[Paper Review] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
RAG
Abstract
- 리랭킹 task에서 기존 pointwise 및 listwise 방식은 LLM에게 지나치게 어려운 task였다.
- 본 연구에서는 이러한 부담을 경감하기 위해 한 쌍의 문서만을 비교하는 PRP(Pairwise Ranking Prompting) 기법을 제안한다.
- 중소형 오픈소스 LLM을 사용하여 GPT-4와 대등한 성능을 보였다.
- 또한 PRP의 여러 변형을 통해 성능을 유지하면서도 계산 복잡도를 선형(linear) 수준까지 낮출 수 있었다.
1. Instruction
GPT-3과 같은 모델들은 제로샷에서도 잘 동작하지만, text ranking은 별도로 학습된 모델들에 비해 성능이 좋지 않다. Pointwise 방식의 경우, 모델이 각 문서의 보정된 예측값을 매겨야 하는데, LLM이 이를 어려워한다. Listwise 방식의 경우, LLM(특히 중소형 모델)은 모순되거나 쓸모없는 결과물을 생성한다.
따라서, 본 연구에서는 중소형 오픈소스 모델만으로도 좋은 성능을 낼 수 있는 PRP 방법을 제안한다.
2. Difficulties of ranking tasks for LLMs
2.1. Pointwise
- LLM이 출력하는
yes토큰의 확률값이 일관되어야 하는데 그렇지 않다. - 또한 ranking은 결국 문서들 간의 상대적인 순서를 비교하는 것인데, 하나씩 점수를 매기는 방식은 불필요하다.
- GPT-4와 같은 모델들(API)는 확률값을 제공하지 않아서 이 방식을 사용할 수 없다.
2.2. Listwise
Listwise 방식의 오류 유형
- 누락(Missing): 모든 문서 번호를 다 출력해야 하는데, 출력 결과에서 문서의 일부를 생략하는 오류
- 거부(Rejection): ranking을 매기지 않고 다른 결과를 출력하는 오류
- 반복(Repetition): 똑같은 문서 번호를 여러 번 출력하는 오류
- 불일치(Inconsistency): 문서들의 순서를 바꾸어 입력할 때 출력 결과 순위가 완전히 뒤바뀌는 오류
3. Pairwise Ranking Prompting
3.1. Prompting design
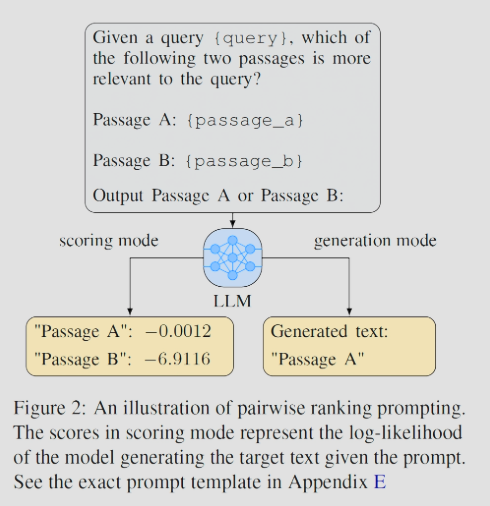
LLM에게 질의와 2개의 문서를 제공하고, 어떤 문서가 질의와 더 관련 있는지를 질문한다.
이 방식은 텍스트를 생성하는 generation mode와, 로그 확률을 계산하는 scoring mode를 모두 지원한다.
scoring mode를 사용하면, LLM이 엉뚱한 결과를 출력하는 문제를 완화할 수 있으므로, 기본 결과는 scoring mode를 기반으로 하였다.
또한, LLM이 문서 입력 순서에 민감한 점을 고려하여, 문서의 순서를 바꿔서도 테스트를 진행하였다. 순서가 일치하면 그대로 적용하였고, 서로 다르게 출력되면 d1=d2인 것으로 간주하였다.
3.2. All pair comparisons
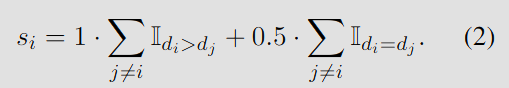
모든 문서 쌍을 나열해서 비교하고, 비교하여 얻은 점수 (0, 0.5, 1)를 합산해서 최종 순위를 정한다.
이 방식은 구현이 단순하고 병렬 처리가 가능하며, 입력 순서에 영향을 받지 않는다.
단, 계산 복잡도가 라서 고비용이다.
