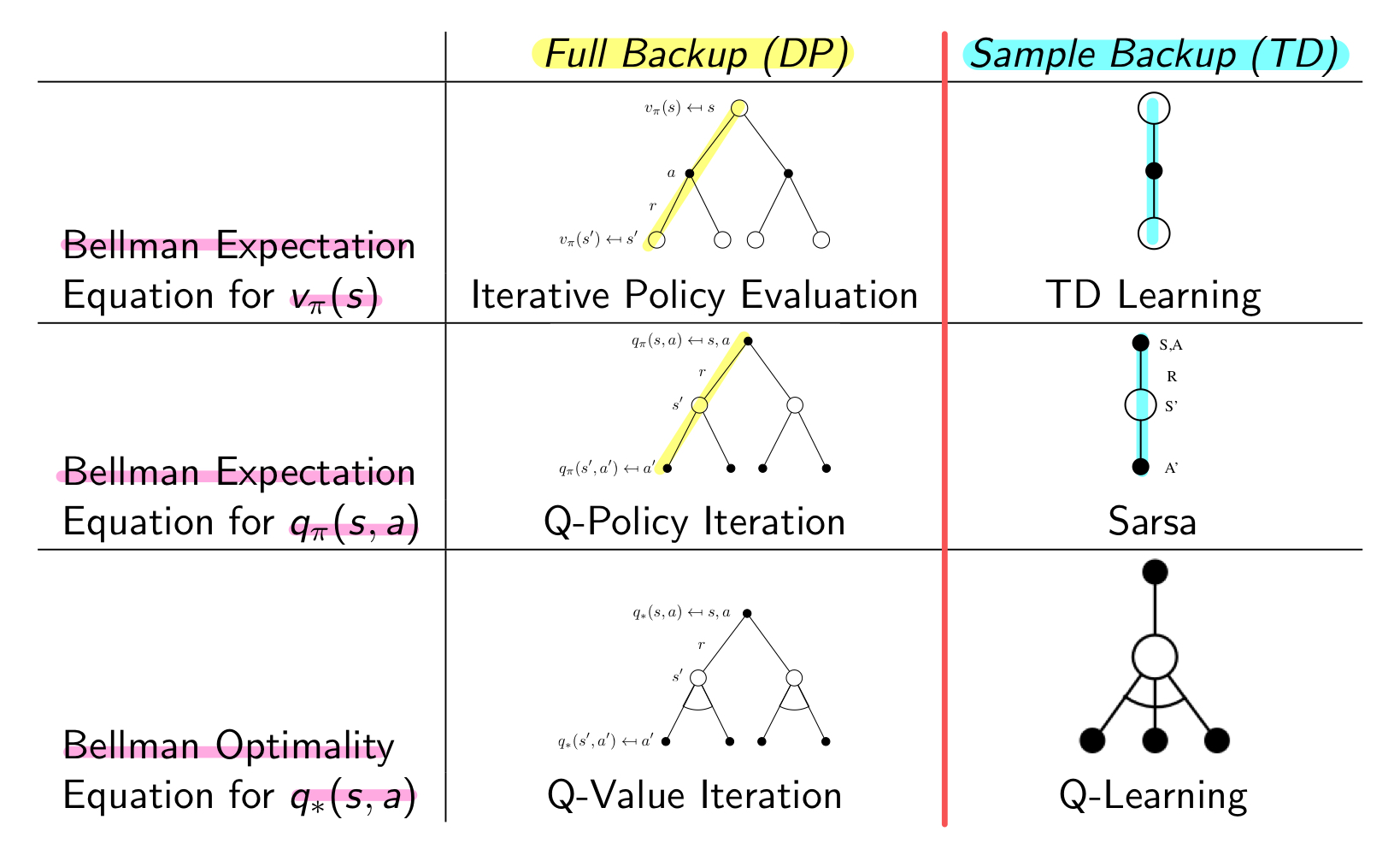
이전 게시물에서 Model Free한 Prediction을 어떻게 하는지, 즉 주어진 Policy에 대한 value function을 구하고 평가하는 방법에 대해 알아보았다. 그 과정에서 Monte-Carlo와 Temporal-Difference 방법에 대해 알아보았다.
이번에 알아볼 Model Free Control에서도 동일한 개념이 사용될 것이다. 다만, Control 과정이기 때문에 Preidction을 한 뒤에 Policy를 어떻게 개선시키는지에 대해 알아볼 것이다. 이 과정도 Model Free이기 때문에 MDP에 대한 정보 없이, agent가 경험적으로 배우게 될 것이다.
본격적으로 시작하기 전에 Off-Policy Learning과 On-Policy Learning에 대해 알아보자.
On Policy
- 주어진 Policy π를 따라 sampling 하면서 Policy π를 update하는 것
Off Policy
- Policy μ를 따라 sampling 하면서 Policy π를 update하는 것
On-Policy Monte-Carlo control
Monte Carlo로 Control 하기 이전에 처음에 DP에서 어떻게 Policy Iteration을 진행했는지 돌이켜보자.
Policy Evaluation : 주어진 policy에 대해서 vπ 계산 (V=vπ)
Policy Improvement : 계산된 vπ에 대해 greedy한 방식으로 개선된 policy π′ 산출 (Greedy Improvement)
Exploration
Monte Carlo에서도 이런 방식의 Policy Evaluation과 Policy Improvement가 가능할까?
Problem 1. V(s)를 통해 Policy Improvement를 하기 위해서는 Pss′a과 같이 MDP의 model을 알아야한다.
