
통계적 학습이란 무엇인가?
Quantitative response 와 different predictors 에 대해 둘 간의 관계를 다음과 같이 정의한다.
는 에 대해 고정되었지만 알지못하는 함수이고, 은 random error(zero mean)이다.
는 가 에 대해서 제공하는 체계적인 정보라고 할 수 있다.
통계적 학습이란 data로 부터 를 추정하는 것이다.
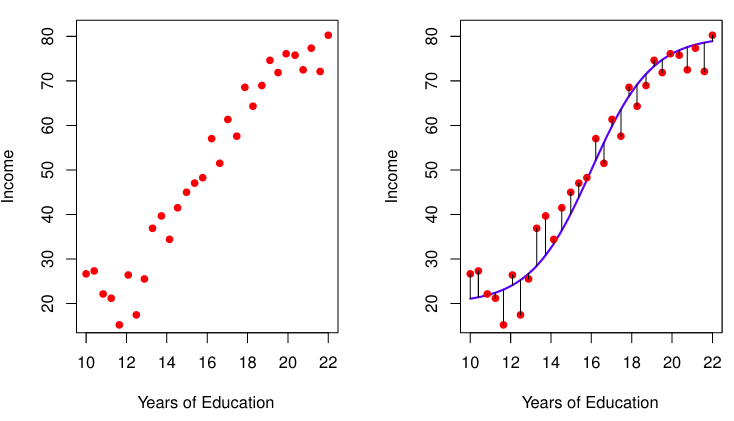
수입과 학업기간 간의 상관관계를 살펴볼 때,
(는 학업기간, 이 수업이다.)
Income = (Years of Education) +
전체적으로 학업 기간이 증가할 수록 수입이 증가하는 경향을 보이고 있지만, 예측선(파란색)과 실제 수치(빨간색)과는 차이가 있다. 이는 학업기간을 제외한 나머지 요소들이 영향을 끼친 결과라고 볼 수 있고, 이를 error로 표현한다.
왜 f를 추정해야하는가?
모델은 예측과 추론에서 효과적이다.
예측은 새로운 에 대해서 를 예상하는 행위이고,
추론은 와 간의 관계를 이해하는 행위다.
그렇다면 예측은 어떻게 하는것인가?
만약 우리가 최적의 모델을 가지고 있다고 하면 아래와 같이 새로운 에 대해 를 예측할 수 있다.
여기서 는 기존에 보지 못한 새로운 데이터여야한다.
는 에 대한 추정값이다.
물론 도 에 대한 추정이다.
과 모두 추정값이기 때문에, 어떻게 해야 좀 더 정확한 값을 만들 수 있는 지가 중요하다.
줄일 수 있는 오차와 줄일 수 없는 오차
와 간에 실제 관계가 다음과 같다고 하자.
우리는 기존에 알려진 정보를 통해 다음을 예측한다.
앞서 말한대로 과 는 완전히 동일하지 않지만, 지속적으로 으로 향상시킬 수 있는 '줄일 수 있는 오차'다.
반면에, 아무리 으로 향상시켜도 이기에 줄일 수 없는 오차 이 존재한다.
에 대한 좀 더 명확한 이해를 위해 아래 그림을 보자.
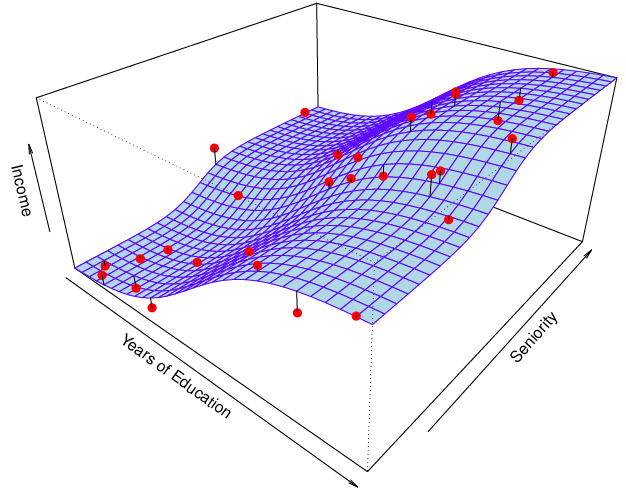
여기서 파란색 3차원 평면이 라고 하면 검은색 실선으로 표현된 오차가 있다. 이를 '줄일 수 없는 오차'라고 표현한다.
오차를 정량화해서 표현하는 방법
- 평균 제곱 오차는 실측값과 예측값의 제곱 차의 평균이고, 은 오차 과 관련된 분산이다.
여기서 는 줄일 수 있는 오차고, 는 줄일 수 없는 오차다.
우리의 목표는 줄일 수 있는 오차를 최소한으로 만드는 것이다.
추론
예측을 하려는 상황에선 에서 가 정확히 무엇인가에 대해선 관심이 없다.