3.3. Sorting-based
계산 복잡도는 이다. 상위 K개만 중요하면, K번만 반복하면 되기 때문에 효율성을 극대화할 수 있다.
본 연구에서는 Heapsort 방식을 사용햐여 계산 복잡도를 으로 보장하였다.
실험 결과, 입력 순서에 큰 영향을 받지 않았다.
3.4. Sliding window
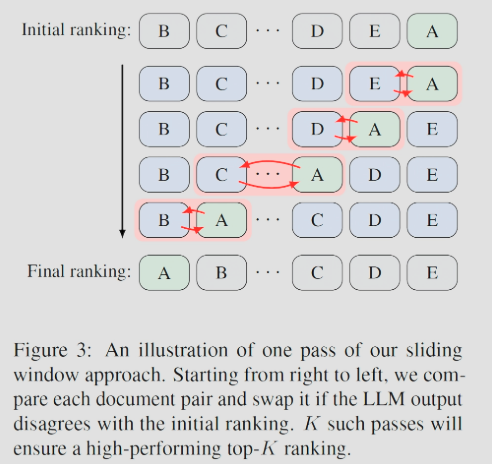
한 번의 슬라이딩 윈도우 pass는 Bubble Sort의 pass와 유사하다.
최초 ranking 목록이 주어졌을 때, 하위부터 시작하여 문서 한 쌍을 비교하고, 더 관련 있는 문서를 앞으로 배치한다(순위를 뒤바꾼다).
하나의 pass는 시간 복잡도만 요구한다.
4. Experiments on TREC DL datasets
4.1. Datasets and Metrics
- TREC-DL 2019, 2020 사용
- MS MARCO
- BM25으로 상위 100개를 추출하여, LLM으로 Reranking 수행
4.2. Methods
- Supervised baseline (monoBERT, monoT5, RankT5)
- LLM-based baseline (Unsupervised Passage Reranker, Relevance Generation, RankGPT, Listwise Reranker)
4.3. Main Results
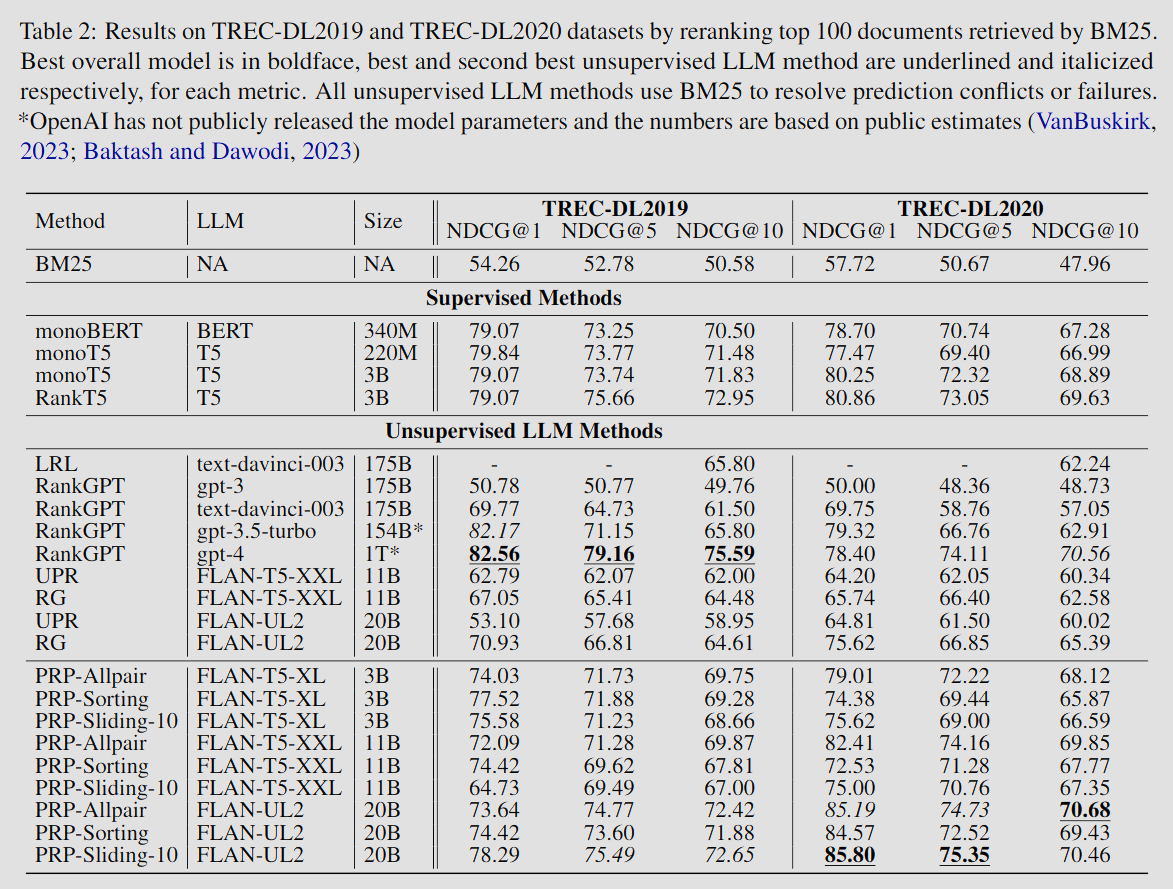
- FLAN-UL2(20B) 모델로 GPT-4와 유사한 성능 달성
- FLAN-T5-XL, FLAN-T5-XXL도 좋은 성능 달성. PRP가 단순한 방식이기 때문에 작은 LLM에서도 일반화가 잘 된다는 것을 시사한다.