π′(s) = a∈AargmaxRSa + Pss′aV(s′)
Problem 2. Monte Carlo는 Sampling을 통해 value function의 기댓값을 구하는 방법이기 때문에 모든 state, action에 대한 값을 볼 수 없으므로 sampling한 데이터에 대한 greedy한 방법으로 최적의 policy를 구할 수 없다.
Solution 1
첫번째 문제를 해결하기 위해 우리는 State-Value function V(s) 대신 Action-Value function Q(s,a) 를 사용한다. Q(s,a)를 구하고, 그에 대한 argmax인 a가 곧 policy이기 때문에 Model Free하게 Evalution을 할 수 있다.
π′(s) = a∈AargmaxQ(s,a)
Solution 2
두번째 문제를 해결하기 위한 가장 간단하고 효과적인 방법은 greedy하게 가지 않고, 일정 확률(ϵ)로 m개의 action 중에 random하게 선택하는 것이다.
π(a∣s) = {ϵ/m + 1 − ϵ if a∗=argmaxa∈AQ(s,a)ϵ/m otherwise
따라서 Monte Carlo Policy Iteration는 다음과 같은 방법으로 진행된다.
매 Episode마다,
Policy Evaluation : Monte Carlo Policy Evaluation (Q=qπ)
Policy Improvement : ϵ 확률로 다른 policy 선택하여 탐색 (ϵ-greedy policy improvement)
그런데 여기서 하나 더 추가할 내용이 있다. 이전에 DP에서도 말했지만, Evaluation 과정에서 주어진 policy에 대한 value function이 수렴할때까지 반복할 필요가 없다. 몇번만 iteration을 진행해도, 어느정도 improvement를 위한 정보가 수집됐을 것이다.
따라서 Episode를 여러번 진행해서 Monte Carlo Policy Evaluation을 할 필요 없이, 매 Episode마다 지나온 정보를 통해 policy improvement를 하는 편이 훨씬 효율적이다. 즉, 끝까지 갈 필요 없이 가장 최근에 estimate된 value function으로 바로 policy update를 하면 된다!
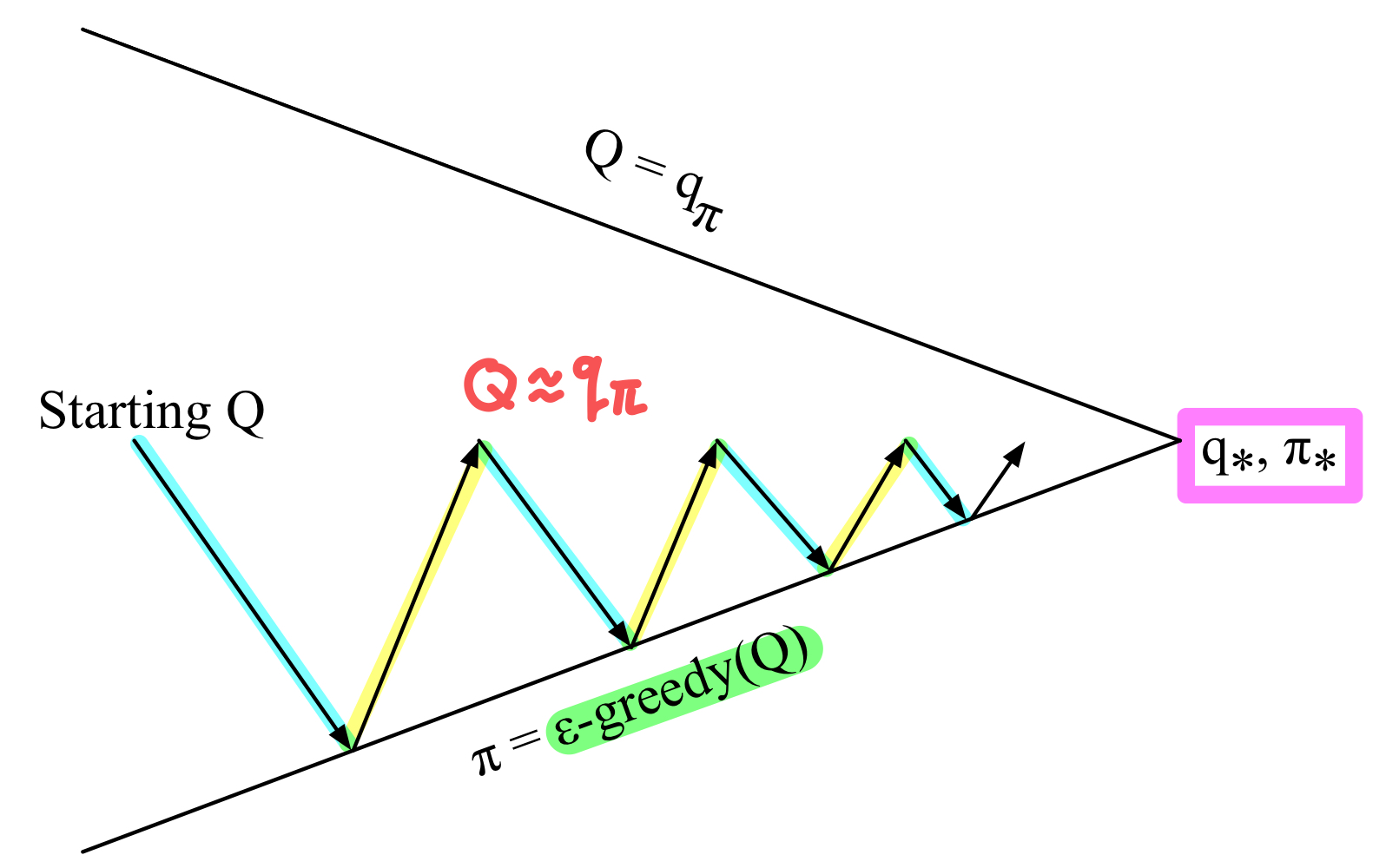
매 Episode마다,
Policy Evaluation : Monte Carlo Policy Evaluation (Q≈qπ)
Policy Improvement : ϵ 확률로 다른 policy 선택하여 탐색 (ϵ-greedy policy improvement)
GLIE (Greedy in the Limit with Infinite Exploration)
GLIE를 해석해보면 얼추, 무한한 탐색과 greedy하게 탐색, 두가지 조건이 있는 것을 볼 수 있다.
