
1부
랭체인(LangChain) 정리 (LLM 로컬 실행 및 배포 & RAG 실습)
2부
오픈소스 LLM으로 RAG 에이전트 만들기 (랭체인, Ollama, Tool Calling 대체)
✅ 목표

- 오픈소스 LLM으로 RAG 에이전트 만들기. Tool Calling을 지원하지 않는 ChatOllama로 Tool Calling 기능을 하는 RAG 에이전트 만들어본다
✅ 에이전트
계획, 메모리, 도구 사용 등의 기능을 포함한 AI
- 정보 검색 및 생성: RAG 기술을 사용해서, LLM의 지식을 외부 데이터베이스나 문서로 보완
- 정확성 향상: 검색된 정보를 바탕으로 응답을 생성하여 LLM의 환각(hallucination) 문제를 줄이고 사실의 정확성을 높임
- 최신 정보 활용: 지식 베이스를 정기적으로 업데이트하여 최신 정보에 접근할 수 있음
- 투명성: 정보의 출처를 제공하여 신뢰도를 높이고 사실 확인을 가능하도록 함
- 자연어 인터페이스: 사용자의 자연어 요청을 이해하고 대응할 수 있음
- 다양한 데이터 소스 활용: 다양한 기업 시스템의 데이터를 통합하여 활용할 수 있음
✅ Tool Calling
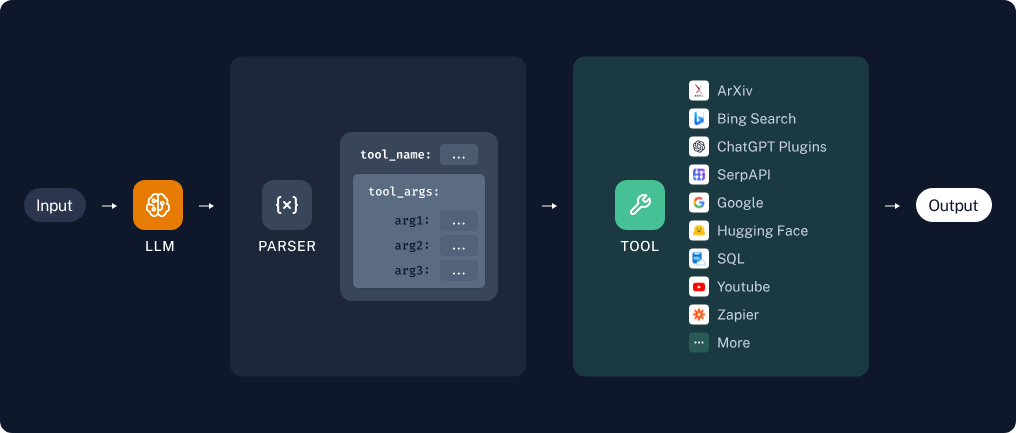
외부 도구나 함수를 호출하여 작업을 수행하는 기능
지원 모델
https://python.langchain.com/v0.2/docs/integrations/chat/
✅ 사용할 모델
- Qwen2: 액션 추출
- EEVE: 주어진 Context와 Question에 기반한 답변 생성
eeve = ChatOllama(model="EEVE-Korean-Instruct-10.8B-v1.0:latest", temperature=0)
qwen2 = ChatOllama(model="qwen2:latest", temperature=0)✅ 액티비티 다이어그램
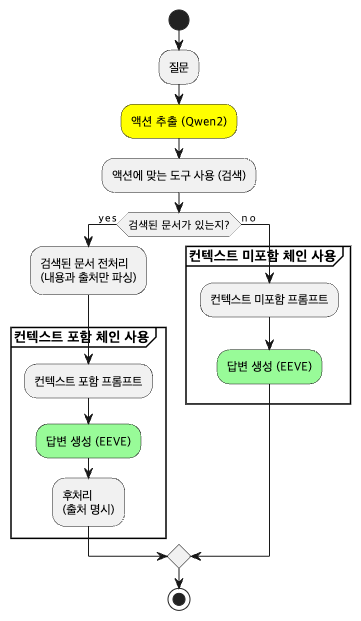
✅ 데이터 불러오기
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-m3",
model_kwargs = {'device': 'cpu'}, # 모델이 CPU에서 실행되도록 설정. GPU를 사용할 수 있는 환경이라면 'cuda'로 설정할 수도 있음
encode_kwargs = {'normalize_embeddings': True}, # 임베딩 정규화. 모든 벡터가 같은 범위의 값을 갖도록 함. 유사도 계산 시 일관성을 높여줌
)
# 로컬 DB 불러오기
MY_NEWS_INDEX = "MY_NEWS_INDEX"
vectorstore1 = FAISS.load_local(MY_NEWS_INDEX,
embeddings,
allow_dangerous_deserialization=True)
retriever1 = vectorstore1.as_retriever(search_type="similarity", search_kwargs={"k": 3}) # 유사도 높은 3문장 추출
MY_PDF_INDEX = "MY_PDF_INDEX"
vectorstore2 = FAISS.load_local(MY_PDF_INDEX,
embeddings,
allow_dangerous_deserialization=True)
retriever2 = vectorstore2.as_retriever(search_type="similarity", search_kwargs={"k": 3}) # 유사도 높은 3문장 추출✅ Tools
from langchain.tools.retriever import create_retriever_tool
retriever_tool1 = create_retriever_tool(
retriever1,
name="saved_news_search",
description="""
다음과 같은 정보를 검색할 때에는 이 도구를 사용해야 한다:
- 엔비디아의 스타트업 인수 관련 내용
- 퍼플렉시티 관련 내용 (회사가치, 투자 등)
- 라마3 관련 내용
""",
)
retriever_tool2 = create_retriever_tool(
retriever2,
name="pdf_search",
description="""
다음과 같은 정보를 검색할 때에는 이 도구를 사용해야 한다:
- 생성형 AI 신기술 도입에 따른 선거 규제 연구 관련 내용
- 생성 AI 규제 연구 관련 내용
- 생성 AI 연구 관련 내용
"""
)
tools = [retriever_tool1, retriever_tool2]
tools✅ 액션 추출 (Qwen2)
prompt_for_extract_actions = hub.pull("kwonempty/extract-actions-for-ollama")