하지만, 와 간의 관계에 대한 추론을 하려는 상황에선 무척 중요하다.
- 어떤 predictor가 결과에 영향을 끼쳤는가?
서로 동일하게 결과에 영향을 끼치지 않을 수 있다! - 결과와 각각의 predictor에는 정확히 어떤 관계가 성립하는가?
어떤 predictor는 반비례관계일 수도 있고, 정비례관계일 수도 있다. - 와 각각의 predictor가 선형방정식으로 적절히 표현되는가? 아니면 더 복잡한가?
예측과 추론의 차이
예시를 통해 알아보자.
1. Direct-marketing
만약에 각각의 사람들이 기부를 요청받았을 때 얼마나 기부할 수 있을지 예측을 하려고 할 때, 모두에게 얼마나 기부할 의사가 있는지 설문조사를 전부 보내야할까?
우리는 어떻게 를 예측하는지 방법에 대한 건 관심이 없다. 직접적으로 누가 얼마만큼 기부할지에 대한 결과만이 관심있다.
2. Advertising
어떤 미디어가 가장 판매에 큰 영향을 끼칠까?
어떤 미디어가 가장 판매를 많이 촉진시킬까?
SNS 홍보를 통해 얼마만큼 판매를 강화했을까?
이를 알기 위해선 와 간의 관계를 알아내는 것이 가장 중요하다.
3. Housing
14개의 요소를 기반으로 집값을 예측하고자 한다.
우리는 어떤 요소가 가장 집값에 영향을 끼치는지를 알고 싶다.
어떻게 f를 예측하는가?
우선 학습을 위한 데이터셋을
이라고 하자.
우리는 이들로 부터 를 예측하려고 한다.
여기엔 두가지 접근 방법이 존재한다.
Parametric methods 와 Non-parametric methods
*파라미터는 가중치와 bias등 데이터로 부터 모델이 학습하게 되는 값이다.
Parametric methods
매개변수로 부터 를 추정한다.
- step1: 우선 함수의 형태를 가정한다.
예를 들어 선형 회귀는 다음과 같이 가정한다.는 각각의 $X{i1}$에 대한 가중치(계수)다.
선형모델의 장점은 많은 수의 parameter를 추정할 필요가 없다는 것이다. - step2: 데이터셋으로 모델을 학습시킨다.
선형모델에서 를 최소제곱법을 이용해 추정하면된다.
선형모델은 개의 계수만 예측하면 된다.
Non-parametric methods
우리는 의 명확한 가정을 하지 않는다.
장점: flexibility, parametric methods보다 더 큰 범위의 를 fitting 할 수 있다.
단점: 학습시키기가 어렵고, 데이터를 더 많이 요구한다.
spline
스플라인은 인접한 두 점 사이에 구간마다 별도의 다항식을 이용해 곡선을 정의하는 방법이다.
Parametric methods와 Non-parametric methods의 예
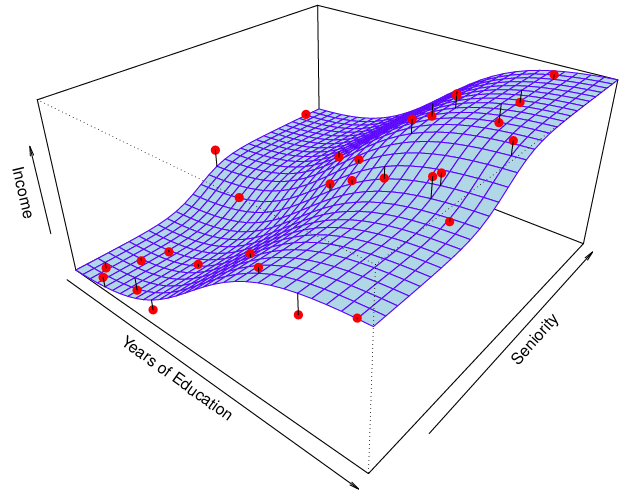
실제 는 위 파란색이라고 할 때,
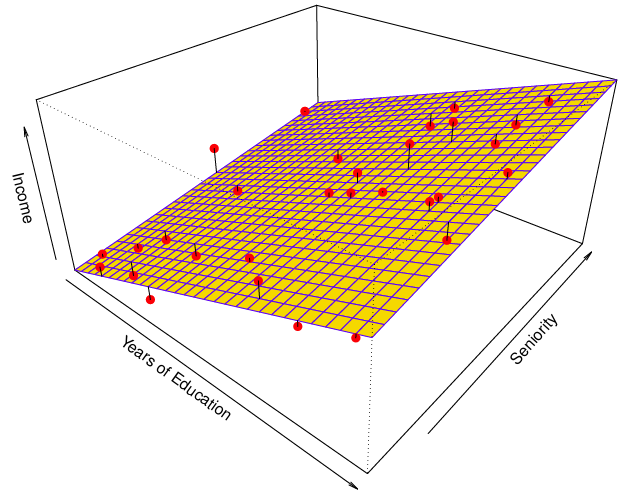
선형모델은 위 그림처럼 모델을 만들고,
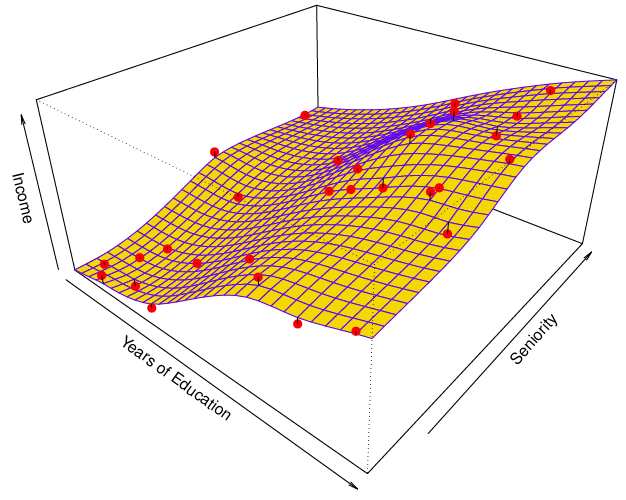
이 이미지는 비선형 모델인 thin-plate spline으로 예측한 모습이다.
