from sklearn.cluster import DBSCAN
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import pandas as pd
form sklearn.decomposition import PCA
#sale데이터 로딩
data = pf.read.csv("wholesale.csv")
data.shape
print(data.head(5))
#차원축소(PCA)
pca = PCA(n_components=2)
result = pca.fot_transform(data)
stscaler = StandardScaler().fit(result)
result = stscaler.transform(result)Wholsale은 슈퍼에서 물건을 구매한 데이터이고
구매 형태를 통한 패턴 분석
패턴만 분석하는 것으로 마무리 = 비감독학습
차원숙소
components 2 - 2개의 데이터로 정한 이유 - 그래프가 2차원이기 때문
StandardScaler로 정규화 시킴

pca

정규화
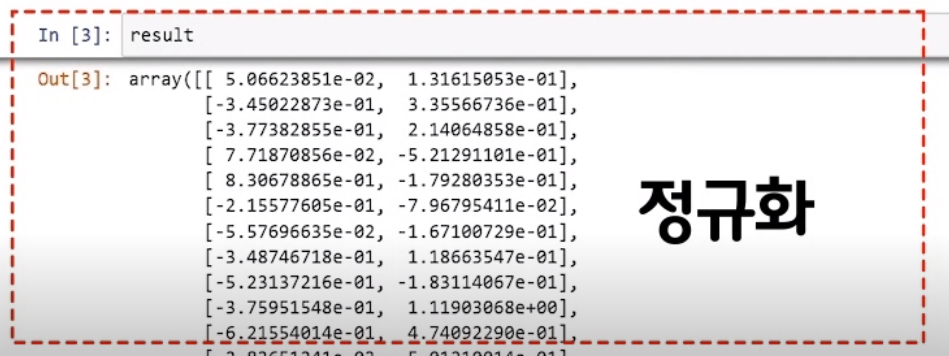
8개의 차원을 가장 잘 설명할 수 있도록 2개의 차원을 만든것

import matplotlib.pyplot as plt
%pylab inline
plt.scatter(result[:,0], result[:,1], s = 2, color = 'blue')
plt.xlabel("pca-1")
plt.ylabel("pca-2")
plt.title("Wholesale Data - PCA")
plt.savefig("pca_wholesale.png", format = "PNG)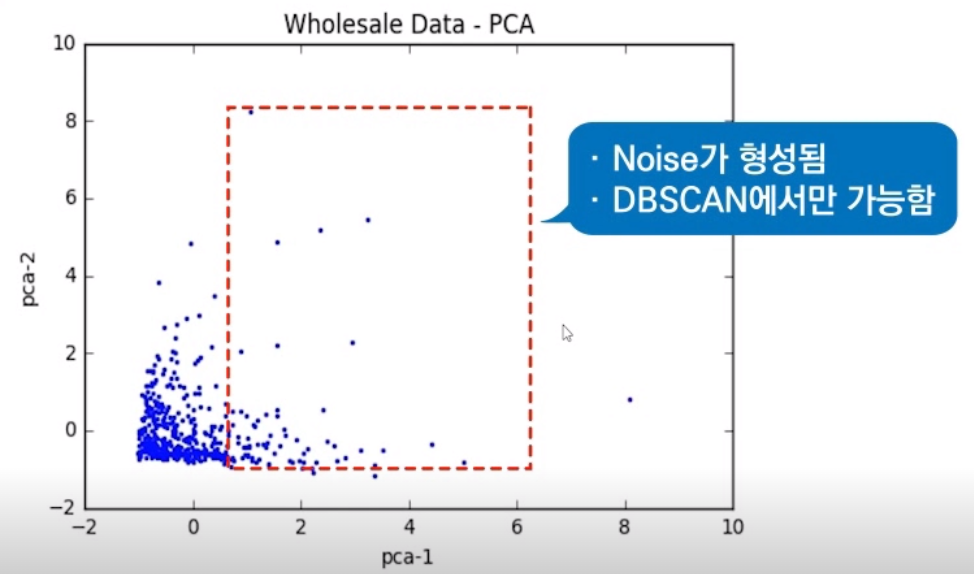
군집이 형성됨
#밀도기반 군집분석(DBSCAN)
dbsc = DBSCAN(eps = .5, min_samples = 15). fit(result)
labels = dbsc.labels_
core_samples = np.zeros_like(labels, dtype = bool)
core_samples[sbsc.core_sample_indices_] = True
labels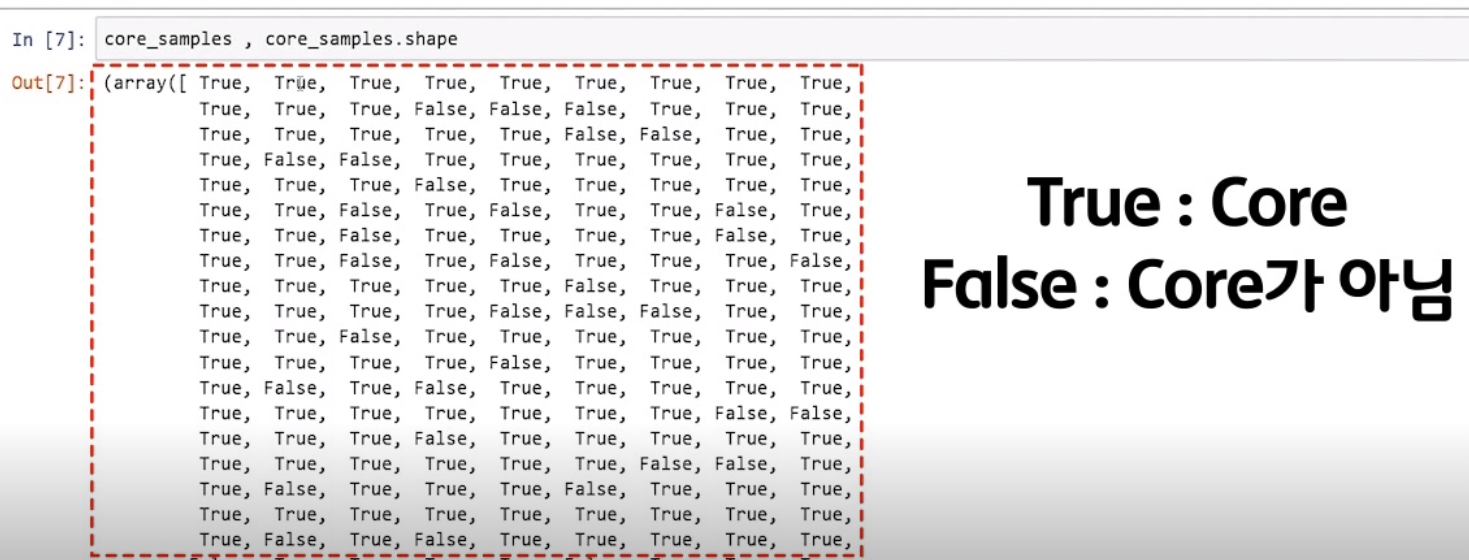

하고싶은게 너무 많다