[Paper Review] RankGPT(2024): Is ChagGPT good at search? Investigating Large Language Models as Re-Ranking Agents
RAG

Abstract
- LLM은 다양한 태스크에서 뛰어난 제로샷 생성 능력을 보여왔지만, 기존 연구들은 LLM을 IR에 적용할 때 재정렬보다는 텍스트 생성 능력을 활용하는 데 그쳤다.
- 본 논문은 ChatGPT, GPT-4와 같은 LLM의 재정렬 능력을 조사하였고, 실험 결과 적절한 지시를 받은 LLM은 IR 벤치마크에서 SOTA supervised 방식을 뛰어넘는 성능을 보였다.
- 평가 데이터의 데이터 오염을 고려하기 위해 NovelEval 데이터셋을 수집하였다.
- 사용성을 고려해, 순열 증류(permutation distillation) 기법을 이용해 ChatGPT의 재정렬 능력을 소형 특화 모델에 증류하였다. 그 결과, BEIR 벤치마크에서 증류한 440M 모델이 3B 모델을 뛰어넘었다.
1. Introduction
IR 시스템은 검색(Retrieval), 재정렬(re-ranking) 파이프라인으로 구성된다. 하지만 기존의 재정렬 방식들은 사람의 공수가 들어가는 지도학습 데이터에 지나치게 의존하여, 비용이 많이 들고 일반화하기 어렵다는 한계가 있었다.
LLM의 제로샷 생성 능력을 IR 영역에 활용하려는 연구가 늘어났지만, 문서들의 순위를 매기기보다는 질문이나 문단을 생성해내는 내용 생성에만 치중하였다.
LLM의 능력을 재정렬에 활용하기 위해서는 유저의 요구사항을 이해해야 하고, 질문과 문서 간의 관련성을 전체적으로 비교할 수 있어야 한다.
이에 본 논문은 다음과 같은 연구 질문을 해결하는 데 집중한다.
- RQ 1. ChatGPT를 문서 재정렬 작업에 투입하면 얼마나 잘할까?
- RQ 2. 어떻게 하면 ChatGPT의 재정렬 능력을, 소형 특화 모델에 효율적으로 모방시킬 수 있을까?
위 연구 질문을 해결하기 위해 제안하는 해결책
- 순열 생성(Permutation Generation), Sliding Window
- LLM에게 직접 문서 번호를 관련된 순서대로 나열하라고 지시한다.
- context 길이 제한을 극복하기 위해 그룹 단위로 묶어서 순위를 매기는 Sliding Window 전략을 사용한다.
- NovelEval
- 기존 평가 데이터들은 이미 LLM 학습에 사용되어, 데이터 오염 가능성이 있다. 이를 방지하기 위해 최신 지식을 묻는 새로운 평가 데이터셋을 수집한다.
- 순열 증류(Permutation Distillation)
- MS MARCO 데이터셋에서 무작위로 1만 개의 질문들을 추출하고, 후보 문서 20개씩을 BM25로 찾아낸다. 이후 ChatGPT가 이에 대해 예측한 순위 순열을 정답지로 삼아서, 학생 모델을 학습한다. 이때 RankNet 목적함수를 사용한다.
Contributions
- LLM의 문서 재정렬을 위한 지시 방법을 조사하였고, 순열 생성 방식을 제안한다.
- ChatGPT, GPT-4를 다양한 재정렬 벤치마크에 대해 평가하였고, NovelEval 평가셋을 제안한다.
- ChatGPT가 생성한 순열을 기반으로 소형 특화 모델을 증류하는 방법을 제안한다.
2. Related Work
2.1. Information Retireval with LLMS
기존 연구들의 LLM 활용 방식
- 문서 검색
- GPT를 이용해 텍스트 임베딩 생성 (SGPT)
- GPT-3을 이용해 가짜 문서를 생성 (HyDE)
- 재정렬
- 지시 기반의 질문 생성 방식(UPR, SGPT-CE)
- Relevance generation (HELM)
- 학습 데이터 생성
- GPT-3을 활용해 가짜 질문 생성 (InPars)
- few-shot dense 검색으로 도메인에 대한 설명을 연결하여 가짜 질문 생성 (Promptagator)
→ 본 논문은 ChatGPT, GPT-4를 재정렬 작업에 직접 활용하며, 지시 기반의 순열 생성 방식을 제안하고 다양한 벤치마크에서 평가한다.