def get_tools(query) -> str:
"""
사용 가능한 도구들의 이름과 설명을 JSON 문자열 형식으로 변환하여 반환
"""
# tools 리스트에서 각 도구의 이름, 설명을 딕셔너리 형태로 추출
tool_info = [{"tool_name": tool.name, "tool_description": tool.description} for tool in tools]
print(f"get_tools / tool_info: {tool_info}")
# tool_info 리스트를 JSON 문자열 형식으로 변환하여 반환
return json.dumps(tool_info, ensure_ascii=False)
chain_for_extract_actions = (
{"tools": get_tools, "question": RunnablePassthrough()}
| prompt_for_extract_actions
| qwen2
| StrOutputParser()
)- 실행결과
chain_for_extract_actions.invoke("3+4 계산해줘")
query = "라마3 성능은 어떻게 돼? 그리고 생성형 AI 도입에 따른 규제 연구 책임자는 누구야?"
actions_json = chain_for_select_actions.invoke(query)
actions_json
✅ 액션에 맞는 도구 사용
def get_documents_from_actions(actions_json: str, tools: List[Tool]) -> List[Document]:
"""
주어진 JSON 문자열을 파싱하여 해당 액션에 대응하는 검색기를 찾아서
액션을 실행 후 검색된 문서를 반환
:param actions_json: 액션과 그 입력이 포함된 JSON 문자열
:param tools: 사용 가능한 도구들의 리스트
:return: 액션을 통해 검색된 문서들의 리스트
"""
print(f"get_documents_from_actions / actions_json: {actions_json}")
# JSON 문자열을 파싱
try:
actions = json.loads(actions_json)
except json.JSONDecodeError:
raise ValueError("유효하지 않은 JSON 문자열")
# 파싱된 객체가 리스트인지 확인
if not isinstance(actions, list):
raise ValueError("제공된 JSON은 액션 리스트를 나타내야 함")
documents = []
# 도구 이름으로 검색기를 가져오는 함수
def get_retriever_by_tool_name(name: str) -> VectorStoreRetriever:
for tool in tools:
if tool.name == name:
return tool.func.keywords['retriever']
return None
# 각 액션을 처리
for action in actions:
if not isinstance(action, dict) or 'action' not in action or 'action_input' not in action:
continue # 유효하지 않은 액션은 건너뜀
tool_name = action['action']
action_input = action['action_input']
print(f"get_documents_from_actions / tool_name: {tool_name} / action_input: {action_input}")
if tool_name == "None": # 사용할 도구 없음. 바로 빈 document 리턴
print(f"get_documents_from_actions / 사용할 도구 없음. 바로 빈 document 리턴")
return []
retriever = get_retriever_by_tool_name(tool_name)
if retriever:
# 액션 입력으로 검색기 실행
retrieved_docs = retriever.invoke(action_input)
documents.extend(retrieved_docs)
print(f"get_documents_from_actions / len(documents): {len(documents)}")
return documents- 실행결과
get_documents_from_actions(actions_json, tools)
✅ 에이전트 최종 답변 생성 (EEVE)
프롬프트
agent_prompt = ChatPromptTemplate.from_messages([
("system", """
너는 정확하고 신뢰할 수 있는 답변을 제공하는 유능한 업무 보조자야.