-
모든 State-Action pair가 무한히 여러번 탐색되어야한다.
limk→∞Nk(s,a) = ∞
-
Greedy한 Policy로 수렴되어야한다.
limk→∞πk(a∣s) = 1(a=argmaxa′∈AQk(s,a′))
대표적인 예시로, ϵ-greedy 방법에서 ϵ이 점점 0으로 수렴한다면 (ϵk =k1) GLIE 조건을 만족한다.
GLIE Monte Carlo Control
-
Policy π를 따른 K 번째 Episode에 대해 : {S1,A1,R2,...,ST}∼π
-
Evaluation (모든 St, At에 대해 Q(St,At)를 update)
- Count : N(St,At) ← N(St,At)+1
- Update Value Function : Q(St,At) ← Q(St,At)+N(St,At)1(Gt−A(St,At))
-
Improvement (Evaluate된 action-value function에 따라 Policy Update)
- ϵ ← 1/k
- π ←ϵ−greedy(Q)
On-Policy Temporal-Difference Learning
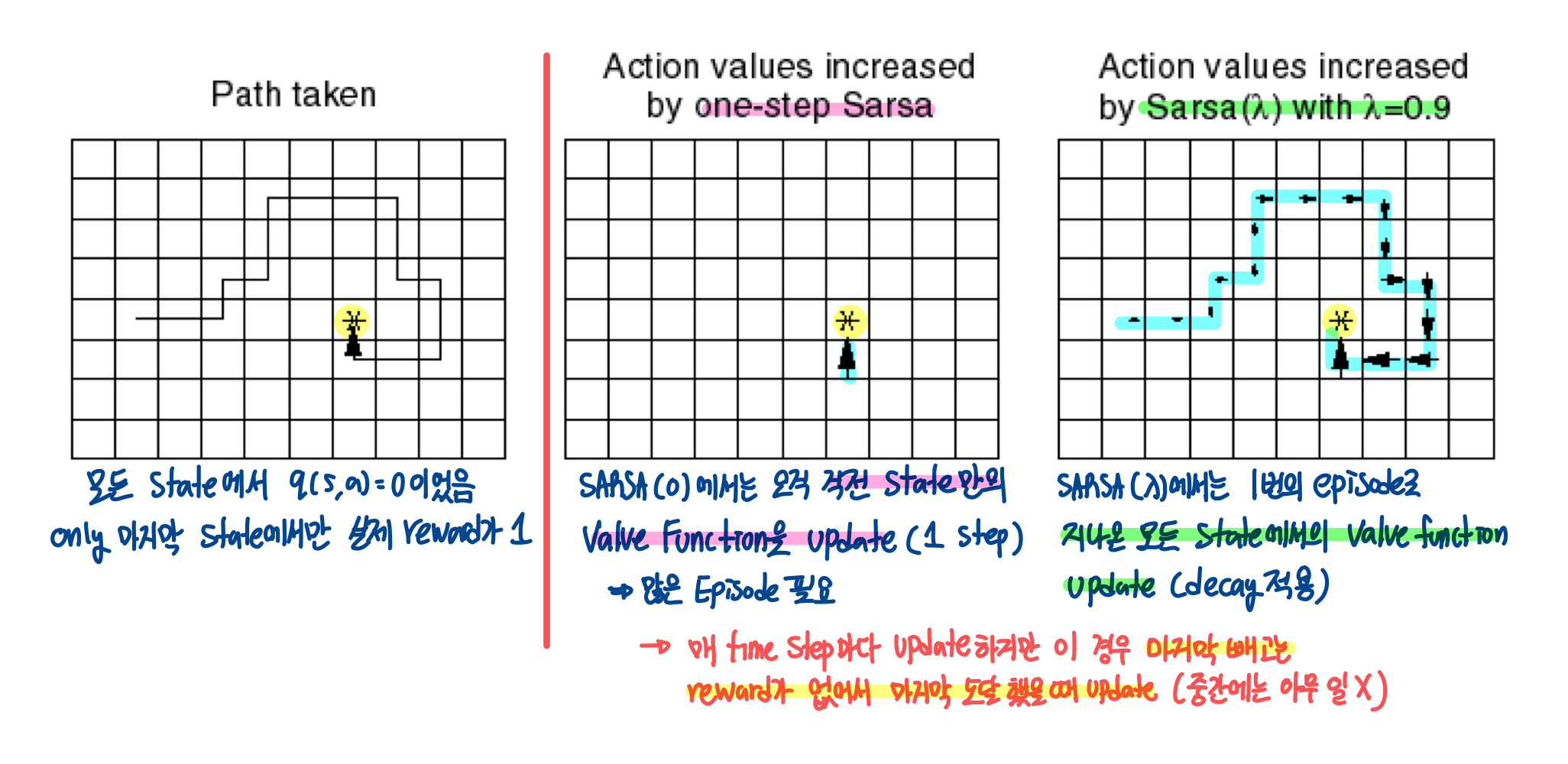
이전 게시물에서도 봤지만, TD는 MC에 비해 여러 장점이 있다. 매 Time Step마다 Online하게 update를 할 수 있고, variance도 상대적으로 작으며, 완전한 sequence가 아니어도 학습을 진행할 수 있다.