- gpt-3.5-turbo, text-davinci-003보다 더 안정적인 성능 달성
5. Experiments on BEIR datasets
5.1. Datasets and metrics
- BEIR epdlxjtpt tkdyd
- NDCG@10 사용
5.2. Methods
- TREC 실험과 동일한 프롬프트 사용
5.3. Main Results
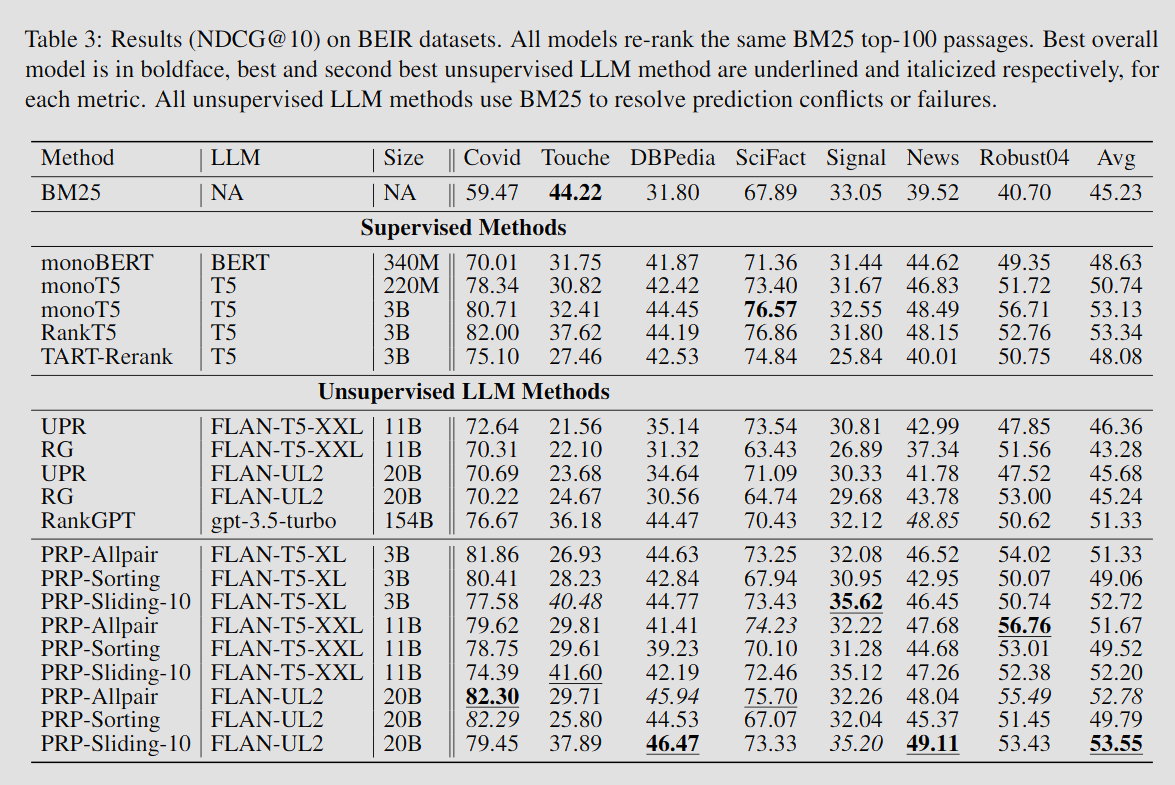
- FLAN-UL2 기반 PRP가 가장 좋은 성능을 보였다.