아래의 context를 사용해서 question에 대한 답변을 작성해줘.
다음 지침을 따라주세요:
1. 답변은 반드시 한국어로 작성해야 해.
2. context에 있는 정보만을 사용해서 답변해야 해.
3. 정답을 확실히 알 수 없다면 "주어진 정보로는 답변하기 어렵습니다."라고만 말해.
4. 답변 시 추측하거나 개인적인 의견을 추가하지 마.
5. 가능한 간결하고 명확하게 답변해.
# question:
{question}
# context:
{context}
# answer:
"""
),
])
default_prompt = ChatPromptTemplate.from_messages([
("system", """
너는 정확하고 신뢰할 수 있는 답변을 제공하는 유능한 업무 보조자야.
다음 질문에 최선을 다해서 대답해줘.
# question:
{question}
# answer:
"""
),
])전처리 & 후처리
retrieved_docs = []
def get_page_contents_with_metadata(docs) -> str:
"""
문서 리스트를 받아 각 문서의 본문 내용과 출처를 포함한 문자열을 생성
"""
global retrieved_docs
retrieved_docs = docs
result = ""
for i, doc in enumerate(docs):
if i > 0:
result += "\n\n"
result += f"## 본문: {doc.page_content}\n### 출처: {doc.metadata['source']}"
return result
def get_retrieved_docs_string(query) -> str:
"""
쿼리에 따라 문서를 검색하고, 해당 문서들의 본문 내용과 출처를 포함한 문자열을 반환
"""
actions_json = chain_for_extract_actions.invoke(query)
docs = get_documents_from_actions(actions_json, tools)
if len(docs) <= 0:
return ""
return get_page_contents_with_metadata(docs)
def get_metadata_sources(docs) -> str:
"""
문서 리스트에서 각 문서의 출처 추출해서 문자열로 반환
"""
sources = set()
for doc in docs:
source = doc.metadata['source']
is_pdf = source.endswith('.pdf')
if (is_pdf):
file_path = doc.metadata['source']
