
모든 데이터셋에 적합한 접근방법은 존재하지 않는다.
어떤 접근방법은 특정 데이터셋에 최상의 결과를 제공하지만,그 밖의 어떤 접근방법은 다른 데이터셋에서 더 잘 작동한다.
주어진 데이터셋에 가장 적합한 Method는 어떻게 찾을 수 있을까?
달리 말하면, 여러 Method를 어떻게 비교할 수 있을까?
Measuring the Quality of Fit
주어진 데이터셋 기반의 통계적 학습방법의 성능을 측정한다.
regression problem에서, 가장 보편적인 예측 정확도 측정 방법은 평균 제곱 오차(MSE)다.
우리는 MSE가 가장 작은 모델을 선택하면 된다.
Training MSE와 test MSE
training MSE와 test MSE는 다르다.
training MSE는 학습에 사용된 데이터셋으로 측정한 MSE로 최소화하기가 쉽다.
test MSE는 학습에 사용되지 않은 데이터로 측정한 MSE로 우리가 실질적으로 최소화해야하는 값이다.
적절한 모델을 찾기 위해선 test MSE로 결정해야한다.
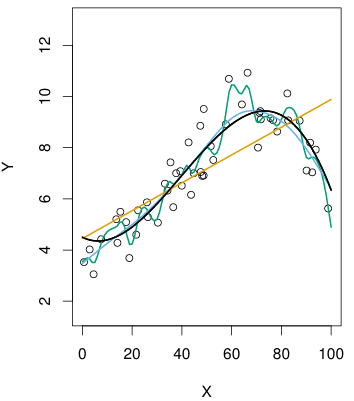
검은색 선: 실제
주황색, 파란색, 초록색 선: flexibility를 증가하면서 추정한
주황색선은 linear regression이다.
여기서 기존의 데이터셋을 가장 잘 예측하는 선은 초록색선이지만, 실질적으로 를 가장 잘 예측한 것은 파란색이다.
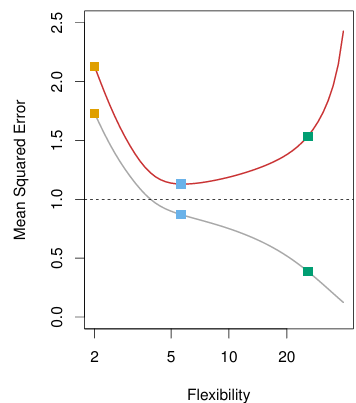
빨간색 선은 test MSE이고, 회색 선은 training MSE일 때, Flexibility가 증가할 수록 test MSE와 training MSE간의 차이가 커지는 것을 알 수 있다.
여기서 주황색 점, 파란색 점, 초록색 점은 위에서 설명한 방법 세가지(주황색:linear regression, 파란색, 와 가장 fit한 예측, 초록색:현재 데이터셋과 가장 일치하는 예측)이다.
- Method가 더 flexible 할 수록 training MSE는 더 감소한다.
- 그러나 더 flexible 할 수록 test MSE는 더 증가한다.
*flexibility를 파란색 점과 같이 최적인 지점을 잘 찾아 "OVERFITTING"을 피해야한다.
예시
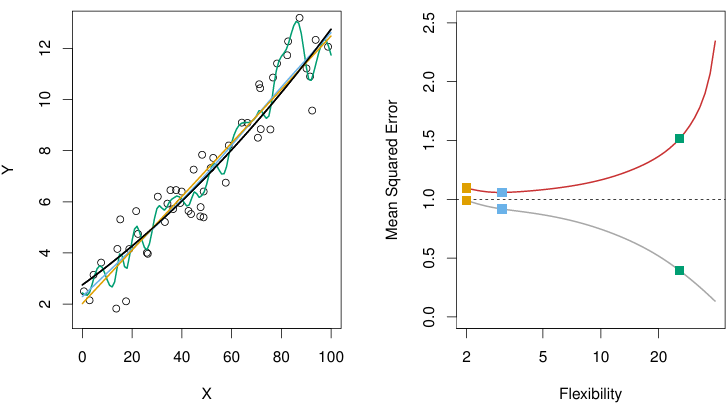
가 선형방정식과 유사한 경우에 flexibility에 따른 train MSE와 test MSE의 경향성
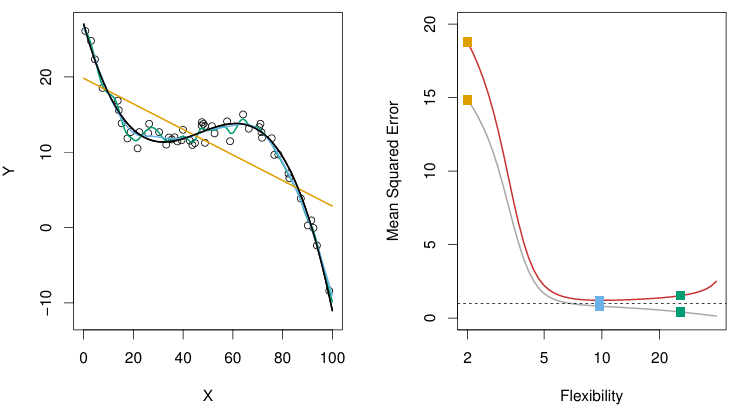
가 좀 더 복잡한 경우에 flexibility에 따른 train MSE와 test MSE의 경향성
U-Shape
앞선 예시를 보면 가 어떻게 생겼던 간에, test MSE는 U-Shape을 띈다.