Sarsa
위에서 봤던 On-Policy MC에 TD를 대입해보자. MC의 경우에는 한 Episode에 대해 모든 state, action에 대해 update를 했다면, TD에서는 한 timestep마다의 Q(s,a)에 대해 state, action을 update할 것이다.
따라서 TD를 적용하면, Policy Evaluation 과정에서 차이가 생기게 되고, 이 방법을 SARSA라고 한다.
Q(S,A) ← Q(S,A)+α(R+γQ(S′,A′)−Q(S,A))
풀어서 설명해보면, 현재 State-Action Value Function Q(S,A)에서, 다음 step에서의 value function Q(S′,A′)을 반영한 Target R+γQ(S′,A′)과의 error 방향으로 update를 진행하는 것이다.
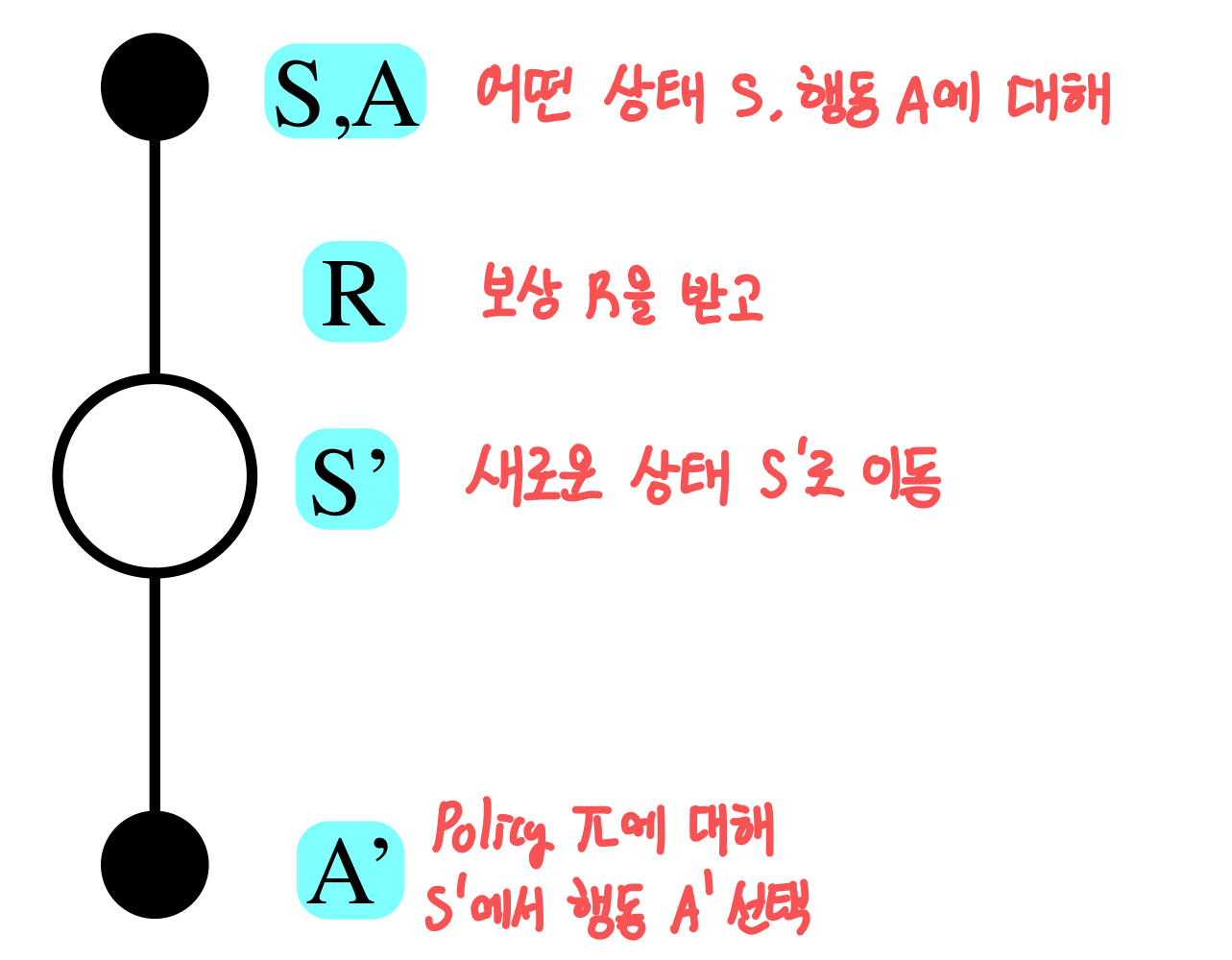
정리해보면 다음과 같다. Monte-Carlo와 유사하지만, 매 Time-Step마다 iteration을 반복하고, Sarsa를 사용해서 policy evaluation을 진행한다. Policy Improvement는 동일하게 ϵ-greedy 방식을 사용한다.
