straitforward Implementation
AIM은 stochasitc-depth, QK-Norm과 같은 particular optimization stability inducing mechanism을 사용하지 않았다.
Downstream Adaptation
Pre-training head는 각 patch에 대해 독립적으로 loss를 계산한다. AIM은 global image token도 사용하지 않기 때문에 global image 정보는 거의 얻지 못한다. classification 같은 downstream task는 global image description이 필요하므로 논문에서는 global descriptor로 attention pooling을 이용하였다. 논문에서는 attention pooling을 Attentive Probe라고 부른다.
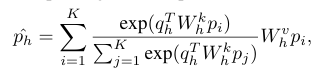
: global pooled feature
: patch feature
: key, value weight matrix
: attention head (
: learnable query vector
4. Results
Impact of Scaling
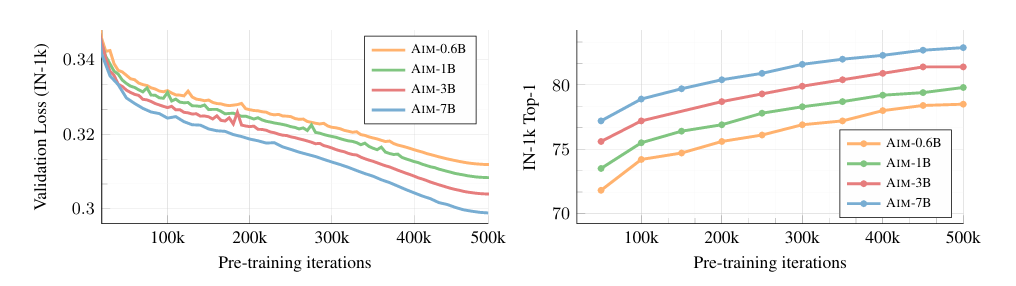
- Autoregressive objective를 optimization 하는 것이 downstream task performance 향상으로 이어짐
- Model의 capacity(parameter)가 증가하는 것이 downstream task performance 향상으로 이어짐
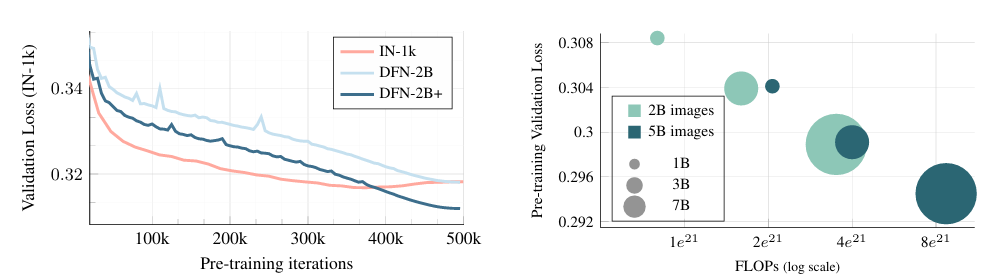
- Small dataset(IN-1k)에서는 overfitting이 발생, large dataset에 대해서는 overfitting 현상 없이 downstream task performance 향상
- Long train iteration이 performance 향상으로 이어짐
Architecture and Design
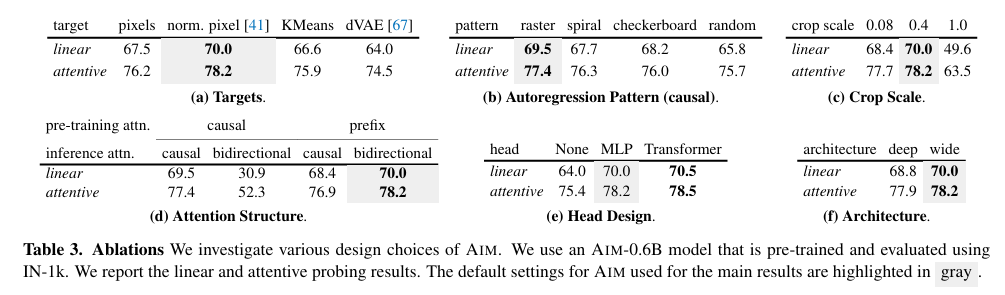
-
(a) Targets and Objective
Naive MSE(pixels) 방식의 loss와 normalizing image에 대한 MSE(norm. pixel), Cross-entropy(KMeans, dVAE) 방식의 loss를 비교한 결과 normalizing image에 대한 MSE가 가장 성능이 좋음 -
(b) Autoregressive Pattern