최근 다른 연구(Ma et al., 2023)에서도 리스트 단위 문서 재정렬을 조사했지만, 본 연구는 새로운 데이터셋(NovelEval)을 포함하여 더 포괄적인 평가를 제공하고, 순열 증류 방법 또한 검증한다는 차이점이 있다.
2.2. LLMs Specialization
비용 절감을 위해 지식 증류를 위한 연구들이 진행되어왔다.
- Reasoning 능력 증류
- Self-instruct (GPT-3의 출력 결과를 활용한 증류)
→ 본 논문에서는 ChatGPT를 teacher로 활용하여, 재정렬에 전문화된 모델을 얻기 위한 순열 증류 방식을 제안한다.
3. Passage Re-Ranking with LLMs
최신 IR 시스템은 일반적으로 검색과 재정렬로 이루어지는 파이프라인을 따른다. 검색 단계에서 대규모 코퍼스에서 후보군을 찾아내면, 재정렬 단계는 이 후보군들을 다시 정렬하여 더 정확한 목록을 출력하는 것을 목표로 한다.
최근 연구들은 질문 생성이나 관련성 생성(relevance generation) 과 같이 제로샷 재정렬을 위해 LLM을 활용하는 방안을 탐구해왔다. 하지만 기존 방법들은 성능의 한계가 있으며, 모델이 출력하는 로그 확률을 얻을 수 있어야만 하는 한계가 있다. GPT-4와 같은 최신 모델에는 이와 같은 방법을 활용할 수가 없다.
이에 본 논문은 후보 문서 집합이 주어졌을 때 순위 목록을 직접 출력할 수 있도록, sliding window 전략과 permutation generation 방법을 제안한다.
3.1. Instructional Permutation Generation

- LLM에 입력을 넣을 문서 그룹을 넣을 때 각 문서마다 식별자
[1], [2] 등을 넣어준다. - 그런 다음 LLM에게 질문과의 관련성을 기준으로 문서를 내림차순으로 정렬한 순열을 생성하라고 지시한다.
- LLM은
[2] > [3] > [1]과 같은 형식으로 순열을 출력하게 된다.
이러한 방법은 별도의 관련성 점수를 생성하지 않고, 문서들의 순위를 직접적으로 매긴다는 특징이 있다.
3.2. Sliding Window Strategy
LLM 입력 토큰 수 제한 때문에, 제한된 개수의 문서들에 대해서만 순위를 매길 수 있다. 이러한 제약을 극복하기 위해 슬라이딩 윈도우 전략을 제안한다.

- 검색 모델이 M개의 문서를 반환한다.
- 뒤에서부터, M-w 번째부터 M번째 까지의 문서 순위를 정렬한다. (w: window size)
- 윈도우를 s 스텝만큼 이동하여 M - w - s번째부터 M-s 번째 범위의 문서들을 다시 재정렬한다.
- 모든 문서가 재정렬될 때까지 반복한다.
개인적인 의견: 왜 뒤에서부터 할까? 1단계 검색 결과에서 하위 순위로 잘못 평가된 문서를 점차 앞 순위로 올리기 위해 뒤에서부터 하는 것으로 보임
4. Specialization by Permutation Distillation
ChatGPT, GPT-4는 좋지만 너무 비싸고, 지연이 걸릴 수 있다. 또한 생성 결과가 불안정할 수 있다. 이를 해결하기 위해 더 작은, 재정렬 특화 모델을 증류 방식으로 만들 수 있다.
4.1. Permutation Distillation
제안하는 방법과 기존 증류 방식 간의 핵심적인 차이점은, 일관성 확인(consistency-checking)이나 로그 확률을 거치지 않고, 그 대신에 모델이 생성한 순열 자체를 학습 목표 데이터로 사용한다.