이상과 현실
*MSE를 분해해보면
*하지만, test MSE는 이렇게 만들어진다.
는 새롭게 주어진 데이터이고, 는 새로운 데이터로 측정한 의 Variance, 는 새로운 데이터로 측정한 의 Bias이다.
Bias
Bias란 실제 값과 모델간의 간격이다.
더 flexible한 모델일 수록 bias는 점점 더 떨어진다. 더 flexible할 수록 기존 데이터셋에 더 정확하게 부합할 테니 bias가 떨어지는 것은 당연하다.
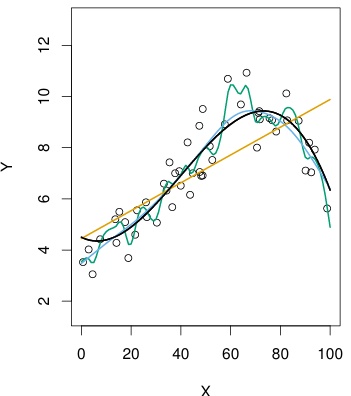
검은색 실제 에 비해 선형모델이 더 bias가 크다.
Variance
Variance는 트레이닝에 사용된 데이터셋이 달라질때마다 변화하는 값이다.
더 flexible한 모델일 수록 variance는 더 상승한다. 특정 데이터셋에 더 fit하게 만들어질수록 다른 데이터셋엔 더 부적합하게 될 것이 분명하기 때문이다.
초록색 선이 더 training sample을 잘 capture하고 있지만, 이 달라지면 아니게 될 것이다.
The Bias-Variance Trade-Off
정리해보면, flexibility는 bias와는 반비례하고, variance와는 비례한다.
동시에 variance와 bias를 감소시킬 순 없다!!
따라서 우리는 가장 적합한 지점을 찾아야한다.
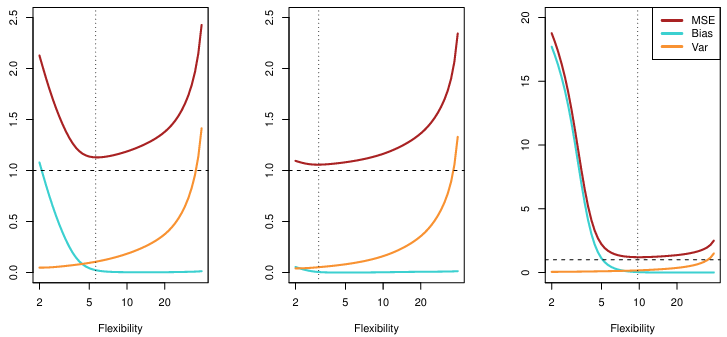
이 그림은 MSE와 Bias Var을 비교한 그림으로 U-shape의 기울기가 0인 지점이 최적의 variance와 bias라는 것을 알 수 있다.
The Classification Setting
분류문제에서 y는 단정적인 성향을 띈다. 따라서, 우리는 오차율을 측정기준으로 사용할 것이다.
- training error rate:는 실제값과 추정값이 다르면 1, 같으면 0인 Indicator Variable이다.
- testing error rate:은 트레이닝에 사용되지 않은 샘플이다.
예시
두개의 predictor, 두개의 그룹 일 때,
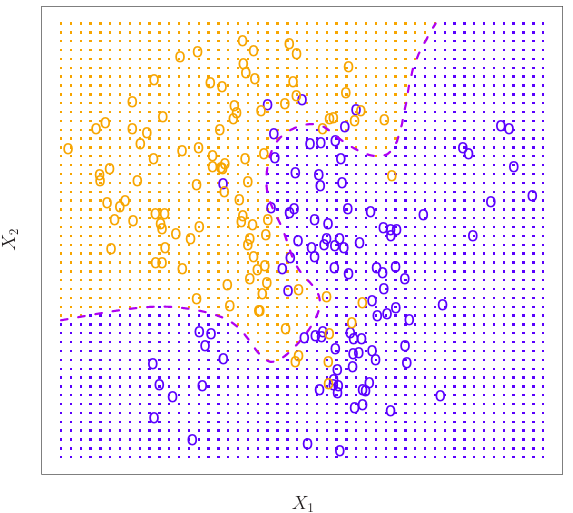
- 주황색 영역은 인 구간이다. 새로운 데이터샘플에 대해서 의 결과가 0.5보다 큰 경우엔 이 그룹에 해당한다.
- 파란색 영역은 인 구간이다. 새로운 데이터샘플에 대해서 의 결과가 0.5보다 작은 경우엔 이 그룹에 해당한다.