Image의 경우 traveral pattern이 불분명(patch의 순서를 결정하기 어려움)하기 때문에 다양한 pattern에 대해 실험 진행
실험 결과 raster ordering 방식이 가장 성능이 좋음 -
(c) Cropping Scaling
적절한 scaling 값으로 cropping 하는 것이 좋음 -
(d) Casual vs Prefix
Prefix 방식이 downstream task performance가 더 좋음 -
(e) Head design
Head를 Transformer로 구성했을 때 성능이 가장 좋지만 연산량이 너무 많아짐
따라서 MLP head를 추천함 -
(f) Deeper vs Wider
Wide 방식으로 scaling 하는 것이 더 성능이 좋음 -
모든 경우에 attentive probe의 global descriptor를 썼을 때 성능이 더 좋음
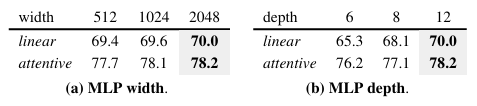
-
MLP head의 경우 depth가 깊어지는 것이 성능 향상 폭이 더 큼
Pre-training Objective
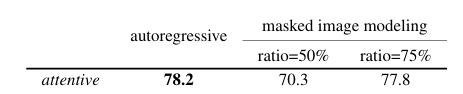
- AIM을 masked image modeling 방식으로 pre-training 하는 것 보다 autoregressive 방식으로 pre-training 하는 것이 더 좋음
Comparison with Other Methods
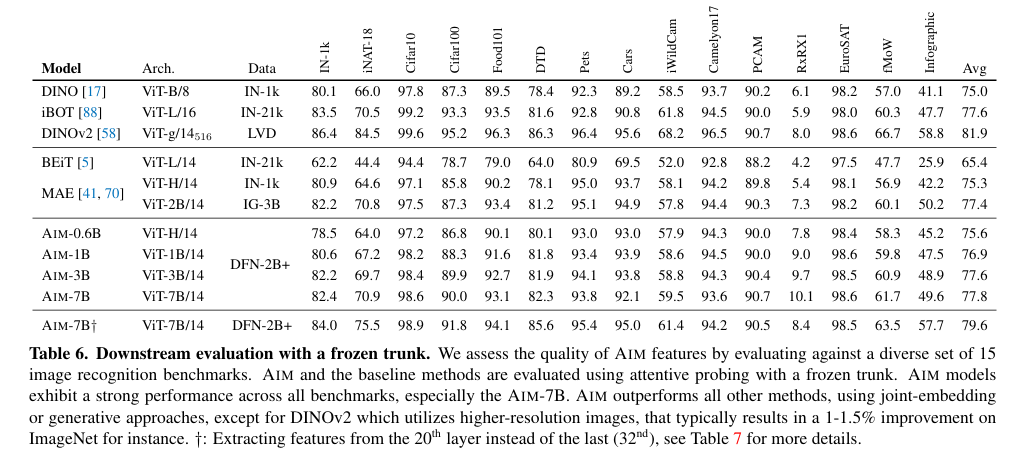
- MAE, BEiT 같은 generative methods(masked modeling) 방식의 모델 보다 성능이 우수
- DINOv2, iBOT 같은 Contrastive methods와 비슷한 수준의 성능을 보임. 그러나 AIM의 training 과정이 더 simple
5. Conclusion
AIM은 image domain의 BERT라고 생각한다. autoregressive 방식으로 pre-training을 진행하였고, LLM 처럼 모델 및 데이터의 scaling에 따라 performace가 올라가는 것을 보여주었다. DINOv2와 비교하면 performace가 다소 떨어지는데, 논문에서는 DINOv2가 다양한 training trick을 적용했기 때문이라 말한다. 이러한 trick들이 AIM에도 적용 됐을때 DINOv2를 넘을 수 있을지 궁금하다. 그리고 downstream task로 classification performace 만을 측정하였는데 다른 task에 대해서도 비슷한 양상을 보일지 궁금하다. 만약 다른 task에 대해서도 비슷한 양상을 보인다면 image task의 foundation model이 될수 있을 것 같다.
Reference