이를 위해 MS MARCO 데이터셋에서 1만 개의 질문을 무작위 추출하고, 각 질문에 대해 BM25를 사용하여 20개의 후보 문서를 검색하였다.
이 증류의 목적은 학생 모델의 순열 출력 결과와 ChatGPT의 순열 출력 결과 사이의 차이를 줄이는 것이다.
4.2. Training Objective
질문 q와, BM25로 검색한 M개의 문서들(p_1, …, p_M)이 있다고 가정해보자.
순열 생성 방식을 사용한 ChatGPT는 이 M개의 문서들의 랭킹 결과인 을 생성할 수 있으며, 여기서 는 문서 의 순위를 의미한다.
파라미터 를 갖는 크로스 인코더 기반 특화 모델 이 쌍의 관련성 점수 를 계산한다.
학생 모델을 최적화하기 위해 RankNet loss를 사용한다.
- RankNet: 질문과 각 문서 간의 관련성 점수 차이를 잘 맞히기 위한 loss 함수. 실제 정답 순위가 < 일 때, 예측 점수도 라고 잘 맞힌다면, 가 음수가 되어 전체 loss는 아주 작게 부여된다. 반대로 예측 점수가 틀린다면 (), 가 양수가 되어, 틀린 차이 만큼 큰 loss가 주어진다.
4.3. Specialized Model Architecture
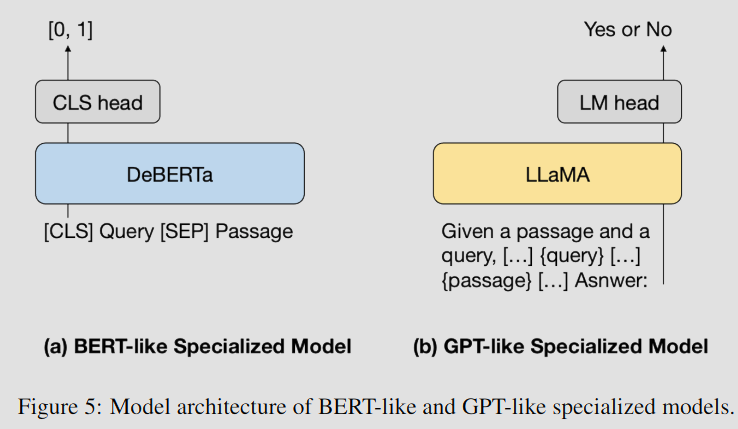
4.3.1. BERT-like model
DeBERTa-large 기반의 cross-encoder 모델을 활용한다. 질문과 문서를 [SEP] 토큰으로 연결하고, [CLS] 토큰의 representation 값으로 관련성 점수를 측정한다.
4.3.2. GPT-like model
LLaMA-7B를 활용한다. 제로샷 관련성 생성 지시문으로 프롬프팅한다.
relevance token의 확률 값으로 관련성 점수를 측정한다.
5. Datasets
5.1. Benchmark Datasets
- TREC: TREC_DL19 (43개 질문), TREC_DL20 (54개 질문)
- BEIR: covid(COVID-19 관련 질의), NFCorpus(bio-medical), Touche(argument), DBPedia(DBPedia 코퍼스), SciFact(주장 검증), Signal(트위터), News(헤드라인), Robust04(토픽)
- Mr.TyDi: 저자원 언어(아랍어, 벵골어, 한국어 등. 각 언어에서 100개 샘플 추출)
5.2. A New Test Set – NovelEval
기존 벤치마크들은 수년 전에 수집된 것이기 대문에 , 기존 LLM이 이미 이 질문들에 대한 지식을 보유하고 있을 수 있다는 문제가 있다.
따라서 공정한 평가를 위해 최신 LLM이 아직 학습하지 못한 지식임을 보장하는, 지속적으로 업데이트되는 IR 테스트셋 구축을 제안한다.
그 초기 시도로, 21개의 새로운 질문이 포함된 NovelEval-2306을 구축하였다. GPT-4 출시 이후에 발표된 4개 도메인의 질문과 문서들을 모아 만들었으며, gpt-4-0314, gpt-4-0613에 질문을 던져보면서 gpt-4가 이들에 대한 사전 지식을 갖고 있지 않음을 검증하였다.