- RankGPT보다 4.2% 더 높은 성능을 달성하였고, 기존 pointwise 방식들보다는 10% 이상 우수하였다.
- RankT5보다도 7개 중에서 5개 데이터셋에서 더 낫거나 유사하였다.
6. Ablation studies
Robustness to input ordering
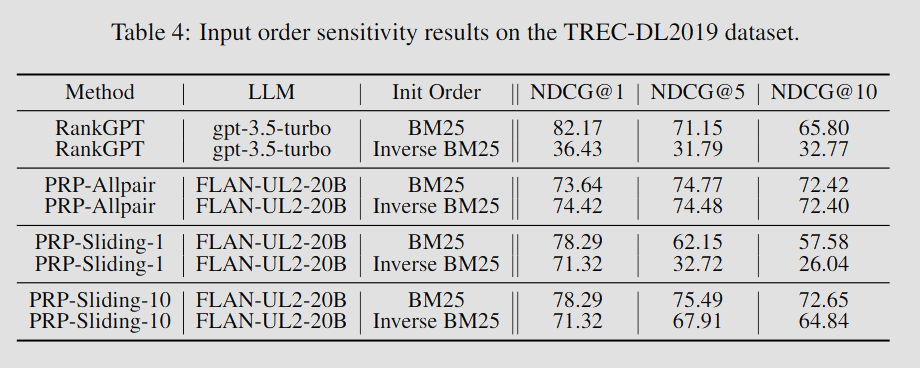
listwise 방식은 문서 입력 순서에 따라서 성능이 크게 차이나는 이슈가 있었다.
PRP 방식에서도 같은 현상이 나타나는가를 확인하기 위해 BM25결과를 역순으로 정렬하여 성능을 확인하였다.
PRP-Allpair의 경우 성능 변화가 거의 없었고, PRP-Sliding-10에서도 성능이 유지되었다.
Comparison of scoring mode and generation mode
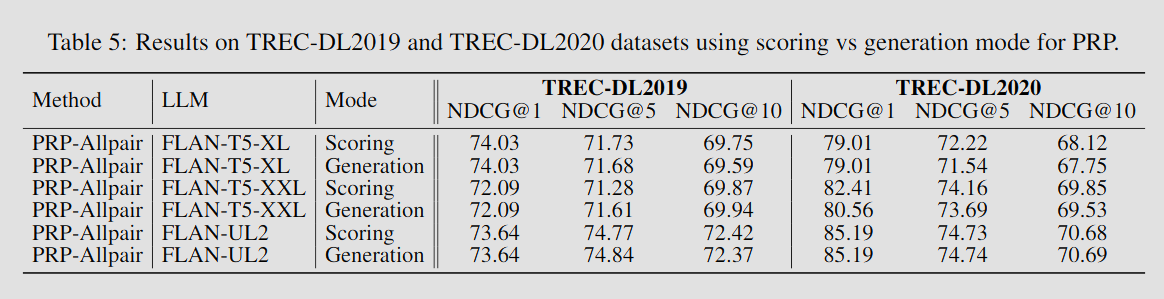
PRP 방식은 scoring mode나 generation mode 모두에서
일관된 성능을 보였다.
Study on sliding window
뒤에서부터 앞으로 비교하는 Backward 방식이 더 효과적이었다.
정렬 반복 횟수를 늘릴수록 nDCG가 더 개선되었다.
7. Discussion
Extendability
- 설계가 단순해서 즉시 적용 가능하다.
- 정교한 프롬프트 설계 혹은 api 점수값과 같은 추가 정보를 활용해서 성능을 더욱 개선할 수 있다.
Reproducibility
- 9개의 데이터셋에 모두 동일한 프롬프트를 사용해서 재현 가능성을 확보하였다.
Cost and Efficiency
- 오픈소스 모델을 활용하여 비용 부담을 감소하였다.
Data Leakage from LLMs
- 오픈소스 모델을 활용하여, label leakage를 최소화하였다.
- 동일한 LLM으로 pointwise, listwise를 모두 비교하여 실험의 공정성을 확보하였다.
9. Conclusion
본 연구에서는 Pairwise prompting 기법을 제안하였고, 이 방법을 통해 LLM의 task 부담을 줄여서, 중소형 오픈소스 모델의 text ranking 성능 향상을 확인할 수 있었다.
PRP 방법은 입력 순서와 무관하게 결과가 유지되고, scoring, generation mode 모두에서 잘 작동되므로 활용도가 높다.