주의할 점은 non-parametric model이 매개변수가 없다는 의미가 아니다. 매개변수는 언제나 존재한다.
Parametric model이라는 것은 매개변수를 명확하게 추정할 수 있다는 뜻이다.(예: 선형회귀)
Non-parametric model은 직접적으로 파라미터를 조정할 수 없고, 일종의 모델의 집합을 선택하는 것이다. 사실상 non-parametric model의 매개변수가 더 많다.
flexibility와 interpretability
윗글만 보면 무조건 flexible한 방법(non-parametric model)이 좋을 것 같은데, 왜 더 제한적인 방법(parametric model)을 선택하는 걸까?
flexibility와 interpretability는 아래와 같은 상관관계가 있다.
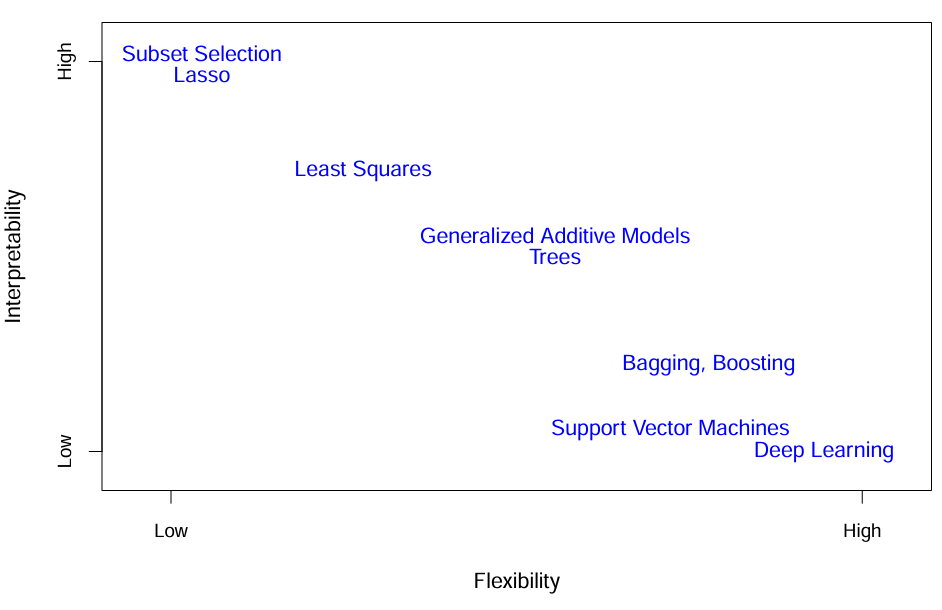
더 flexibility가 증가할 수록 더 interpretability(해석가능성)이 감소한다.
즉, 간단한 모델이 더 해석하기 쉽다.
선형회귀에서
: 다른 모든 변수를 상수로 고정하고, 를 unit만큼 증가했을 때의 평균 증가율
Overfitting
과하게 유연한 모델은 추정능력이 떨어진다.
고계도함수를 만들거나, 계수들을 상당히 많이 만들어서 오차를 최대한으로 줄인다고 해도
1. 이해하기거 어렵고,
2. fit을 완벽하게 했다고 해도, 새로운 데이터에서 정확할지는 확신할 수 없다.(이 내용은 Overfitting과 관련이 있다)
Reference
G. James, D. Witten, T. Hastie, R. Tibshirani, and J. Taylor, An introduction to statistical learning: with Applications in Python. Springer, 2023, p15-24