후보 문서는 각 질문에 대해 구글 검색을 사용하여 20개의 문서를 선정하였다. 이 문서들의 관련성은 수동으로 라벨링하였으며, 관련 없음(0), 부분 관련(1), 관련 있음(2)과 같이 부여하였다.
6. Experimental Results of LLMs
6.1. Implementation and Metrics
각 벤치마크 데이터셋에서 BM25로 검색한 top-100 개의 문서에 대해 재정렬을 수행한다. nDCG로 이를 평가한다.
앞서 언급한 슬라이딩 윈도우 방식을 사용하였고, window size=20, step size=10을 사용하였다.
NovelEval에서는 20개의 후보 문서를 무작위 순서로 섞었고, ChatGPT, GPT-4의 순열 생성으로 이들을 재정렬하였다.
6.2. Results on Benchmarks
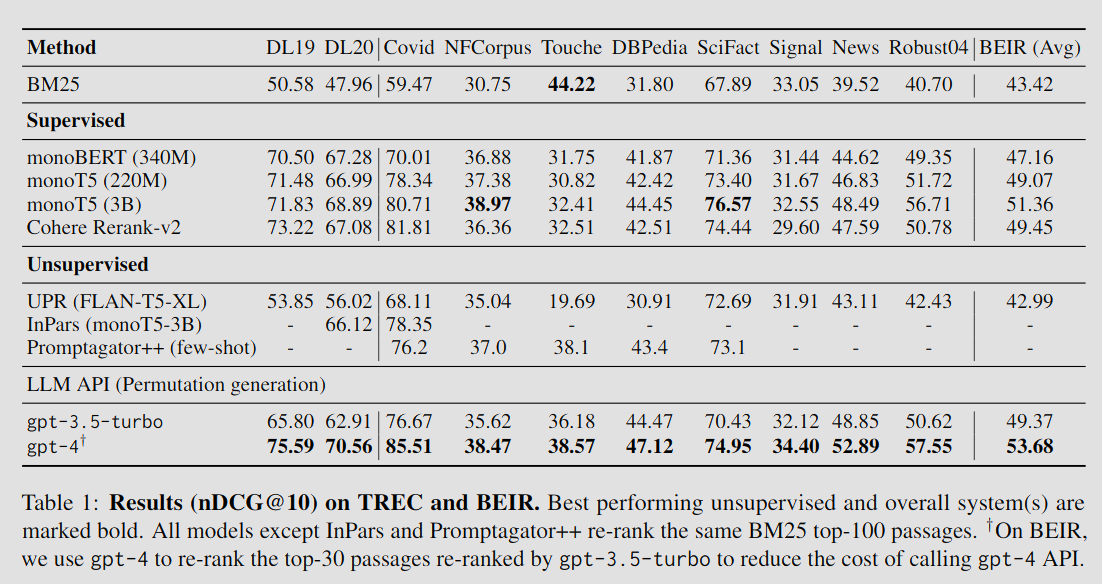
Table 1은 TREC, BEIR에 대한 결과를 보여준다.
- GPT-4가 두 데이터셋 모두에서 우수한 성능을 보여준다.
- ChatGPT(gpt-3.5-turbo) 역시 BEIR에서 지도학습 베이스라인들을 뛰어넘었다.
- BEIR 실험에서는 비용 절약을 위해 ChatGPT가 우선 재정렬한 상위 30개 문서에 대해서만 GPT- 4로 최종 재정렬을 수행하였다. 이 방식은 GPT-4만 단독으로 사용해 재정렬했을 때의 비용의 1/5만으로도 좋은 결과를 달성하였다.