- 점선 영역은 decision boundary로 인 구간이다.
KNN (K-Nearest Neighbors)
주어진 에 대해서 를 추정하기 위해 주변의 이웃들을 살펴보는 방법이 있다.
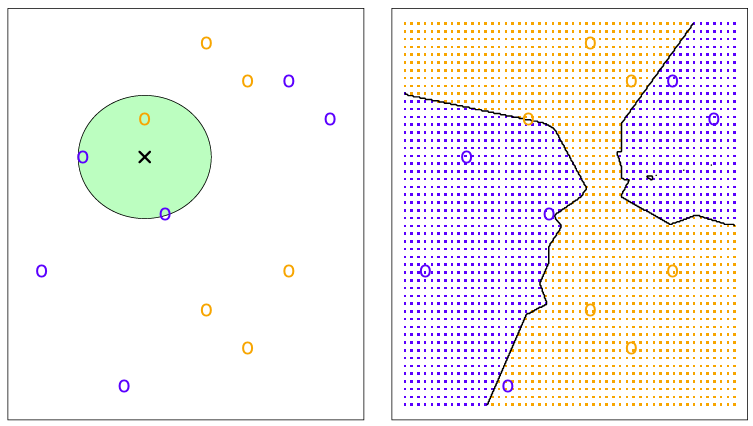
1) 주어진 에 대해서 명의 이웃을 찾는다.
2) 그렇다면 아래와 같은 결과를 얻을 수 있다.
은 과 가까운 개의 지점을 의미한다.
3) 더 높은 확률의 을 취한다. (베이즈 정리)
K=3일 때의 KNN
Bias-Variance Trade off
KNN에서의 Bias와 Variance를 살펴보면,
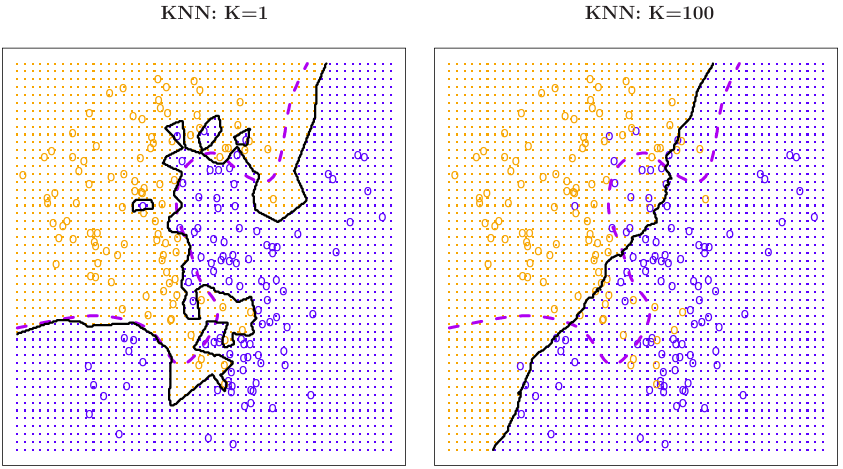
- K=1인 경우에는 bias는 낮지만, variance는 높다.
- K=100인 경우에는 bias는 높지만, variance는 낮다.
다시한번 flexibility는 bias와 반비례하고, variance와 비례한다
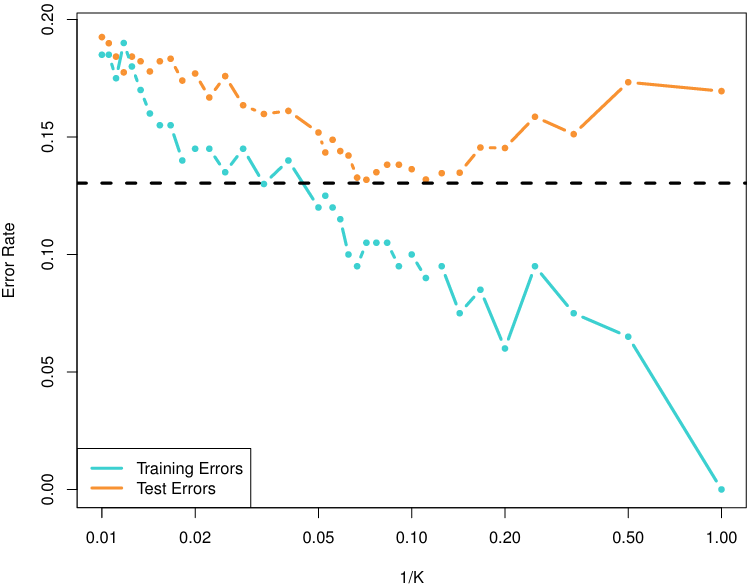
KNN에서도 Bias-Variance trade-off는 존재한다. 위 그래프에서 최적값은 대략 0.075 혹은 대략 0.15에 존재함을 알 수 있다.
Reference
G. James, D. Witten, T. Hastie, R. Tibshirani, and J. Taylor, An introduction to statistical learning: with Applications in Python. Springer, 2023, p15-24