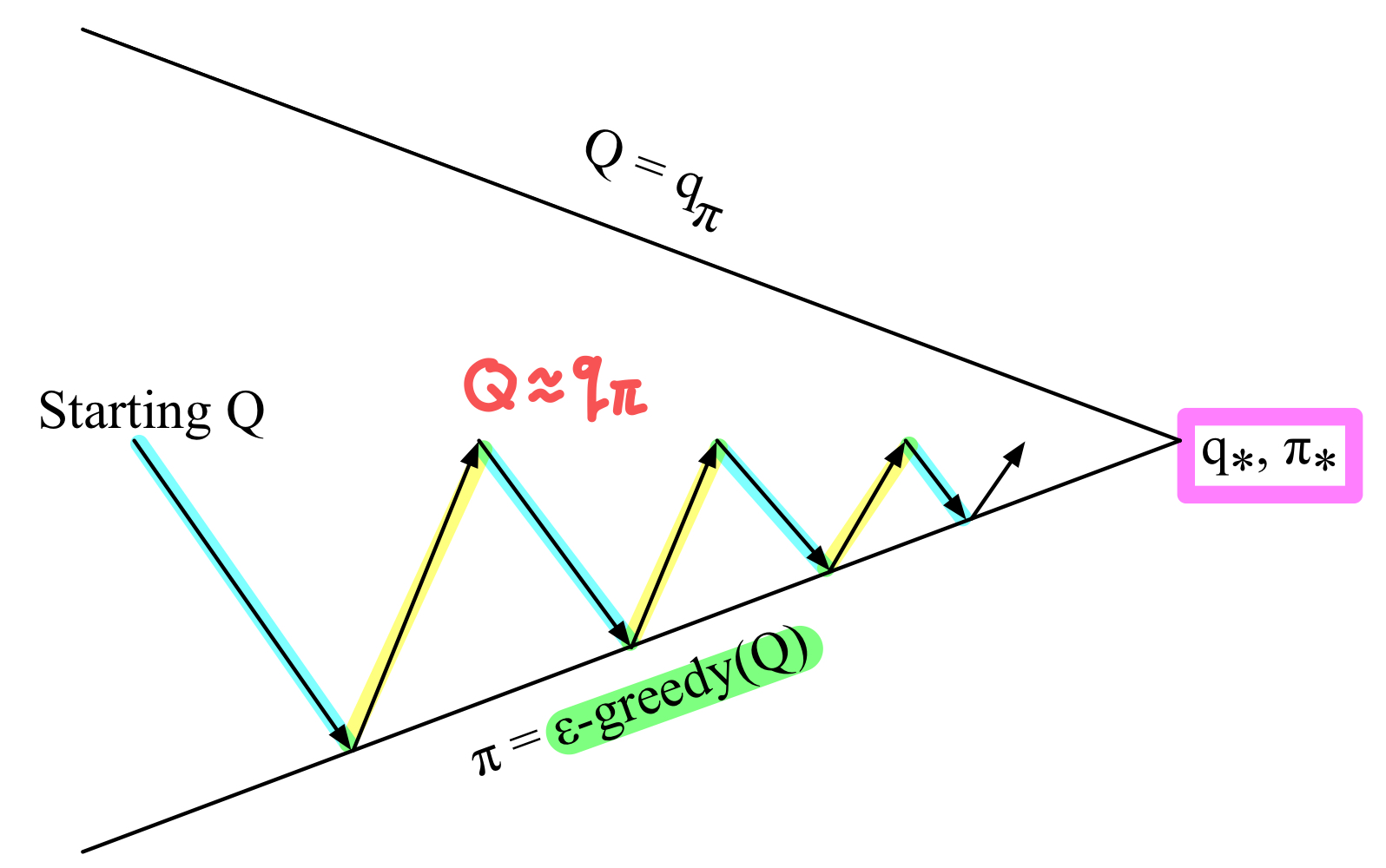
매 Time-Step마다,
Policy Evaluation : Sarsa Policy Evaluation (Q≈qπ)
Policy Improvement : ϵ 확률로 다른 policy 선택하여 탐색 (ϵ-greedy policy improvement)
Sarsa Algorithm for On-Policy Control
이 내용을 algorithm으로 풀면 다음과 같다.

읽어보면 어렵지는 않다. 매 Episode의 각 Step의 S, A마다 R, S′, A′을 구하고 이를 바탕으로 Q(S,A)를 update하는 것이다.
Sarsa(λ)
n-Step Sarsa
이전에 TD(λ)에서 봤던 것처럼 Sarsa를 통한 Policy Evaluation로 여러 step을 반영해서 할 수 있을 것이다.
n=1 : qt(1) = Rt+1 + γQ(St+1)n=2 : qt(2) = Rt+1 + γRt+2 +γ2Q(St+2)n=∞ : qt(∞) = Rt+1 + γRt+1 + ... + γT−1RT (Monte−Carlo)
이를 통해 n-step에 대한 Q-return값을 얻을 수 있다.
qt(n) = Rt+1 + γRt+2 + ... + γn−1Rt+n + γnQ(St+n)
이렇게 estimate한 n-step뒤의 qt(n)을 target으로 하는 Sarsa Update 식을 쓸 수 있다!!
Q(St,At) ← Q(St,At) + α(qt(n)−Q(St,At))
Forward View Sarsa(λ)
Sarsa(λ)도 이전에 봤던 TD(λ)와 마찬가지로 Forward View와 Backward View로 설명할 수 있다.