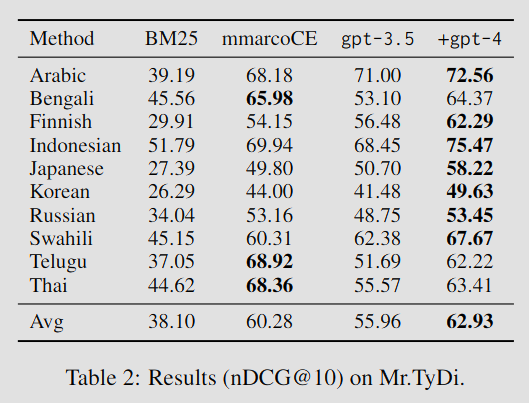
Table 2는 Mr.Tydi에 대한 결과를 보여준다.
- GPT-4는 대부분의 언어에서 지도학습 모델을 능가한다. 하지만 벵골어, 텔루구어와 같은 일부 언어에서는 mmarcoCE보다 성능이 떨어지는 경우도 발생하였다. 그 이유로는 이러한 언어들에 대한 GPT-4의 언어 모델링 능력이 상대적으로 약하고, 저자원 언어 텍스트가 영어보다 더 많은 토큰을 소비하여, 문서가 과도하게 잘려나갔기 때문일 수 있다.
- ChatGPT 역시 대부분의 언어에서 지도학습 모델과 비슷한 수준을 보였으나, 모든 언어에서 일관되게 GPT-4에는 뒤쳐졌다.
6.3. Results on NovelEval
Table 3은 NovelEval에 대한 결과를 보여준다.
- GPT-4가 역시 가장 좋은 성능을 보인다.
- ChatGPT는 monoBERT와 비슷한 수준의 성능을 달성하였다.
- 이러한 결과는 LLM이 친숙하지 않은 정보를 효과적으로 재정렬할 수 있는 능력을 보유하고 있음을 시사한다.
6.4. Compare with Different Instructions
순열 생성 방식(PG), 질문 생성(QG), 관련성 생성(RG) 방식을 TREC 데이터셋으로 비교 평가하였다.
또한 OpenAI API에서 제공하는 4개의 LLM(curie-001, davinci-003, gpt-3.5-turbo, gpt-4)의 성능도 함께 비교하였다.
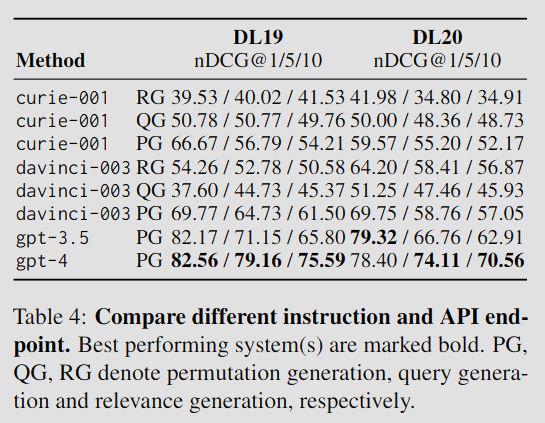
Table 4는 각 API별, 지시 방법별 결과를 보여준다.
- PG 방식이 QG, RG보다 더 우수한 성능을 보여준다.
- PG가 다른 방식들에 비해 nDCG@1 정확도가 현저히 높다. LLM은 PG를 통해 여러 문서들을 명시적으로 비교할 수 있으며, 이를 통해 문서 간의 미묘한 차이를 구별할 수 있다.
- LLM은 여러 문서를 함께 읽음으로써 질문과 문서에 대한 보다 포괄적인 이해를 얻게 되며, 이는 재정렬 능력 향상으로 이어진다.
- Davinci 모델이 ChatGPT 보다 성능이 떨어지는데, 이는 davinci 모델의 생성 안정성이 GPT-4에 미치지 못하기 때문일 수 있다.
6.5. Ablation Study on TREC
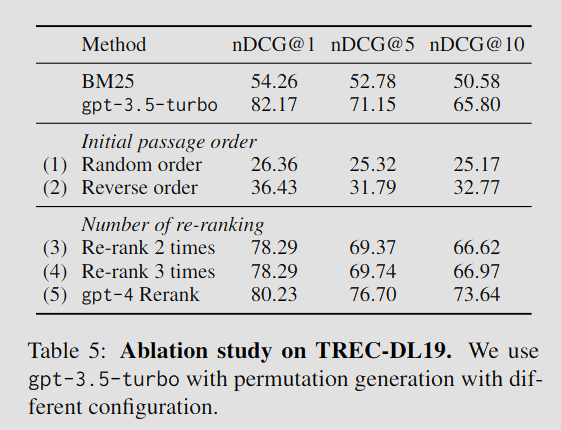
Initial Passage Order
기본적인 구현에서 BM25의 랭킹 결과를 초기 순서로 활용했다면, 무작위 순서와 역순 방식을 추가적으로 실험하였다.
