RAG
1.[Paper Review] RankGPT(2024): Is ChagGPT good at search? Investigating Large Language Models as Re-Ranking Agents

LLM은 다양한 태스크에서 뛰어난 제로샷 생성 능력을 보여왔지만, 기존 연구들은 LLM을 IR에 적용할 때 재정렬보다는 텍스트 생성 능력을 활용하는 데 그쳤다.본 논문은 ChatGPT, GPT-4와 같은 LLM의 재정렬 능력을 조사하였고, 실험 결과 적절한 지시를 받은
2026년 3월 8일
2.[Paper Review] Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting
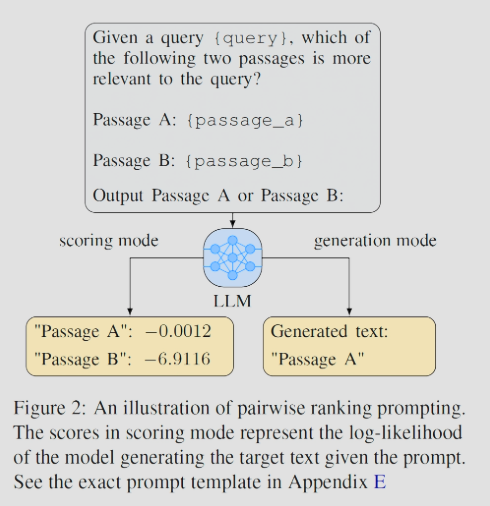
리랭킹 task에서 기존 pointwise 및 listwise 방식은 LLM에게 지나치게 어려운 task였다.본 연구에서는 이러한 부담을 경감하기 위해 한 쌍의 문서만을 비교하는 PRP(Pairwise Ranking Prompting) 기법을 제안한다.중소형 오픈소스
2026년 3월 8일
3.[Paper Review] Zhang et al.(2025)_REARANK: Reasoning Re-ranking Agent via Reinforcement Learning
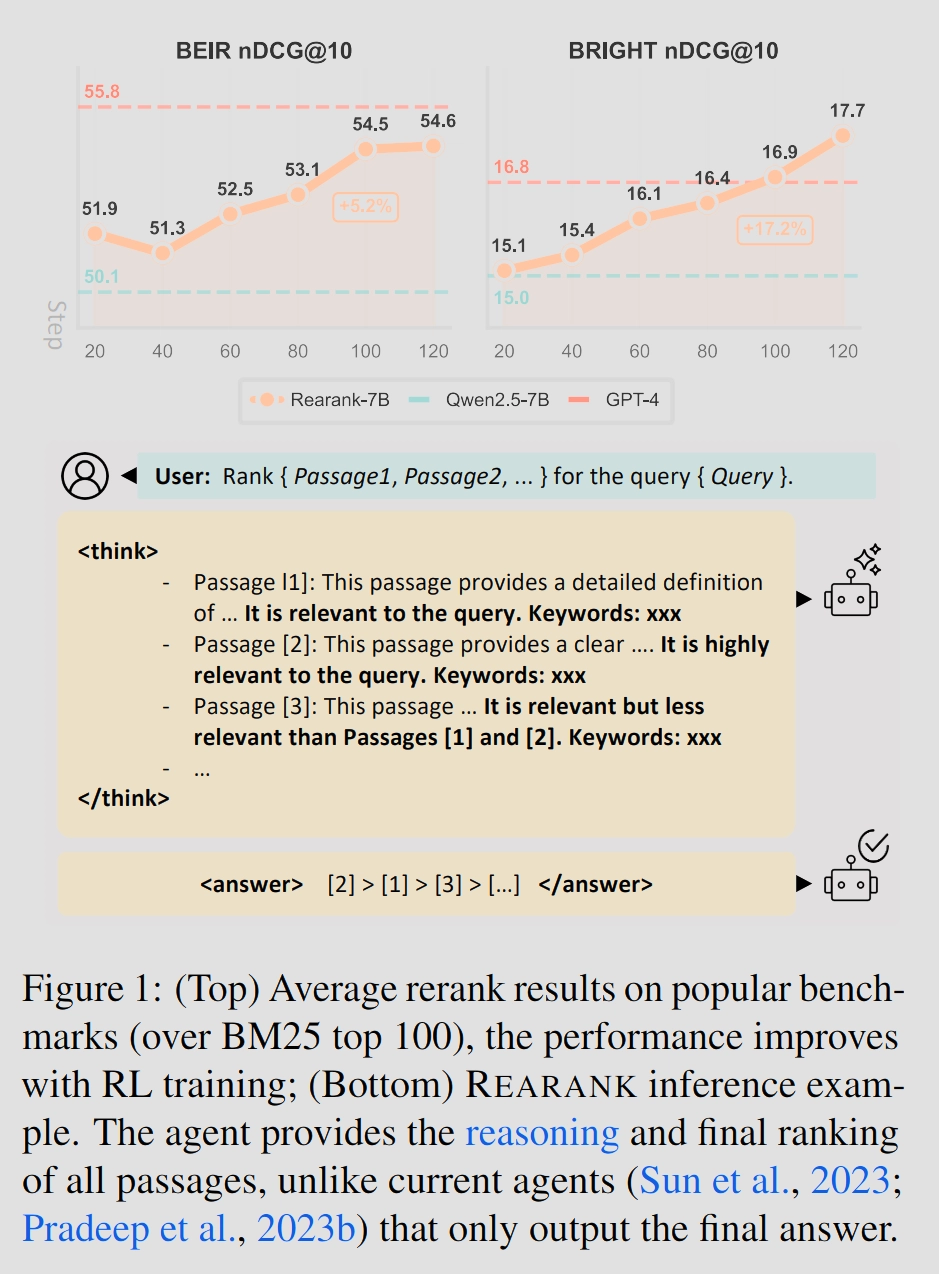
최근 연구들은 리랭킹 작업에 LLM (reranking agents)으로 점수가 아니라 직접적으로 아웃풋을 출력하는 방식을 활용함.그러나 다음과 같은 도전 과제가 남아있음.LLM 자체는 랭킹이라는 목적에 최적화되어 있지 않음.또한, zero-shot 방식은 순위를 매기
2026년 4월 4일