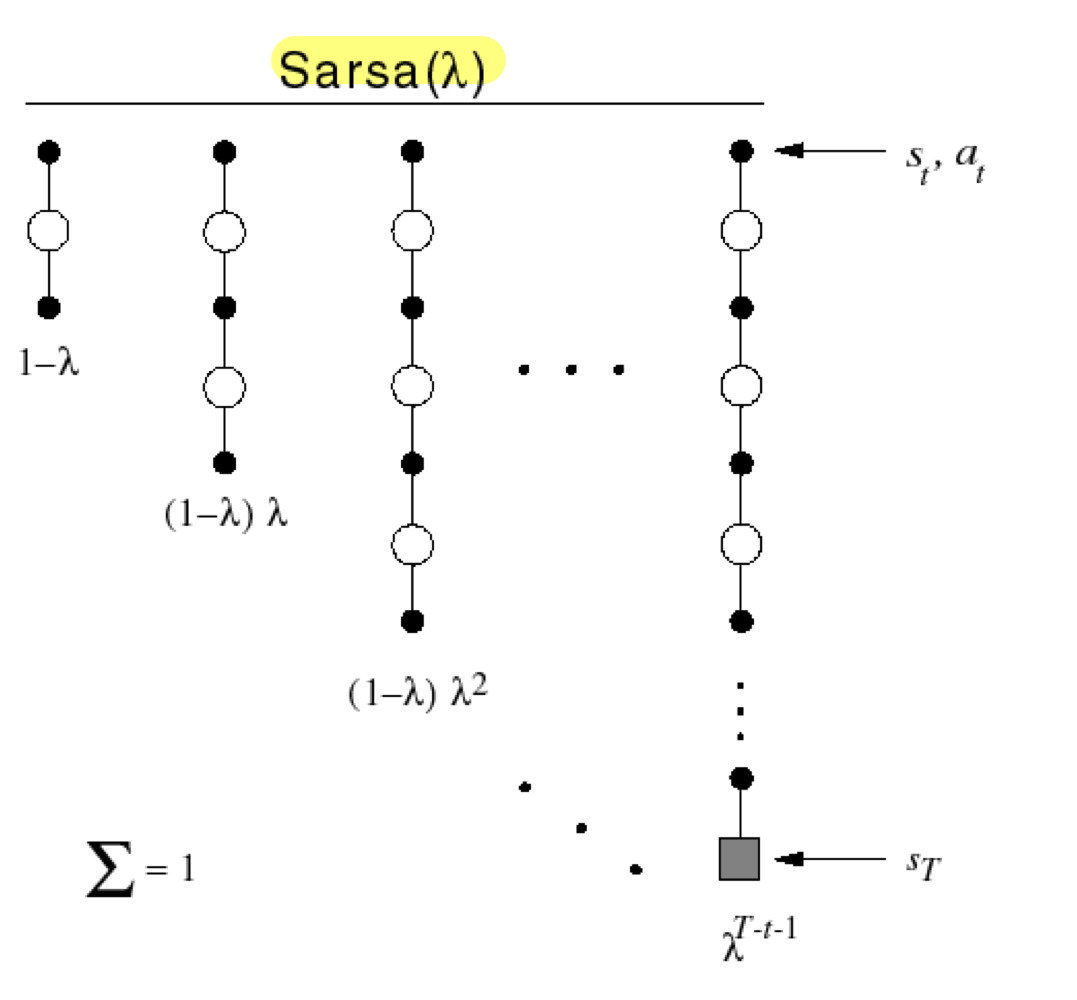
모든 n번째 step에서의 reward qt(n)를 기하 가중평균 한 qλ를 Target으로 하는 Sarsa이다. 식으로 표현하면 다음과 같다.
qλ = (1−λ)n=1∑∞λn−1qt(n) Q(St,At) ← Q(St,At) + α(qtλ − Q(St,At))
말로 풀어보면, 서로 다른 time scale에서 bootstrap한 value function qt들을 사용하여 Q(S,A)를 update하는 것이다. 그렇지만, Forward View Sarsa도 TD와 마찬가지로 qtλ를 구하기 위해 Episode가 끝날때까지 기다려야한다는 단점이 있다.
Backward View Sarsa(λ)
Backward View Sarsa(λ)에서도 Eligibility Trace의 개념이 적용된다. 이전 게시물에도 있지만, 간단하게 요약해보면 어떤 결과가 나오는데, 어떤 state, action이 얼마나 영향을 끼쳤는지를 빈도수와 최신성을 모두 고려하여 판단하는 것이다.
E0(s,a) = 0 Et(s,a) = γλEt−1(s,a) + 1(St=s, At=a)
Eligibility Trace는 online한 update에서 사용되기 떄문에 모든 state와 action에 대해서 Q(S,A)를 update할 수 있다.
TD−error : δt = Rt+1 +γQ(St+1, At+1) − Q(St, At) Q(s,a) ← Q(s,a) + αδtEt(s,a)
Sarsa(λ) Algorithm

Off-Policy Learning
지금까지는 On-Policy Learning에 대해 살펴보았다. On-Policy에서는 π(a∣s)를 학습시키기 위해 π(a∣s)를 따랐다면, Off-Policy에서는 π(a∣s)를 학습시키기 위해 μ(a∣s)라는 policy를 따른다.
이 방법이 중요한 이유는, 다른 Agent 혹은 사람의 행동으로부터 학습을 할 수 있다는 것이고, 다양한 policy를 탐색하면서 greedy하게 optimal한 policy를 찾아낼 수 있기 때문이다. 또한, 이전의 policy(π1,π2,...πt−1)를 재평가해서 학습에 사용할 수 있다. (아까 이렇게 했었는데 다르게 했으면 어땠을까?? 가 가능함 )
Importance Sampling
Importance Sampling은 효율적으로 기댓값을 추정하기 위한 방법으로, off-policy contrl이 optimal policy를 학습하는데 사용된다.