실험 결과, 모델의 성능은 초기 문서 순서에 매우 민감한 것으로 나타났다.
기본적인 구현 방식이 가장 높은 성능을 달성한 이유는, BM25가 비교적 좋은 초기 순서를 제공하기 때문에, 단 한번의 슬라이딩 윈도우 재정렬만으로도 좋은 결과를 얻을 수 있기 때문이다.
Number of Re-ranking
슬라이딩 윈도우 횟수가 미치는 영향도 실험하였다.
실험 결과, 재정렬 횟수를 늘리면 nDCG@10이 향상될 수 있지만, 최상위 문서 랭킹 성능(nDCG@1)은 오히려 저하되는 현상이 나타났다.
한편, GPT-4를 사용하여 상위 30개 문서를 다시 재정렬했을 때(gpt-4 Rerank)는 큰 성능 향상을 보였다.
6.6. Results of LLMs beyond ChatGPT
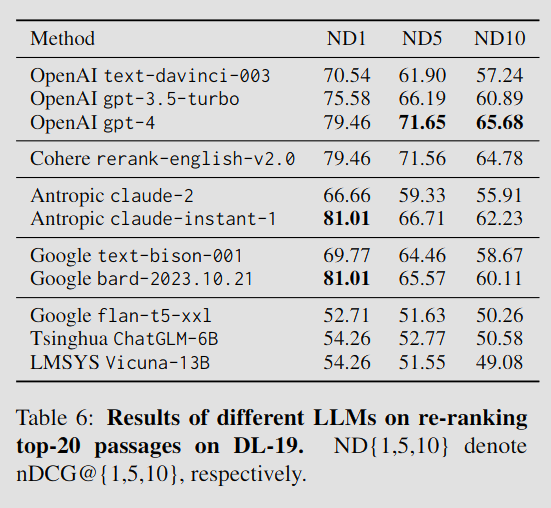
TREC DL-19에 대해 여타 LLM들의 능력을 평가하였다.
- 상용 LLM: GPT-4가 가장 높은 성능을 보여주었으며, Cohere rerank 역시 좋은 결과를 보였으나, 이는 지도 학습을 거친 모델이다. 한편 구글과 앤트로픽의 모델들은 ChatGPT에 뒤쳐지는 결과를 보였다.
- 오픈소스 LLM: ChatGPT와 비교하여 상당한 격차를 보였다. → 20개의 문서 순열을 생성하는 과업은 기존 오픈소스 모델들에게는 어려운 과제였을 것이다.
7. Experimental Results of Specialization
특화 모델로는 cross-encoder 기반 DeBERTa-v3-Large 모델, 관련성 생성을 사용하는 LLaMA-7B 모델을 사용하였다.
비교를 위해 원본 MS MARCO 라벨을 사용하여 훈련된 특화 모델(지도학습)도 함께 평가하였다.
7.1. Results on Benchmarks
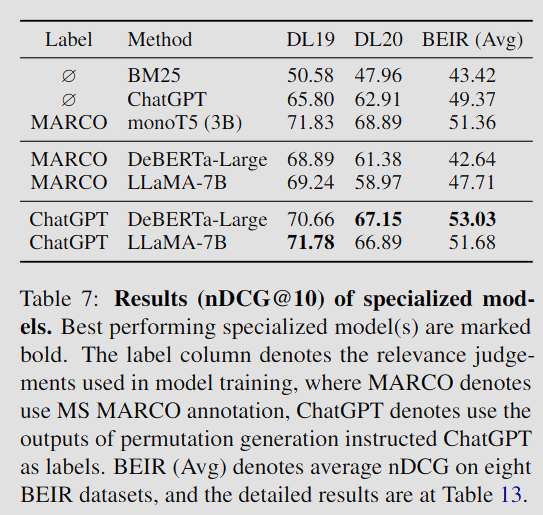
Table 7은 특화 모델들의 NDCG@10 을 보여준다.