file_name = os.path.basename(file_path)
source = f"{file_name} ({int(doc.metadata['page']) + 1}페이지)"
sources.add(source)
return "\n".join(sources)
def check_context(inputs: dict) -> bool:
"""
context 존재 여부 확인
:return: 문자열이 비어있지 않으면 True, 비어있으면 False
"""
result = bool(inputs['context'].strip())
print(f"check_context / result: {result}")
return result
def parse(ai_message: AIMessage) -> str:
"""
AI 메시지 파싱해서 내용에 출처 추가
"""
return f"{ai_message.content}\n\n[출처]\n{get_metadata_sources(retrieved_docs)}"체인
with_context_chain = (
RunnablePassthrough()
| RunnableLambda(lambda x: {
"context": x["context"],
"question": x["question"]
})
| agent_prompt
| eeve
| parse
)
without_context_chain = (
RunnablePassthrough()
| RunnableLambda(lambda x: {"question": x["question"]})
| default_prompt
| eeve
| StrOutputParser()
)
agent_chain = (
{"context": get_retrieved_docs_string, "question": RunnablePassthrough()}
| RunnableBranch(
(lambda x: check_context(x), with_context_chain),
without_context_chain # default
)
)- 실행결과
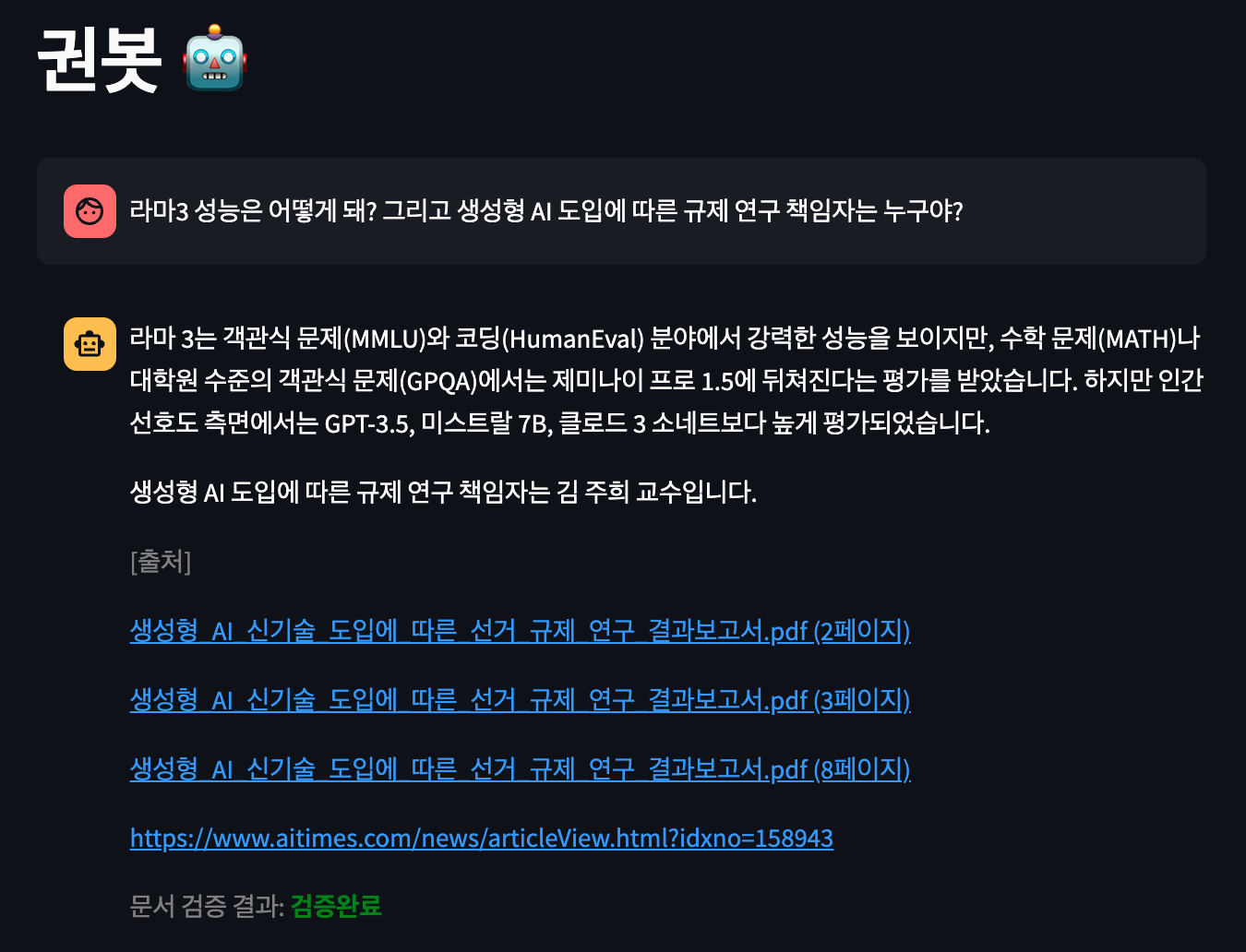
✅ 참조

서비스 핵심 가치를 이해하고, 지속적인 개선을 이끄는 엔지니어(를 지향함)
4개의 댓글

2024년 8월 28일
QWEN2만 쓰는게 아니라 EVEE도 같이 쓴 이유가 QWEN2만쓰면 위 답변처럼 한국어가 매끄럽지 않으니 텍스트 전처리, 가공 등은 성능이 뛰어난 qwen2를 쓰고 나온 데이터 셋을 evee로 가공한건가요?
맞다고 한다면 ollma 사용시 evee와 qwen2를 모두 설치해야겠군요
1개의 답글
항상 좋은 글 잘보고 갑니다 :)