기댓값을 계산하고자하는 확률분포 P(X)를 알고 있지만, 샘플을 생성하기 어려울 경우, 상대적으로 sample 생성이 쉬운 Q(S)에서 생성된 sample을 통해 P(X)의 기댓값을 계산하는 것이다.
즉, 현재 알고자하는 데이터의 분포 P(X)에서의 Expectation을 Q(S)라는 분포에서의 sampling을 통해 추정하는 것 같다.
EX∼P[f(X)] = ∑P(X)f(X) = ∑Q(X)Q(X)P(X)f(X)=EX∼Q[Q(X)P(X)f(X)]
여기서 f(X)는 학습하고자 하는 Value Function이라고 이해하면 된다. 이 과정을 거치는 이유에 대해서는 추가적인 공부가 필요할 것 같다.
Importance Sampling for Off-Policy Monte-Carlo
Monte Carlo에서 Importance Sampling은 μ에서 생성된 reward를 통해 π를 evaluate한다.
위에서 본 식에 대입해보면 Episode에 대해서 Policy μ와 π 사이의 유사도(Importance Sampling Ratio)를 return Gt에 반영하여 Gtπ/μ를 구한다.
Gtπ/μ = μ(At,St)π(At∣St)μ(At+1,St+1)π(At+1∣St+1)...μ(AT,ST)π(AT∣ST)Gt
이렇게 수정된 return을 target을 향해 update를 진행하게 된다.
V(St) ← V(St) + α(Gtπ/μ − V(St))
이러한 방식은 딱 봐도 굉장히 문제점이 많은데, 모든 step에 대해서 policy 사이의 Ratio를 고려하기 때문에 Variance가 극단적으로 증가한다.
Importance Sampling for Off-Policy TD
TD에서도 마찬가지로 μ에서 생성된 reward를 통해 π를 evaluate한다. 그대신 MC의 reward Gt 대신 TD reward인 R+γV(S′)에 유사도(Importance Sampling Ratio)를 1 Step 단위로 반영한다.
V(St) ← V(St) + α(μ(At∣St)π(At∣St)(Rt+1+γV(St+1)) − V(St))
TD는 Episode내 모든 policy에 대해서 ratio를 반영하는 것이 아니라, 1 step 단위로 반영하기 때문에 MC에 비해 Variance가 낮다. 사실상 의미가 없다고 보면 된다.
Q-Learning (SARSAMAX)
Importance Sampling을 사용하지 않고 Off-Policy를 적용하기 위해 등장한 개념이 Q-Learnig이다.
Q-Learning에서는 action value function Q(s,a)를 기반으로 학습하며 2개의 Policy가 사용되고 각각 역할이 다르다.
Behaviour Policy μ
- At+1 ∼ μ(⋅∣St)
- 다음 action을 선택하는 실제 policy
- ϵ-greedy
Target(Alternative) Policy π
- A′ ∼ π(⋅∣St)
- Reward를 구하고 Update를 할 때에 다음 state S′에서 다음 action A′을 선택하는데 고려하는 가상의 policy
- greedy
- π(St+1) = argmaxa′Q(St+1, a′)
Q(St,At)는 Target Policy, 즉 Alternative Policy에 대한 value Rt+1 + γQ(St+1, A′)를 target으로 update된다.
Q(St, At) ← Q(St, At) + α(Rt+1 + γQ(St+1, A′) − Q(St, At))
여기서 ϵ-greedy, greedy한 Policy Evaluation을 적용하면 다음과 같이 식을 단순화 시킬 수 있다.
Rt+1 = Rt+1 = Rt+1 + γQ(St+1, A′)+ γQ(St+1, a′argmaxQ(St+1, a′))+ a′maxγQ(St+1, a′)
말로 풀어서 설명을 해보자면, A′은 Target Policy를 따르기 때문에 greedy한 action을 선택하므로 argmaxa′Q(St+1, a′))로 치환할 수 있다.