순열 증류 방식은 TREC 및 BEIR 모두에서 지도학습 방식을 능가하였다. 이는 ChatGPT의 관련성 판단이 기존 MS MARCO 라벨보다 더 포괄적이기 때문일 수 있다.
특화된 DeBERTa 모델은 BEIR에서 기존 SOTA 모델이었던 monoT5(3B)를 능가하였다.
특화 모델은 teacher 모델인 ChatGPT도 능가하였다. 이는 특화 모델의 재정렬 안정성이 ChatGPT보다 뛰어나기 때문인 것으로 보인다.
7.2. Analysis on Model Size and Data Size
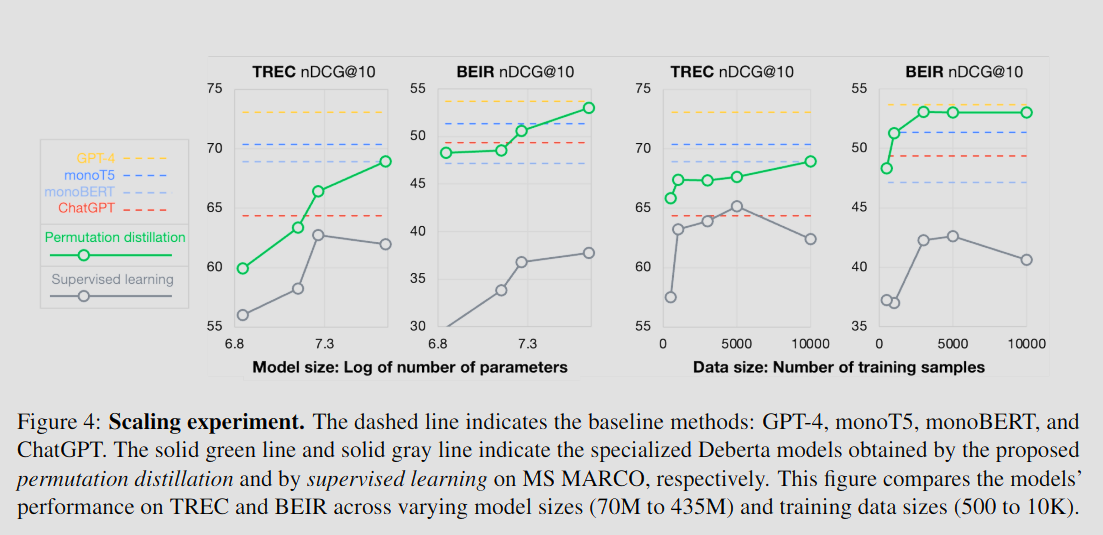
- 순열 증류 모델은 다양한 모델 크기, 다양한 데이터 크기에 걸쳐 우수한 성능을 달성하였다.
- 특히, 단 1K 개의 질문을 학습한 것으로도, monoT5를 능가하였다 (BEIR).
- 학습 데이터의 양을 늘리는 것보다 파라미터 크기를 늘리는 것이 랭킹 성능 향상에 더 큰 영향을 미친다.
- 지도 학습 모델의 성능은 불안정하다. 이는 MS MARCO 라벨에 존재하는 노이즈가 과적합 문제를 일으키기 때문일 수 있다.
8. Conclusion
- LLM의 능력을 활용하기 위해 순열 생성 기법을 도입하였다.
- 3가지 벤치마크 실험을 통해 ChatGPT와 GPT-4의 문서 재정렬 능력을 입증하였다.
- 친숙하지 않은 지식에 대해 LLM을 더욱 엄격하게 검증하기 위해 NovelEval이라는 새로운 평가셋을 도입하였다.
- 기존의 지도학습 방식 대비 우수한 효과와 효율성을 보여주는 순열 증류 방법을 제안하였다.