Q(S, A) ← Q(S, A) + α(R + γa′maxQ(S′, A′) − Q(S, A))
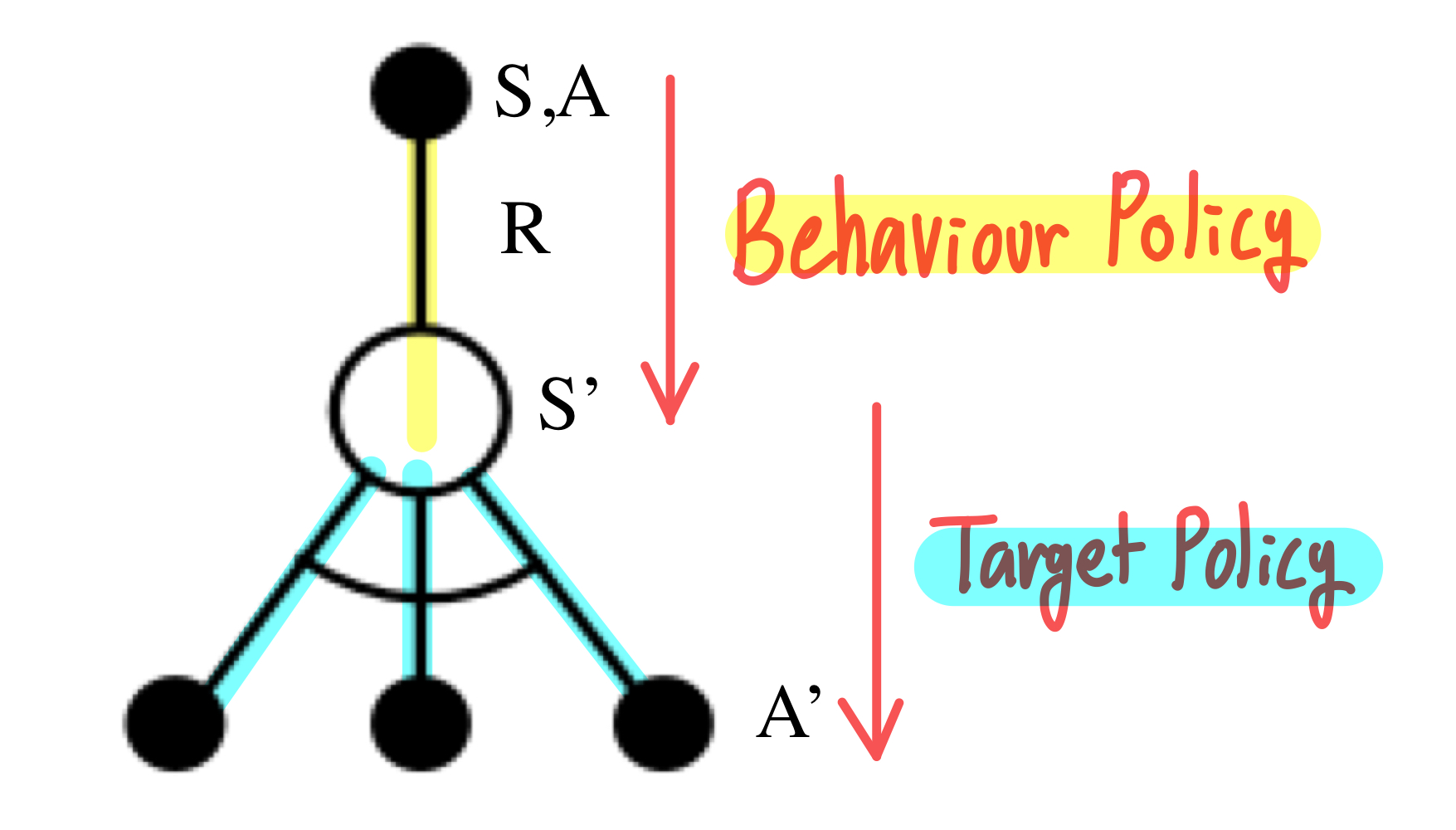
SARSA하고 거의 비슷해보이는데 무슨 차이가 있을까? SARSA에서는 정해진 policy π에 대해서 policy iteration을 하지만, Q-Learning에서는 argmax된 policy π∗를 바탕으로 policy iteration을 한다.
좀 더 단순하게 얘기하면, Q-Learning(SARSAMAX)에서는 Behaviour Policy로 다음 state를 얻고, Target Policy를 통해서 실제 Target을 구한다.
SARSA : Q(St,At) ← α(Rt+1 + γQ(St+1,At+1) − Q(St,At))) Q−Learning : Q(St,At) ← α(Rt+1 + γa′maxQ(St+1,a′) − Q(St,At)))
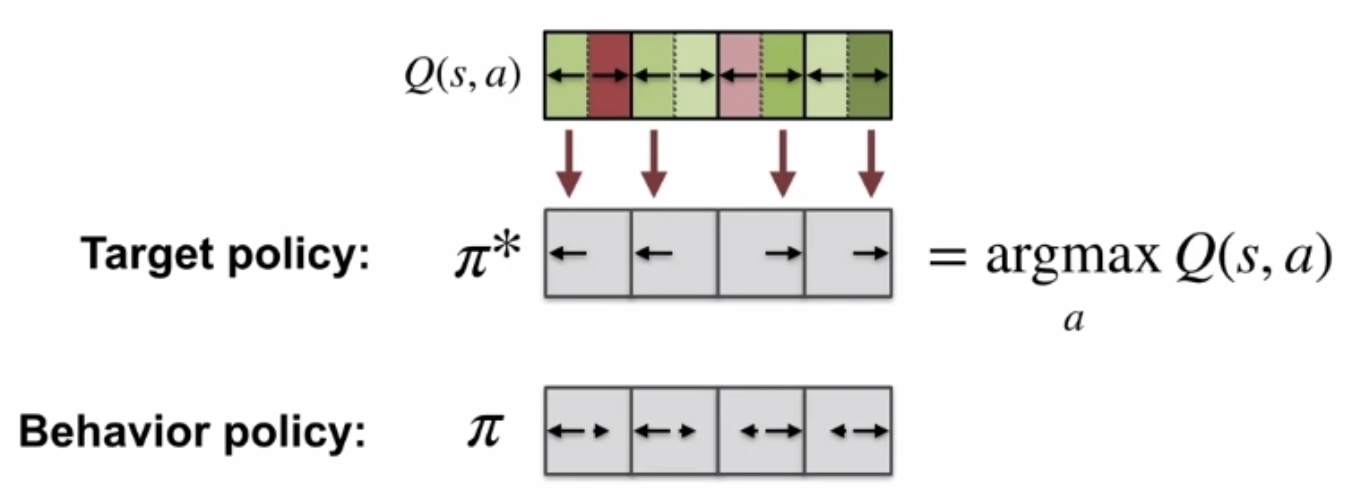
식을 조금만 직관적으로 이해해보면, SARSA는 현재 상태에서 action을 선택한 뒤에, 다음 상태에서도 동일한 policy를 통해 target을 구하지만, Q-Learning에서는 다음 상태에서 Target Policy에 따라 Optimal한 값을 target으로 update한다.
Summary